
우아한테크코스 레벨 2 과정을 거치면서, 레벨 1 과정 만큼 열정적으로 개발을 공부하고 있지 않다는 생각이 들었습니다. 미션은 계속 주어지는데, 반복되는 미션을 통해 새로운 것을 배워나가는 즐거움이 크게 느껴지지 않았습니다. 슬럼프였다고나 할까요? 리프레시가 필요했습니다. 개발에 슬럼프가 왔는데 개발로 리프레시를 한다는게 뭔가 앞 뒤가 안맞는 것 같기는 하지만, 어쨌든 제가 리프레시로 선택한 방법은 사이드 프로젝트였습니다.
왜 갑자기 사이드 프로젝트를 했어요?
왜 사이드 프로젝트였냐고요? 제가 왜 개발 공부에 흥미를 붙이게 되었는지 처음으로 돌아가 생각해 보았습니다. 전 코딩을 통해 프로그램을 만들어 나가는 일에서 재미를 느꼈었더라고요. 그런데 레벨 2 들어서 미션을 새로운 것을 배우며 만들어 나가는 것 보다는 2주마다 주어지는 과제 정도로 생각을 했었습니다. 그래서 미션과는 별개로 제가 흥미를 느낄 수 있는 개발을 하려고 했습니다.
우선은 함께 할 크루를 모으는 것이 중요했습니다. 혼자서 모든 것을 다 만들기에는 제겐 그럴만한 실력도, 시간도 부족했기 때문이었죠. 그리고 사이드 프로젝트를 통해 레벨 3에서 하게 될 팀 프로젝트를 미리 경험해보고자 하는 목적도 있었습니다. 그래서 백엔드 세 명, 프론트엔드 세 명 정도로 팀을 꾸리기로 마음을 먹었습니다.
마침 평소에 테스트 도구 같이 이런 저런 툴들을 만들어서 크루들에게 공유해주던 오리가 사이드 프로젝트에 관심을 보였고, 팀에 합류했습니다. 남은 한 명으로는 누가 있을까 하다가 데일리 같은 조에서 개발 이야기로 많은 도움을 받았는데 함께 페어를 해보지 못해서 아쉬웠던 후니에게 의견을 물었고, 후니도 흔쾌히 좋다고 해서 백엔드 팀을 완성했습니다.
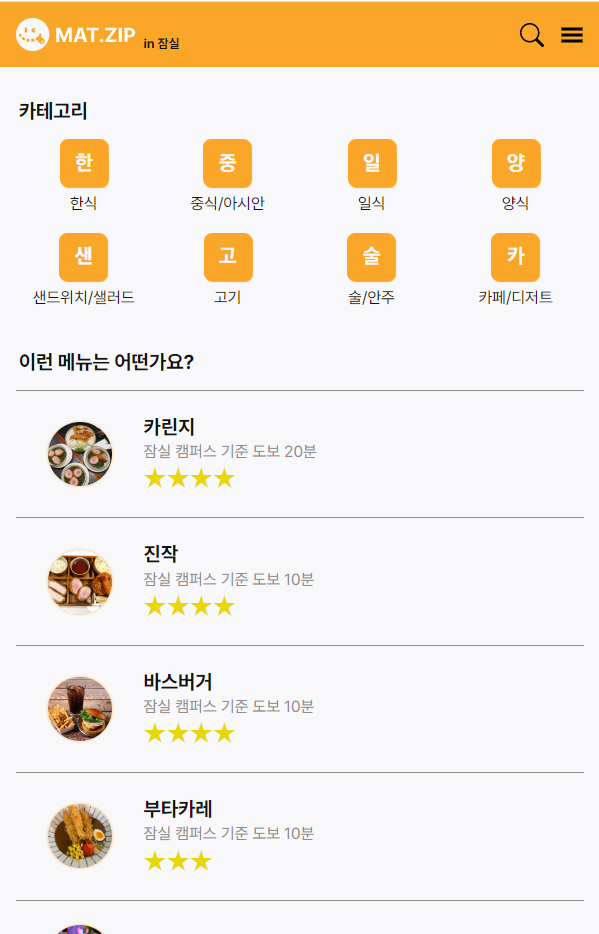
이왕 프로젝트를 하기로 한 거, 실용적인 프로젝트를 만드는 것이 개발하는 저희나 사용하는 크루들이나 윈윈이겠죠? 그래서 저희는 프로젝트 주제로 무엇이 좋을까 하다가 음식점 리뷰 플랫폼을 만드는 것으로 결정했습니다. 당시 프론트엔드 크루는 잠실, 백엔드 크루는 선릉으로 나뉘어져 등교하고 있었는데, 레벨 3가 되면 프론트와 백이 함께 팀을 이뤄서 잠실과 선릉으로 찢어지기 때문에 어떤 크루들은 근처에 어떤 식당이 있는지 전혀 모르는 상태로 등교하게 될 거라는 생각이 들었습니다. 그런데 네이버 지도나 카카오 맵을 통해 음식점을 찾자니, 네이버 지도는 광고성 글들이 너무 많고, 카카오 맵은 리뷰 수가 적어서 별점의 편차가 크고 신뢰도가 낮다는 단점이 있습니다. 그래서 크루들이 직접 이 음식점들에 대해 본인의 의견과 별점을 남긴다면, 앞으로 레벨 3에 캠퍼스가 바뀌어도 메뉴를 정하기에 큰 도움이 될 거라는 생각이 들었습니다. 아무래도 크루들의 연령대가 비슷한 만큼, 크루들이 직접 본인의 입맛으로 리뷰하는 것이 신빙성이 있지 않겠어요? 그래서 이 주제를 고르게 되었습니다
주제를 정하고 나서 프론트엔드 팀원을 모아야 했는데요, 마침 잠실 캠퍼스에는 우맛탐이라는 맛집 탐방 동아리가 있었습니다. 저희가 정한 주제와 대략적인 개요를 프론트엔드 방에 공유했더니, 맛집 탐방 동아리를 하고 있는 프론트엔드 크루 블링, 샐리, 태태로부터 함께하고 싶다는 연락이 왔습니다. 그렇게 팀 구성은 정말 순탄하게 진행되었습니다.
기술 스택은?
레벨 2를 진행하면서 객체 지향 프로그래밍과 데이터베이스 간의 괴리로 인해 ORM 기술을 사용하고 싶다는 충동이 계속 들었습니다. 도메인 객체가 중심이 되는 코드를 짜고 싶었는데 어느 순간 도메인이 그저 데이터 덩어리가 되어 기능하고 있는 경우도 있었죠. 아마 다른 크루분들의 상황도 같았을 겁니다. 그래서 레벨 3 프로젝트 때는 자바 표준 ORM 기술인 JPA 를 사용해야겠다 라는 생각이 들었고, 그 전에 레벨 3 프로젝트의 워밍업 단계라고도 볼 수 있는 사이드 프로젝트에서도 JPA를 사용한 프로젝트를 진행하고자 하였습니다. 다행히도 팀원인 오리와 후니도 같은 생각을 가지고 있었죠. 아니, 오히려 적극적인 JPA 사용 주장파였습니다. 어쨌든 JPA를 사용하기로 하고 나니 기술 스택은 자연스럽게 정해졌습니다.
- SpringBoot
- Spring Data JPA
- MySQL
- H2
- JUnit5
- RestAssured
- Spring REST Docs
다른 기술들은 다 써봤는데 Spring REST Docs는 처음 써 본 기술 스택이었습니다. (미션 요구사항으로 REST Docs의 빌드 결과물이 주어진 적은 있었지만요.) 다행히 오리가 REST Docs를 사용할 줄 알았고, 분석할만한 최소한의 코드를 미리 짜 준 덕분에 큰 문제 없이 진행할 수 있었습니다. Spring REST Docs 관련된 자료로는 테코블에 좋은 자료가 있으니 참고해 보시면 좋겠네요.
MVP로 만들기
MVP가 뭔지 아시나요? 당연히 Most Valuable Player는 아니고요, 최소 기능 제품(Minimum Viable Product)라는 뜻입니다! 위키피디아에 따르면 고객의 피드백을 받아 최소한의 기능(features)을 구현한 제품이라고 하는데요, 실리콘 밸리에서 처음 등장한 용어라고 하는데, MVP를 발표하는 데 초점을 맞춘다는 것은 개발자들이 잠재적으로 길고 불필요한 작업을 피할 수 있다는 것을 의미한다.라고 합니다.
처음에 기획하는 단계에서 구현하고 싶은 기능들은 되게 많이 있었는데요, 저희에게는 레벨 3 시작 이전까지의 몇 주간, 심지어는 미션을 진행하지 않는 여유로운 방학 기간은 2주 밖에 안되는 짧은 시간만 주어졌기 때문에 유용한 기능이라 하더라도 전부 구현하는 것은 불가능하다고 생각했습니다.
그래서 선택한 것이 MVP 방식으로 프로젝트를 구현하는 것이었습니다. 우선은 저희가 생각한 핵심 기능은 캠퍼스 주변의 음식점을 리스트업하고 그 음식점들에 대해서 크루들이 리뷰를 작성할 수 있는 시스템을 만드는 것이었기 때문에, 마이페이지라든가, 리뷰 모아보기라든가 하는 부가적인 기능은 미뤄두고 딱 그 기능에만 집중하기로 결정했습니다.
또한 최소 기능 제품 구현 시 고려해야 할 점이 바로 `완벽한 상품을 만들기 보다는, 개발 아이디어가 동작하도록 빠르게 구현하는 것을 중요시 해야 한다고 하는데요, 그래서 우선 필수적인 기능이 완성되어서 서비스로서의 기능을 다 하는 상태로 출시를 한 뒤 피드백을 받아 고쳐나가는 형태가 되었습니다. 그러다 보니 있으면 무조건 좋지만 꼭 필요하다고는 볼 수 없는 리뷰 수정이나 삭제 기능 같은 것이 누락되어 있는 상태로 서비스를 출시하게 되었네요. 개선 요구 사항들을 받아서 차차 수정해 나갈 생각입니다. (물론 여유가 좀 되는 시기에요...☆)
프로젝트 진행
사이드 프로젝트를 진행하면서 백엔드 팀이 강조했던 것은 컨벤션, 템플릿, 코드 리뷰 정도로 요약해 볼 수 있을 것 같아요. 세 명의 크루가 모였는데, 셋 다 평소에 작성하던 코드 스타일이 다 달라서 스타일을 맞추고 갈 필요가 있었고, 그래서 코드 컨벤션을 정하고 갔습니다. 지금 딱 기억나는 컨벤션이라면
- 메서드 파라미터에만
final키워드를 사용한다. 로컬 변수 선언 시에는 사용하지 않는다. - 엔티티의 동등성 비교(
equals,hashcode)에는id값만 사용한다. - Lombok 기능은
@Getter와@Builder만 사용하고, 생성자 등에는 사용하지 않는다. - 테스트 메서드는 한글로 작성한다.
- 엔티티 생성에는 빌더 패턴을 사용한다.(Lombok의
@Builder와 연계)
정도가 있을 것 같네요. 그 외에도 자잘한 컨벤션들이 많이 있었는데, 당연히 본인 평소 스타일과는 다른 만큼 중간 중간 지키지 못하는 상황이 나오면 코드 리뷰를 통해 지적해 주는 식으로 컨벤션을 유지했습니다.
다만 아쉬웠던 부분도 있는데요, 기능 요구사항 구현 위주로 프로젝트를 진행하다 보니 테스트 코드의 컨벤션은 중구난방이 되어 버렸습니다. 물론 테스트 코드에서도 큰 틀은 맞춰가면서 진행하기는 했는데, 세부적인 내용들이 전혀 통일되지 않았어요. 사실 가장 아쉬운건 테스트 컨벤션은 둘째 치고 테스트 코드 자체가 썩 좋은 코드는 아니라는 생각이 들었던 부분이었습니다. 이 부분은 차차 백엔드 팀원들끼리의 합의를 통해 리팩토링해 나가기로 결정하고 배포를 하게 되었습니다.

그리고 이번 기회에 Pull Requests에 템플릿을 설정할 수 있다는 것도 처음 알았습니다. 오리가 간단한 템플릿을 만들어주었는데요, .github 폴더에 PULL_REQUEST_TEMPLATE.md라는 이름으로 템플릿 파일을 만들면 매 PR 작성 시 마다 템플릿이 기본적으로 들어있는 상태로 작성을 시작할 수 있더라고요. 덕분에 이슈와 PR을 정형화된 형식으로 만들어서 한눈에 알아보기 쉬웠습니다.
가장 중요한 건 코드 리뷰였습니다! 원래 우테코에서는 현업에 계신 리뷰어분들께서 저희에 코드를 리뷰해주셨는데요, 사이드 프로젝트인 만큼 리뷰어나 코치분들의 리뷰를 받을 수는 없는 상황이고, 또한 레벨 3 부터는 리뷰어 없이 팀원끼리 서로서로 리뷰를 해야 하는 만큼 저희 역시 직접 서로의 코드에 리뷰를 하기로 결정했습니다. 그래서 PR을 날리고 나면 팀원들의 approve 없이는 merge를 하지 못하도록 설정하기도 했습니다.
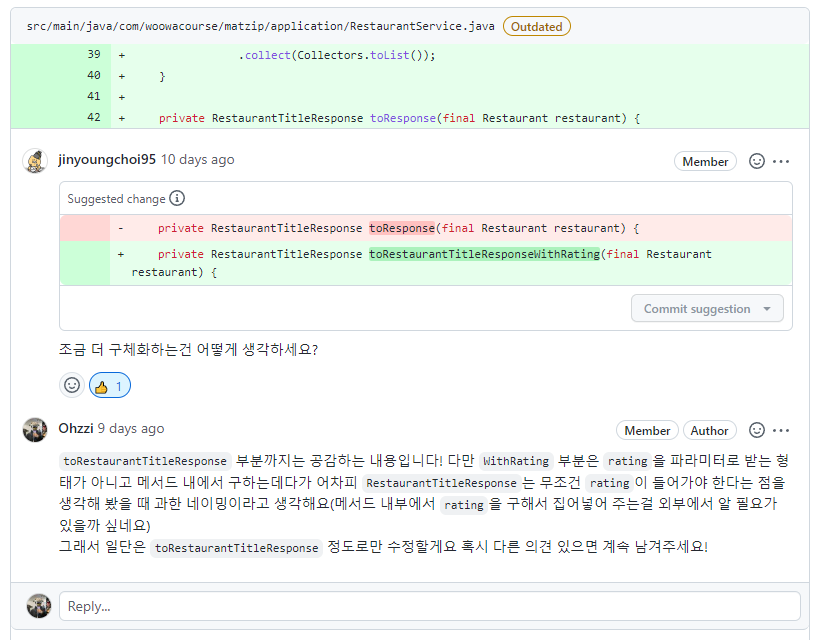
아, 제가 맡은 부분은 음식점과 관련된 전체적인 도메인 로직이었습니다. 원래는 도메인 로직 자체를 담당하는거였는데, 중간에 과중한 업무로 인해 리뷰 작성 및 조회에 관련된 기능은 오리에게 넘기고, 음식점 로직들만 집중했습니다. 저희 프로젝트는 현재 사용자가 직접 음식점을 등록하는 기능은 구현하고 있지 않은데요, 그래서 CRUD 중에 R 기능만 구현하고 있는 상태입니다.
그럼 더 쉽지 않냐고요? 하지만 조회에는 카테고리 별, 별점 순, 최신 순, 가나다 순, 랜덤 순과 같은 여러 필터링이 걸려서 들어가고, 무한 페이징을 사용하기 위해 Slice 를 반환하는 페이지네이션을 적용하고, 식당 테이블과 리뷰 테이블과의 연관관계를 관리하는 등의 작업을 하다 보니 새로 배울 것이 많았습니다. 특히나 저는 Spring Data JPA를 사용하면 JpaRepository를 상속하는 것 만으로 장땡이라고 생각했는데, 조회 기능에서는 JpaRepository가 만들어 주는 쿼리를 사용하는 것이 아니라 JPQL이나 네이티브 쿼리를 써야 하는 상황이 많이 나오더라고요. 실제로 저희 코드도 그렇습니다.
public interface RestaurantRepository extends JpaRepository<Restaurant, Long> {
@Query(
value = "select r from Restaurant r "
+ "where "
+ "(r.campusId = :campusId) "
+ "and "
+ "(:categoryId is null or r.categoryId = :categoryId) "
)
Slice<Restaurant> findPageByCampusId(@Param("campusId") Long campusId, @Param("categoryId") Long categoryId, Pageable pageable);
@Query(
value = "select r from Restaurant r left join Review rv on rv.restaurantId = r.id "
+ "where "
+ "(r.campusId = :campusId) "
+ "and "
+ "(:categoryId is null or r.categoryId = :categoryId) "
+ "group by r.id "
+ "order by avg(rv.rating) desc"
)
Slice<Restaurant> findPageByCampusIdOrderByRatingDesc(@Param("campusId") Long campusId, @Param("categoryId")Long categoryId, Pageable pageable);
@Query(
value = "select id, category_id, campus_id, name, address, distance, kakao_map_url, image_url "
+ "from restaurant "
+ "where campus_id = ? "
+ "order by rand() limit ?",
nativeQuery = true
)
List<Restaurant> findRandomsByCampusId(Long campusId, int size);
Slice<Restaurant> findPageByCampusIdAndNameContainingIgnoreCase(Long campusId, String name, Pageable pageable);
}이렇게 한 개의 메서드를 제외하고는 조회 메서드 자체가 다 쿼리를 직접 작성해서 사용하고 있습니다. 최적화 면에서도 그렇고, 조건에 null이 들어가는 부분에서 동적 쿼리를 만들어야 하는 부분까지 고려하다 보니 직접 쿼리를 작성하게 되었네요. 덕분에 이를 기회로 JPQL을 처음으로 사용해 보았고, 만족스러운 결과를 얻었습니다. 와중에 JPQL에는 rand가 없어서 랜덤 조회 기능에는 아예 네이티브 쿼리를 사용하기 까지 했네요.
아쉬운 점이 없지는 않습니다. 별점순 조회와 나머지 정렬 조회의 경우에 날리는 쿼리 형태가 달라서 부득이하게 메서드를 분리했는데, 이걸 컨트롤러에서 분기 처리를 하려다 보니 제가 별로 좋아하지 않는 if 문을 통해 관리하는 형태가 되어버렸습니다.
@GetMapping("/campuses/{campusId}/restaurants")
public ResponseEntity<RestaurantTitlesResponse> showPage(@PathVariable final Long campusId,
@RequestParam(required = false) final Long categoryId,
@RequestParam(value = "filter", defaultValue = "DEFAULT") final String filterName,
final Pageable pageable) {
SortCondition sortCondition = SortCondition.from(filterName);
if (sortCondition == RATING) {
return ResponseEntity.ok(restaurantService.findByCampusIdOrderByRatingDesc(campusId, categoryId, pageable));
}
Pageable pageableWithSort = PageRequest.of(pageable.getPageNumber(), pageable.getPageSize(),
sortCondition.getValue());
return ResponseEntity.ok(restaurantService.findByCampusId(campusId, categoryId, pageableWithSort));
}이 부분은 그냥 조회 기능에는 순수 JDBC를 사용해서 팩토리 패턴을 통해 쿼리를 동적으로 만들어서 쓰자 같은 의견들이 나왔는데, 우선은 개발 시간적인 한계로 if문 + JPQL의 형태로 처리를 하게 되었습니다. 만족스럽지는 않아서 추후에 리팩토링을 하고 싶은 부분이네요.
여기까지가 백엔드에서 제가 진행한 내용들입니다. 6명의 팀원이 모두 각자의 위치에서 맡은 바를 열심히 해준 결과인지, 결과물이 되게 만족스럽게 나왔습니다.
자세한 코드 및 PR 내용들을 보고 싶으시다면 백엔드 깃허브를 참고해주세요.
무엇을 배웠나요?
우선 다시 코딩에 흥미를 되찾은 점이 가장 큰 것 같습니다. 직접 서비스를 만들어 보고, 만든 서비스를 다른 크루들이 사용하는 모습을 보니 굉장히 뿌듯하더라고요. 레벨 2 마지막 미션이었던 장바구니 협업 미션은 협업이기는 하지만 6명의 팀원이 어쨌든 같은 내용을 각자 다른 코드로 구현해서 진짜 협업과는 다른 느낌이었다면, 이번에는 하나의 목표물을 만들기 위해 파트를 나눠서 각자의 위치에서 코드를 작성하다 보니 좀 더 협업다운 협업을 할 수 있었던 것 같아 좋았습니다.
기술적인 측면에서도 레벨 3에 들어가기에 앞서 많은 것을 배울 수 있는 시간이었는데요, 이전에는 JPA를 쓸 줄은 알았지만 수박 겉핥기 식으로 배워서 써먹은 것이었는데 JPQL이나 네이티브 쿼리까지 써가면서 좀 더 JPA에 대해 깊게 이해할 수 있는 시간이었습니다. 아직은 모자르지만요. 그리고 Spring REST Docs라든가,
기술적으로 아쉬웠던 점은 제가 배포를 아예 모르는 와중에 시간이 촉박한 관계로 배포 및 인프라 측면의 작업은 오리가 전담해서 했다는 점입니다. 결국 레벨 3에서 배포 및 인프라를 담당해야 하는 상황이 올 수 있는데, 배포 및 인프라에 대해서는 배우고 넘어가지 못한 점이 아쉽습니다. 이 부분은 오리에게 열심히 물어봐서 배워나가는 수 밖에 없을 것 같네요.
기획부터 시작하면 한 달 조금 안되는, 본격적으로 개발한 시간만 따지면 2주 정도 되는 짧은 사이드 프로젝트였습니다. 하지만 짧은 시간동안 꽤 많은 것을 한 것 같고, 결과물도 만족스럽게 나왔고, 과정도 재밌고 유익했던 시간이었습니다. 이번 사이드 프로젝트를 경험한 것을 토대로, 레벨 3 프로젝트는 더 발전된 프로젝트를 진행할 수 있기를 바라고 있습니다. 아, 물론 사이드 프로젝트의 리팩토링과 추가 기능 개발도 계속 이어 나갈 예정입니다.
끝으로, 트러블 없이 열심히 개발과 커뮤니케이션을 해준 우리 팀원들 블링, 샐리, 태태, 오리, 후니 감사합니다. 여러분 덕분에 좋은 프로젝트를 완료할 수 있었던 것 같습니다. 특히 백엔드 팀원분들, 여러분 덕분에 프로젝트를 하면서 굉장히 많은 지식을 체득할 수 있는 시간이었던 것 같아요. 앞으로 계속 이어질 리팩토링과 기능 추가 및 버그 픽스 과정도 수고해보도록 합시다 :)

글 잘읽었습니다!! 비슷한 아이디어로 사이드 프로젝트를 해볼까 하던차에 보게 돼서 재밌었어요! ㅎㅎ