1. 모델 성능 검증하기
1.1. 과적합
과적합(overfitting)은 모델이 학습 데이터와 정확히 일치하는 경우를 말합니다. 학습 데이터셋을 지나치게 오래 학습하거나 모델의 구조를 필요 이상으로 복잡하게 만드는 등의 문제로 모델이 학습 데이터와 너무 가깝게 들어맞으면 새로운 데이터에 대한 일반화가 제대로 이루어지지 않아 의도한대로 예측이 진행되지 않을 수 있습니다. 그래서 학습 시 오차율이 낮고 새로운 데이터에 대한 오차율이 높은 경우 과적합을 의심해봐야 합니다.
1.2. 과적합 감지
1.2.1. 데이터셋 분리
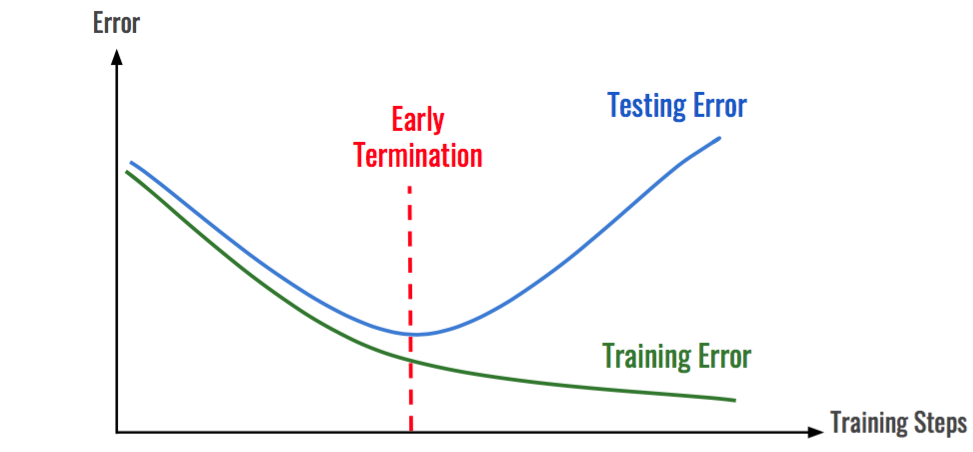
과적합을 피하기 위해서는 과적합이 발생하는지 확인할 수 있어야 합니다. 그래서 주어진 학습 데이터셋에서 일부를 테스트셋으로 두어 학습셋(train set)과 테스트셋(test set)을 구분하여 학습과 테스트를 동시에 진행하며 과적합을 판단합니다. 예를 들어, 주어진 데이터에서 70%를 학습셋으로 이용하고 나머지 30%를 테스트셋으로 이용하여 학습을 진행하면 오차를 비교할 수 있습니다. 위의 그래프와 같이 학습셋의 오차는 줄어들지만 테스트셋의 오차가 커지는 부분이 있습니다. 이 시점 이후로는 과적합이 발생했다고 판단할 수 있습니다.
Python에서 학습셋과 테스트셋을 나눌 때는 사이킷런(scikit-learn) 라이브러리에 있는 train_test_split() 함수를 사용할 수 있습니다.
1.2.2. k겹 교차 검증
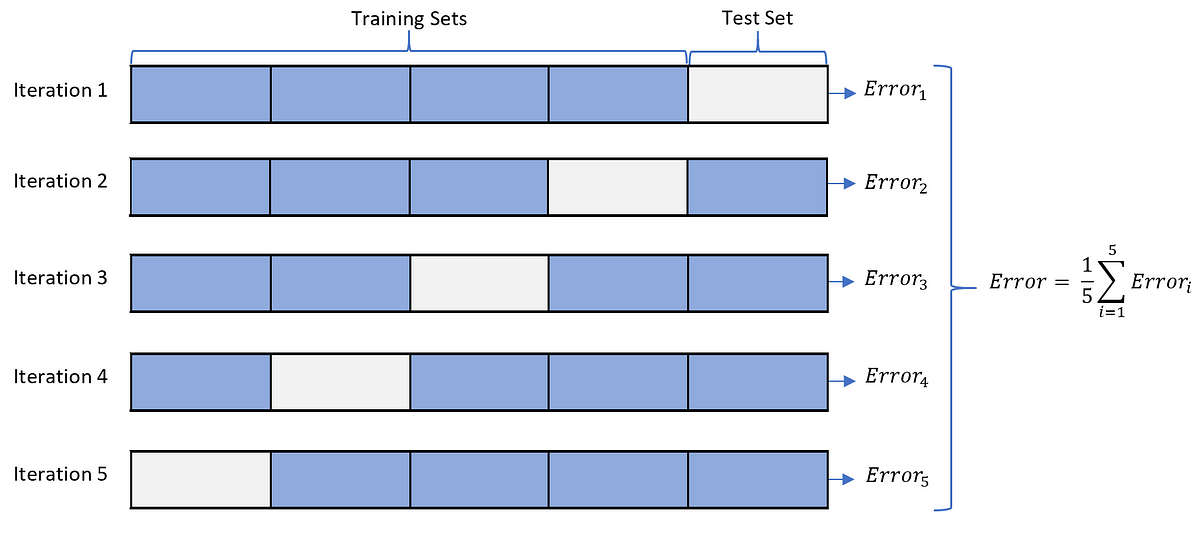
k겹 교차 검증(k-fold cross validation)이란 데이터셋을 k개로 나누어 각 조각을 하나씩 테스트셋으로 사용하고 나머지를 모두를 학습셋으로 사용하는 방법입니다. 이렇게 하면 가지고 있는 데이터를 모두 학습에 사용하면서 테스트에도 사용할 수 있습니다.
Python에서 k겹 교차 검증도 사이킷런 라이브러리에서 kFold() 함수를 통해 사용할 수 있습니다.
1.3. 과적합 방지
1.3.1. 데이터 보강 방식
과적합을 방지하는 방법으로 먼저 학습을 진행할 데이터를 보강하는 방식을 이용할 수 있습니다. 딥러닝의 경우 학습에 이용하는 샘플 데이터의 수가 많을 수록 성능의 향상을 보입니다.
데이터를 추가하기 어렵거나 추가만으로는 성능의 한계가 있는 경우에는 기존의 데이터를 적절히 이용하여 보완하는 방식을 이용할 수도 있습니다. 예를 들어, 기존의 데이터에 적당한 변형을 주어 사용하는 방식을 사용할 수 있습니다. k겹 교차 검증도 가지고 있는 데이터를 최대한 활용하여 사용하지 않을 때보다 성능 향상에 도움을 주는 방법 중 하나입니다.
1.3.2. 알고리즘 최적화 방식
알고리즘을 최적화하는 것은 은닉층, 노드의 수, 최적화 함수의 종류 등 모델의 구조를 바꾸어 가며 최적의 구조를 찾는 방식입니다. 최적화를 하는 과정에서 모델을 저장하고 불러오는 작업을 해야 하는 경우에는 다음과 같이 저장 및 불러오기를 사용할 수 있습니다.
모델 저장, 불러오기
만들어 낸 모델은 model.save() 함수에 모델 경로 및 이름을 입력하여 저장할 수 있습니다. 모델을 저장할 때는 hdf5 포맷을 사용합니다.
모델을 불러오려면 load_model() 함수에 불러올 파일의 경로를 입력하여 사용하면 됩니다. 이 함수는 keras API의 models 클래스에 있으므로 import 하여 사용할 수 있습니다.
1.4. 모델 성능 확인해보기
사이킷런 라이브러리 설치
우선 이번 실습을 하기 위해서는 사이킷런 라이브러리가 필요합니다. 사이킷런 라이브러리가 없는 경우에는 다음 코드를 터미널에 입력하여 설치할 수 있습니다.
pip install sklearn위의 코드에 에러가 있다면 다음 코드를 사용해볼 수 있습니다.
pip install scikit-learn1.4.1. 학습셋과 데이터셋 구분 사용
(1) 필요 라이브러리 불러오기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd(2) 데이터 불러오기
이번 실습에서는 초음파 광물 데이터를 사용합니다.
df = pd.read_csv('./data/sonar3.csv', header=None)
X = df.iloc[:,0:60] # 음파 관련 속성
y = df.iloc[:,60] # 광물의 종류(3) 학습셋과 테스트셋 구분하기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)(4) 모델 설정
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))(5) 모델 컴파일 및 실행
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=200, batch_size=10)(6) 테스트셋에 적용하여 정확도 확인
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])실행 결과
학습을 진행한 결과 학습셋에서는 마지막 반복 때는 100% 정확도를 보이고 있습니다.
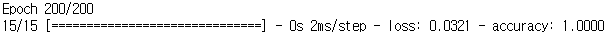
하지만 테스트셋에 적용해보니 정확도가 76.19%로 큰 차이를 보이고 있습니다. 따라서 학습 결과 과적합이 발생하였다고 판단할 수 있습니다. 최종적으로 모델의 성능은 100%가 아니라 76.19%라고 판단할 수 있습니다.
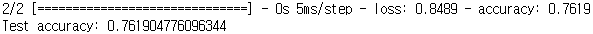
1.4.2. k겹 교차 검증 사용
(1) 필요 라이브러리 불러오기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import pandas as pd(2) 데이터 불러오기
이번 실습에서는 초음파 광물 데이터를 사용합니다.
df = pd.read_csv('../data/sonar3.csv', header=None)
X = df.iloc[:,0:60] # 음파 관련 속성
y = df.iloc[:,60] # 광물의 종류(3) k겹 교차 검증 준비
kFold 함수를 불러옵니다. 코드를 보면 5겹으로 설정하였고 샘플을 분할하기 전에 섞도록 설정한 것을 확인할 수 있습니다. 또한 정확도를 저장할 리스트 변수를 만들어줍니다.
kfold = KFold(n_splits=5, shuffle=True)
acc_score = [](4) 모델 설정
반복문 안에서 여러번 모델 구조를 만들어야 하므로 함수로 만들어줍니다.
def model_fn():
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
return model(5) k겹 교차 검증 실행
여기서 split() 함수를 이용하여 데이터셋을 k개의 학습셋과 테스트셋으로 분리합니다. 200번씩 5번 반복하여 출력이 많으므로 model.compile()에 verbose 옵션을 0으로 설정하여 학습 과정의 출력을 생락하였습니다.
for train_index, test_index in kfold.split(X):
X_train, X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model = model_fn()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1]
acc_score.append(accuracy) # 정확도 저장(6) 결과 출력
정확도의 평균을 구하고 결과를 출력합니다.
avg_acc_score = sum(acc_score) / 5
print('정확도: ', acc_score)
print('정확도 평균: ', avg_acc_score)실행 결과

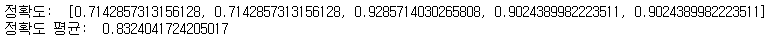
결과를 확인해 보면 모델이 약 83.24%의 정확도를 가진 것을 확인할 수 있습니다.
2. 모델 성능 향상시키기
2.1. 검증셋
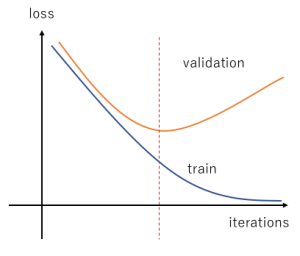
테스트셋은 학습이 완료된 모델의 최종 성능을 평가하기 위해 사용하는 데이터셋의 일부였습니다. 검증셋(validation set)은 테스트셋과 비슷하게 학습셋의 오차와 비교하기 위해 사용되는 데이터셋의 일부입니다. 하지만 검증셋은 최적의 학습 상태를 찾기 위해 학습 과정 중간에 사용되는 데이터셋의 일부입니다. 아래 그래프와 같이 검증셋을 이용하여 오차율을 확인하며 파쇄선에 해당하는 반복 시점의 모델을 선택하도록 할 수 있습니다. model.fit() 부분에 validation_split 옵션에 학습셋에서 검증셋으로 지정할 비율을 설정하여 분리할 수 있습니다.
학습셋, 검증셋, 테스트셋을 구분하여 학습하고 평가하는 전체 과정은 아래 그림과 같습니다.
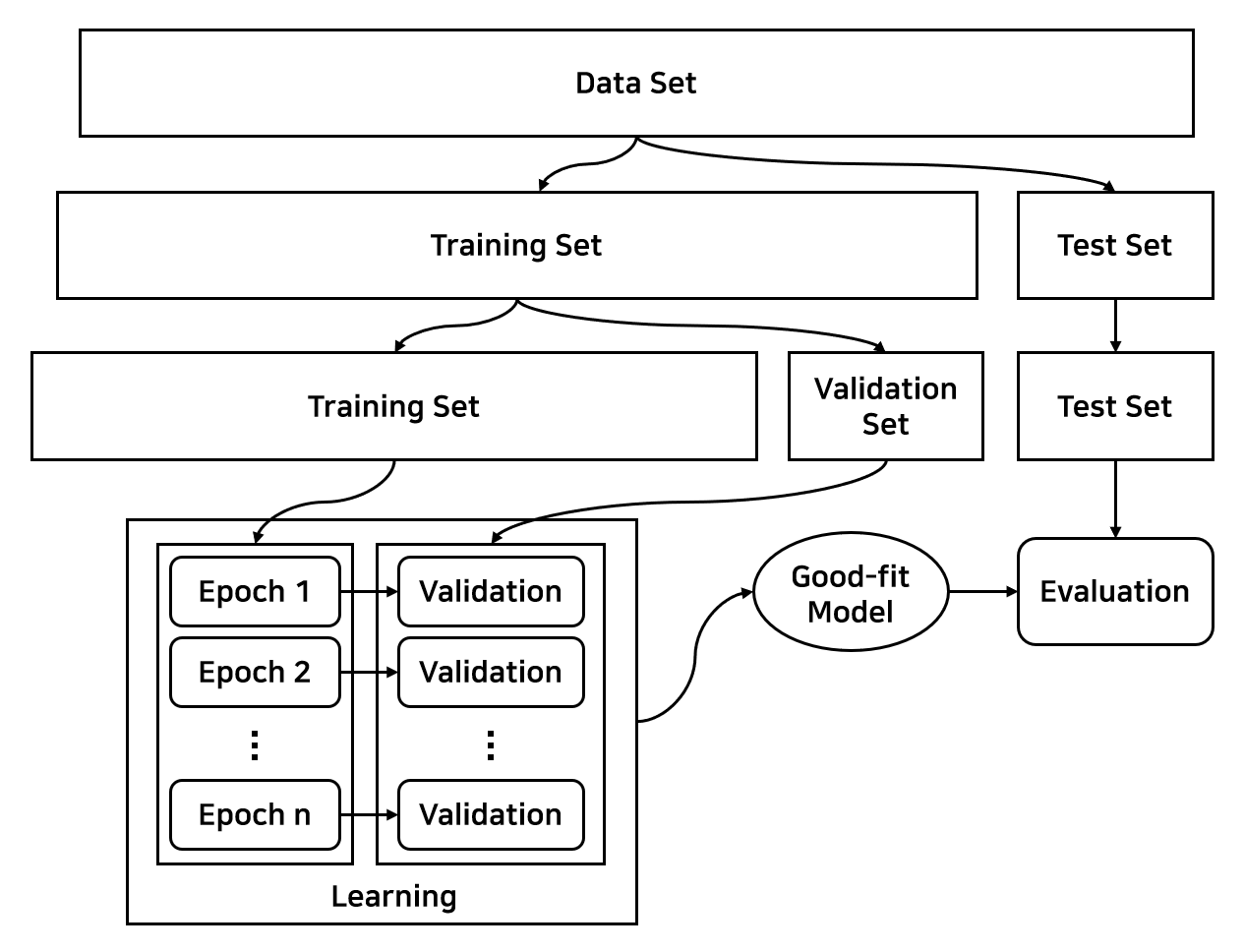
2.2. 체크포인트
학습을 반복하는 중간에 검증셋을 이용하여 최적의 학습이 이루어진 모델을 찾을 수 있습니다. 그래서 각 반복마다 모델을 저장하여 반복을 모두 실행한 뒤 오차율이 가장 낮은 모델을 찾는 방법으로 체크포인트 함수를 활용할 수 있습니다.
다음과 같이 keras API의 ModelCheckpoint() 함수를 이용할 수 있습니다.
from tensorflow.keras.callbacks import ModelCheckpoint
modelpath = "./data/model/all/{epoch:02d}-{val_accuracy:.4f}.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, verbose=1)위의 코드를 추가하여 실행하면 ./data/model/all/ 폴더에 입력한 포맷의 이름대로 모델들이 저장됩니다. 이후에 모델을 실행할 때 model.fit() 함수의 callbacks 옵션에 [checkpointer]를 입력해주면 적용됩니다.
2.3. 그래프로 나타내기
그동안 학습을 진행하는 중에 loss, accuracy 등의 출력을 통해 모델의 오차와 예측 정확도를 확인할 수 있었습니다. 검증셋을 이용할 때는 model.fit() 함수에서 validation_split 옵션에 학습셋 중 검증셋으로 분리할 비율을 설정해주면 출력으로 모델을 검증셋에 적용하여 얻은 오차(val_loss)와 정확도(val_accuracy)를 추가할 수 있습니다.
history는 이러한 정확도, 오차 등의 내용을 저장하고 있습니다. history 변수의 history 객체에는 loss, accuracy, val_loss, val_accuracy 등이 포함되어 있어 이를 활용하여 학습 과정을 데이터로 다룰 수 있습니다. 이를 활용한 코드는 다음과 같습니다.
- 실행 코드
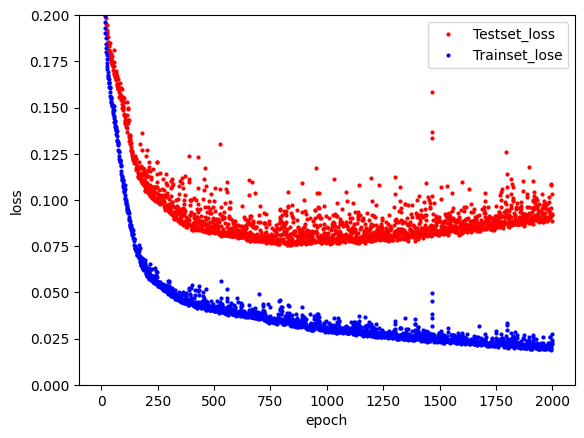
# history를 이용하여 데이터프레임 만들기
hist_df = pd.DataFrame(history.history)
y_vloss = hist_df['val_loss'] # 검증셋 오차
y_loss = hist_df['loss'] # 학습셋 오차
# 그래프를 표현하기 위한 배열 생성
x_len = np.arange(len(y_loss))
# 그래프 설정하기
plt.plot(x_len, y_vloss, "o", c="red", markersize=2, label='Testset_loss')
plt.plot(x_len, y_loss, "o", c="blue", markersize=2, label='Trainset_lose')
plt.legend(loc='upper right')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.ylim([0, 0.2])
plt.show()- 실행 결과
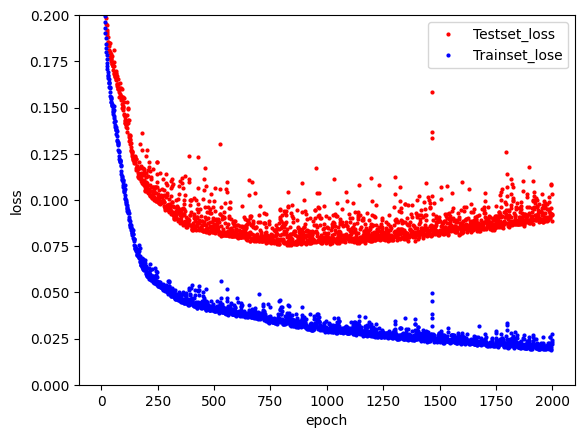
2.4. 학습 자동 중단
Keras API 중 EarlyStopping() 함수를 이용하면 학습 진행 중 최적의 모델을 지나치고 테스트셋 오차가 줄어들지 않을 때 학습을 자동으로 멈추게 할 수 있습니다.
EarlyStopping() 함수에서 patience는 학습을 종료하는 때를 정하는 옵션입니다. 예를 들어, patience=20으로 지정한 경우에는 검증셋의 오차가 20번 반복 이상 낮아지지 않는 경우 학습을 종료합니다. ModelCheckpoint() 함수에서 save_best_only=True로 지정하게 되면 가장 검증셋의 오차율이 낮은 모델 하나만 저장하게 됩니다. 위의 두 함수를 적용하려면 model.fit() 함수의 callbacks=[EarlyStopping_변수명, ModelCheckpoint_변수명]으로 지정해줘야 합니다.
이를 활용하면 다음과 같이 최적의 모델을 저장하도록 코드를 작성할 수 있습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
# 자동중단, 체크포인트를 불러오기
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
df = pd.read_csv("../data/wine.csv", header=None)
X = df.iloc[:, 0:12]
y = df.iloc[:, 12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
# 학습 자동 중단 설정하기
early_stopping_callbacks = EarlyStopping(monitor='val_loss', patience=20)
modelpath = "./data/model/bestmodel.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=2000, batch_size=500, validation_split=0.25, verbose=1, callbacks=[early_stopping_callback, checkpointer])
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
Reference
- 해당 글은 "모두의 딥러닝" 13-14장을 기반으로 작성되었습니다.
- 조태호. 모두의 딥러닝 (개정3판). 길벗(2022)
