1. 데이터 분석
pandas 라이브러리를 활용하여 주어진 데이터를 살펴보면 다음과 같습니다.
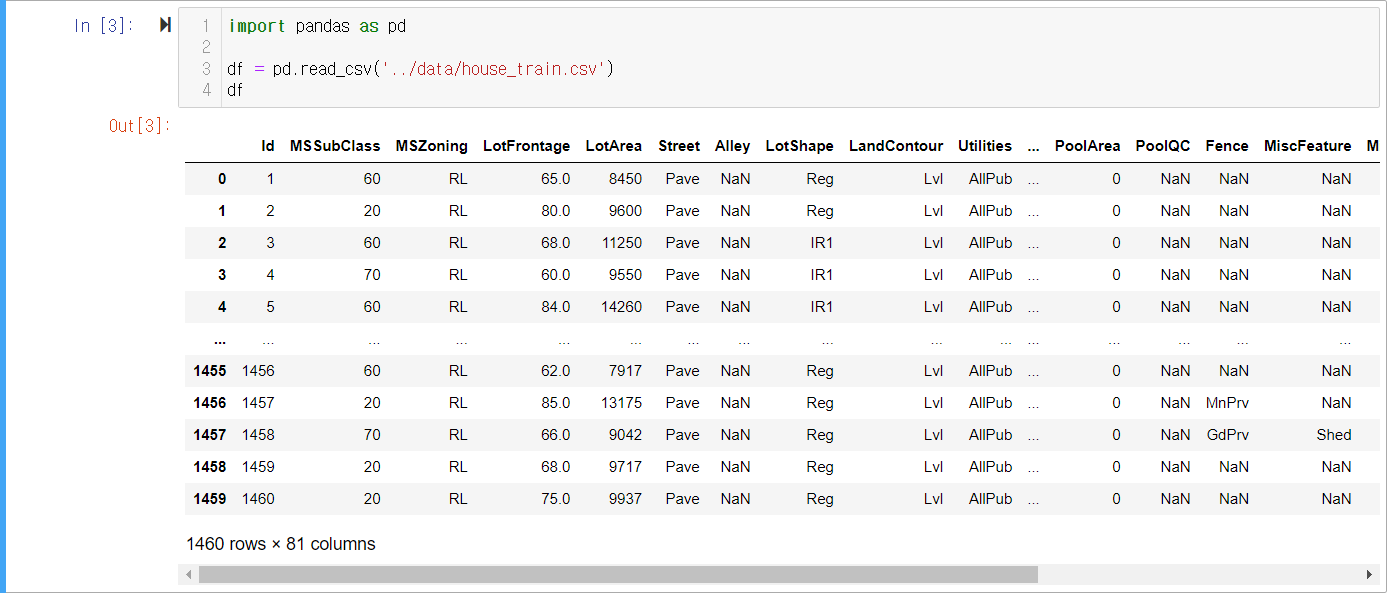
이 데이터에는 총 80개의 속성과 SalePrice라는 하나의 클래스가 있습니다. 데이터를 살펴보면 중간에 NaN과 같이 측정값이 없는 결측치도 있음을 확인할 수 있습니다. 결측치는 그대로 사용할 수 없으므로 데이터 전처리 과정을 통해 해결합니다.
2. 데이터 전처리
2.1. 결측치
확인한 것과 같이 전처리가 끝나지 않은 상태의 데이터에는 측정 값이 없는 결측치가 존재하기도 합니다. 결측치의 존재를 확인하는 함수는 isnull() 입니다.
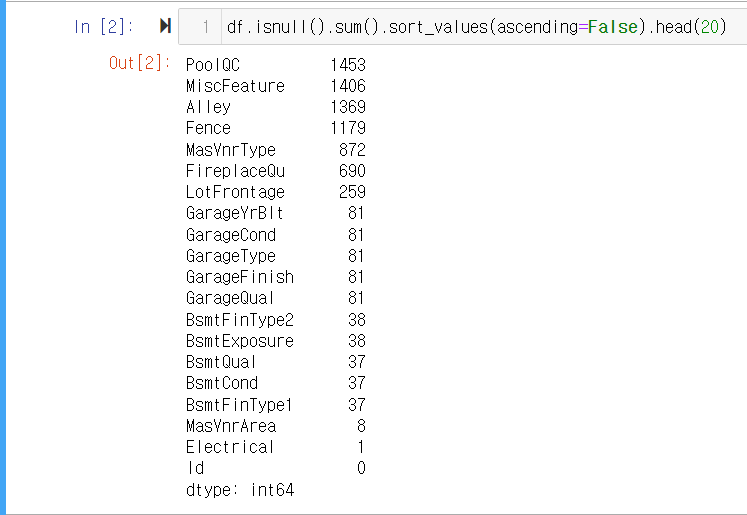
다음 코드는 결측치의 개수를 세어 내림차순으로 출력하는 코드입니다.
df.isnull().sum().sort_values(ascending=False).head(20)- 실행 결과
결측치에 대해서 각 속성별로 다음과 같이 출력되었습니다. 결측치가 많아 모델을 만들기 위해서는 데이터 전처리를 해야 합니다.
2.2. 결측치 처리 및 카테고리 변수 처리
-
get_dummies()함수를 이용하여 카테고리형 변수를 one-hot 인코딩 처리합니다. -
결측치는
fillna()함수를 이용하여 적당한 값으로 채워줍니다. 여기서는 평균값으로 채워줬습니다. -
dropna()함수를 사용하면 결측치가 있는 속성을 제거합니다.how='any'를 추가하면 결측치가 하나라도 있으면 속성을 제거하고,how='all'을 추가하면 모든 값이 결측치인 경우에만 속성을 제거합니다.
결측치 처리 및 카테고리 변수 처리를 하는 코드는 다음과 같습니다.
df = pd.get_dummies(df)
df = df.fillna(df.mean())
3. 속성별 관련도 추출
3.1. 상관관계 확인
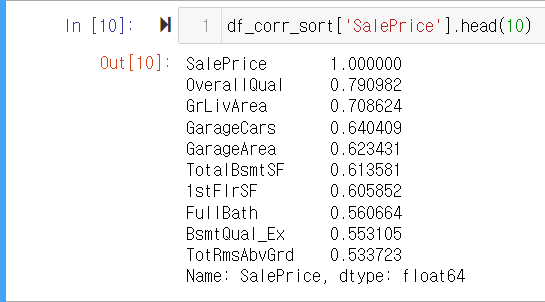
여러 속성 중에서 필요한 정보를 추출하기 위해 속성별 상관관계를 알아보도록 하겠습니다. 각 속성별 결과에 대한 상관관계를 저장하고 정렬하는 코드는 다음과 같습니다.
- 실행 코드
df_corr = df.corr()
df_corr_sort = df_corr.sort_values('SalePrice', ascending=False)- 처리 결과
3.2. 그래프로 나타내기
그래프로 나타내는 코드는 다음과 같습니다.
- 실행 코드
import seaborn as sns
import matplotlib.pyplot as plt
cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF']
sns.pairplot(df[cols])
plt.show()- 실행 결과
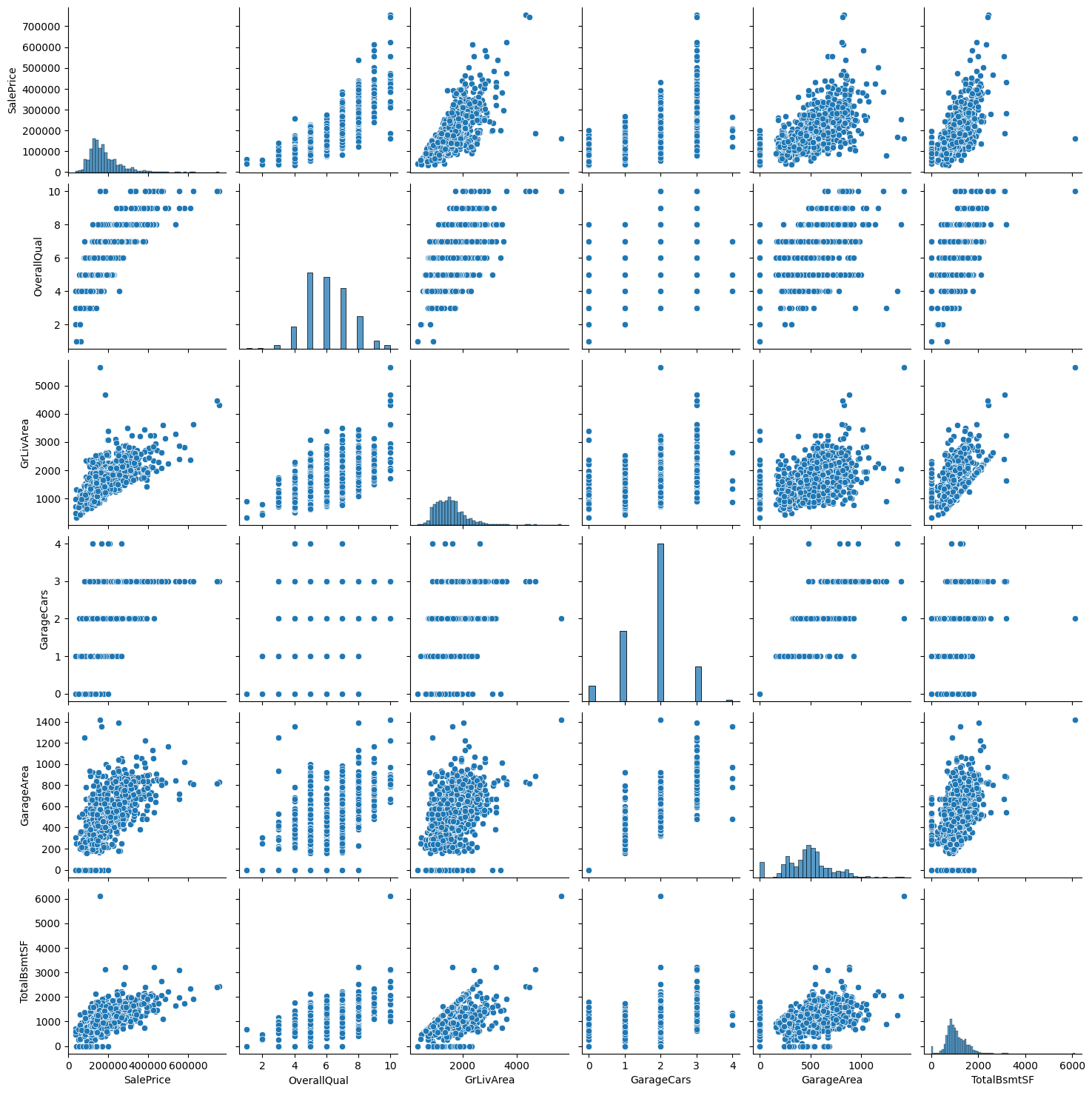
그래프에서 SalePrice와 비교하는 부분의 형태를 살펴보면 선택된 속성들이 정적상관 관계임을 확인할 수 있습니다. 따라서 학습을 진행할 때 다음과 같은 속성들을 사용할 수 있습니다.
4. 데이터를 활용하여 예측 모델 만들기
4.1. 집값 예측 모델 만들기
지금까지 했던 모델 구조 생성, 모델 성능 검증, 자동 중단 등을 적용하면 다음과 같이 코드를 작성해볼 수 있습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 전처리가 완료된 데이터 불러오기
df = pd.read_csv("__전처리된 데이터 파일경로__")
# 사용할 속성들에 대한 데이터셋 만들기
cols_train = ['OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
X_train_pre = df[cols_train]
# 결과값 데이터
y = df['SalePrice'].values
# 학습셋과 테스트셋 분리하기
X_train, X_test, y_train, y_test = train_test_split(X_train_pre, y, test_size=0.2)
# 모델 구조 설정
model = Sequential()
model.add(Dense(10, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(1))
model.summary()
# 모델을 실행
model.compile(optimizer='adam', loss='mean_squared_error')
# 학습 자동 중단 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
# 체크포인트 설정
modelpath = "./data/model/Ch15-house.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
# 학습 실행
history = model.fit(X_train, y_train, validation_split=0.25, epochs=2000, batch_size=32, callbacks=[early_stopping_callback,checkpointer])4.2. 모델 성능 확인하기
다음과 같이 코드를 작성하여 25개의 샘플을 이용하여 값을 비교해보면 다음과 같습니다.
- 실행 코드
real_prices = []
pred_prices = []
X_num = []
n_iter = 0
Y_prediction = model.predict(X_test).flatten()
for i in range(25):
real = y_test[i]
prediction = Y_prediction[i]
real_prices.append(real)
pred_prices.append(prediction)
n_iter = n_iter + 1
X_num.append(n_iter)
plt.plot(X_num, pred_prices, label='predicted price')
plt.plot(X_num, real_prices, label='real price')
plt.legend()
plt.show()- 실행 결과
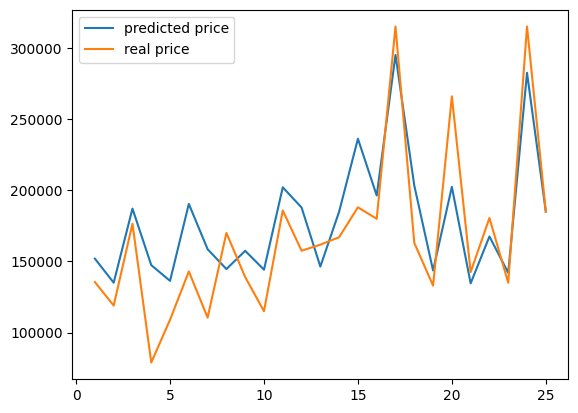
만들어 낸 모델이 실제 집 값과 어느 정도 유사하게 따라가고 있음을 확인할 수 있습니다.
Reference
- 해당 글은 "모두의 딥러닝" 15장을 기반으로 작성되었습니다.
- 조태호. 모두의 딥러닝 (개정3판). 길벗(2022)
