
1. 자연어 처리
자연어는 음성이나 텍스트와 같은 사람의 언어를 의미합니다. 자연어 처리(Natural Language Processing, NPL)는 컴퓨터가 사람의 언어를 인식하고 처리하도록 하는 것입니다. 하지만 단순한 텍스트의 형태는 컴퓨터가 데이터로 사용하기 어렵습니다. 그래서 자연어 처리를 위해 텍스트 데이터를 전처리하는 과정이 필요합니다.
1.1. 텍스트 토큰화
토큰(token)은 주어진 텍스트를 단어와 같은 단위로 잘게 나눈 기본 단위입니다. 입력된 텍스트를 토큰으로 나누는 과정을 토큰화(tokenization)이라고 합니다. Keras에서는 text_to_word_sequence() 함수를 이용하여 문장을 단어 단위로 나눌 수 있습니다. 이를 이용하여 토큰화는 다음과 같이 코드를 작성하여 실행할 수 있습니다.
예제 코드
from tensorflow.keras.preprocessing.text import text_to_word_sequence
# 전처리할 텍스트
text = "If you can't explain it simply, you don't understand it well enough"
result = text_to_word_sequence(text)
print("원문:", text)
print("\n토큰화:", result)실행 결과
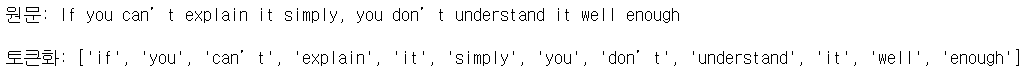
위와 같이 text_to_word_sequence() 함수를 이용하면 텍스트가 단어 단위로 나눠진 리스트를 얻을 수 있습니다.
이렇게 단어 단위로 토큰화를 진행하여 단어의 빈도수를 알면 중요한 역할을 하는 단어를 알 수 있습니다. Bag-of-Words 전처리 방법은 단어 단위로 토큰화를 진행하고 단어를 같은 것끼리 가방에 담은 후 각 가방에 몇 개의 단어가 들어 있는지 세는 등의 처리를 진행합니다.
아래와 같이 문장이 주어졌다고 했을 때, Kears에 있는 Tokenizer() 함수를 이용하여 전처리를 진행할 수 있습니다.
예시 코드
from tensorflow.keras.preprocessing.text import Tokenizer
docs = ["먼저 텍스트의 각 단어를 나누어 토큰화합니다.",
"텍스트의 단어로 토큰화해야 딥러닝에서 인식됩니다.",
"토큰화한 결과는 딥러닝에서 사용할 수 있습니다."
]
token = Tokenizer() # 토큰화 함수 지정
token.fit_on_texts(docs) # 토큰화 함수에 문장을 넣어 토큰화
print("단어 카운트:\n", token.word_counts) # 각 단어의 빈도수 출력
print("\n문장 카운트:\n", token.document_count) # 문장 수 출력
print("\n단어 포함 카운트:\n", token.word_docs) # 단어가 문장에 얼마나 포함되어 있는지 출력
print("\n인덱스:\n", token.word_index) # 각 단어에 매겨진 인덱스 값실행 결과

1.2. 단어의 One-Hot 인코딩
문장 안에서 단어 사이의 관계를 확인하기 위해 one-hot 인코딩을 사용할 수 있습니다. 자연어 처리에서 one-hot 인코딩은 단어 수 + 1 크기의 배열을 만들어 0으로 채워넣고 각 단어가 배열 내에 해당하는 위치를 1로 바꿔 처리할 수 있습니다.
Keras의 Tokenizer 클래스 중 texts_to_sequences() 함수를 하여 토큰의 인덱스로 이루어진 배열을 생성하고, 이것을 to_categorical() 함수를 사용하여 간단하게 one-hot 인코딩을 수행할 수 있습니다.
예시 코드
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
text = "If you can't explain it simply, you don't understand it well enough"
token = Tokenizer()
token.fit_on_texts([text])
print("\nword index:\n", token.word_index)
x = token.texts_to_sequences([text])
print("\nsequence:\n", x)
x = to_categorical(x, num_classes=word_size)
print("\none-hot encoding:\n", x)실행 결과

1.3. 단어 임베딩
One-hot 인코딩을 그대로 사용하면 벡터의 길이가 너무 길어지기 때문에 공간 효율을 위해 주어진 배열을 정해진 길이로 압축시키는 단어 임베딩(word embedding)이라는 방법을 사용합니다. 단어 임베딩을 진행할 때는 각 단어 간의 유사도를 계산하여 밀집된 정보를 가지고 있는 벡터로 표현하게 됩니다. 단어 간 유사도 계산은 오차 역전파를 이용하여 학습 과정을 통해 이루어집니다. Keras에서는 Embedding()이라는 함수를 이용하여 쉽게 단어 임베딩을 수행할 수 있습니다.
Embedding 클래스
tensorflow.keras.layers.Embedding(
input_dim,
output_dim,
embeddings_initializer='uniform',
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None,
sparse=False,
**kwargs
)input_dim: 입력될 단어 목록의 크기output_dim: 출력될 벡터의 크기embeddings_initializer: 임베딩 행렬의 초기화 함수embeddings_regularizer: 임베딩 행렬에 적용되는 정규화 함수embeddings_constraint: 임베딩 행렬에 적용되는 제약 함수mask_zero: 0으로 패딩(padding)된 값이 적절히 마스크 되었는지 확인input_length: 입력 시퀀스의 길이sparse: True인 경우 이 레이어를 호출하면 tf.SparseTensor를 반환. False인 경우 레이어는 조밀한 tf.Tensor를 반환합니다.
여기서 패딩(padding)은 서로 다른 길이의 문장의 길이를 맞추어주는 것입니다. 패딩은 Keras의 pad_sequences() 함수를 이용하여 처리할 수 있습니다.
예시 코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding
model = Sequential()
model.add(Embedding(16, 4, input_length=2)위와 같이 코드를 작성하면 입력된 단어의 수는 16, 임베딩 후 출력 벡터의 크기는 4로 매번 두 개씩 단어를 넣어 임베딩을 진행합니다.
2. 자연어 처리 모델 만들기
NLP 예제로는 영화 리뷰를 긍정적인지 부정적인지 판단하는 모델을 만들어보겠습니다.
2.1. 구조
데이터 준비
데이터는 텍스트 리뷰 자료와 이에 대한 긍정 및 부정을 나타내는 클래스를 사용합니다. 다음은 예시 코드입니다.
# 리뷰 텍스트 데이터
docs = ['너무 재밌네요',
'최고예요',
'참 잘 만든 영화예요',
'추천하고 싶은 영화입니다.',
'한 번 더 보고싶네요',
'글쎄요',
'별로예요',
'생각보다 지루하네요',
'연기가 어색해요',
'재미없어요'
]
# 긍정은 1, 부정은 0으로 클래스 지정
class = np.array([1,1,1,1,1,0,0,0,0,0])데이터 전처리
# 토큰화
token = Tokenizer()
token.fit_on_texts(docs)
# 인덱스 배열 생성
x = token.texts_to_sequences(docs)
# 패딩
padded_x = pad_sequences(x, 4)모델 구조 생성
word_size = len(token.word_index) + 1
model = Sequential()
model.add(Embedding(word_size, 8, input_length=4))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(padded_x, classes, epochs=20)
print("\n Accuracy: %.4f" % (model.evaluate(padded_x, classes)[1]))2.2. 전체 코드
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Embedding
from tensorflow.keras.utils import to_categorical
import numpy as np
# 리뷰 텍스트 데이터
docs = ['너무 재밌네요',
'최고예요',
'참 잘 만든 영화예요',
'추천하고 싶은 영화입니다.',
'한 번 더 보고싶네요',
'글쎄요',
'별로예요',
'생각보다 지루하네요',
'연기가 어색해요',
'재미없어요'
]
# 긍정은 1, 부정은 0으로 클래스 지정
class = np.array([1,1,1,1,1,0,0,0,0,0])
# 토큰화
token = Tokenizer()
token.fit_on_texts(docs)
# 인덱스 배열 생성
x = token.texts_to_sequences(docs)
# 패딩
padded_x = pad_sequences(x, 4)
word_size = len(token.word_index) + 1
model = Sequential()
model.add(Embedding(word_size, 8, input_length=4))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(padded_x, classes, epochs=20)
Reference
- 해당 글은 "모두의 딥러닝" 17장을 기반으로 작성되었습니다.
- 조태호. 모두의 딥러닝 (개정3판). 길벗(2022)
