1. 순환 신경망
1.1. RNN
문장을 다루기 위해서는 단어 간 관계를 이해해야 합니다. 이렇게 과거에 입력된 데이터와 나중에 입력된 데이터 사이의 관계를 고려하기 위해 순환 신경망(Recurrent Neural Network, RNN) 방법이 고안되었습니다. RNN은 여러 개의 데이터가 순서대로 입력되었을 때 앞서 입력받은 데이터를 잠시 기억해놓고 기억된 데이터가 얼마나 중요한지 판단하고 별도의 가중치를 주어 다음 데이터로 넘기는 방법입니다. 이러한 RNN 방식은 입력과 출력의 수를 다양하게 선택하여 모델을 만들 수 있습니다.
1.2. LSTM
RNN은 한 층 안에서 반복을 많이 하면서 기울기 소실 문제가 더 많이 발생합니다. 그래서 이를 보완하기 위해 LSTM(Long Short Term Memory) 방법을 같이 사용합니다. LSTM은 반복되기 직전에 다음 층으로 기억된 값을 넘길지 여부를 관리하는 방법입니다.
2. RNN을 이용한 모델
2.1. LSTM을 이용한 로이터 뉴스 카테고리 분류 모델
Keras에서 제공하는 로이터 뉴스 데이터셋을 활용하여 뉴스 카테고리를 분류하는 다중 입력단일-출력모델을 만들어 보겠습니다.
실행 코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.datasets import reuters
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
## 데이터 전처리
# 학습셋과 테스트셋 나누기
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1000, test_split=0.2)
# 단어의 수 맞추기
X_train = sequence.pad_sequences(X_train, maxlen=100)
X_test = sequence.pad_sequences(X_test, maxlen=100)
# one-hot 인코딩
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
## 모델
# 모델 구조 설정
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation='softmax'))
# 모델 컴파일
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 자동 중단 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
# 모델 실행
history = model.fit(X_train, y_train, batch_size=20, epochs=200, validation_data=(X_test, y_test), callbacks=[early_stopping_callback])
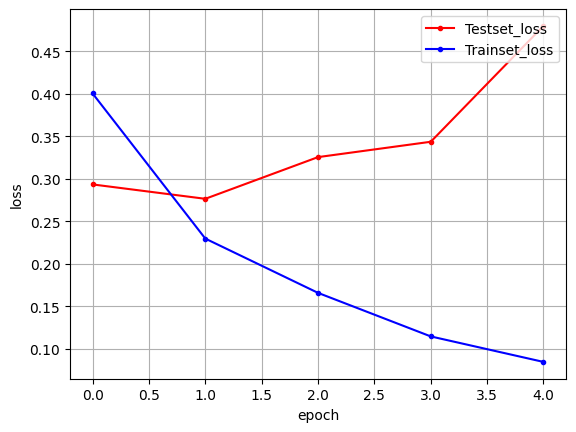
## 결과 확인
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(x_test, y_test)[1]))
# 오차 저장
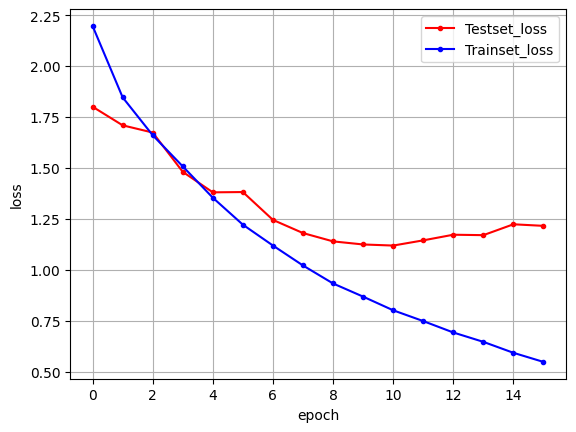
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프 그리기
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()실행 결과
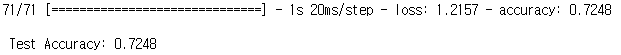
2.2. LSTM과 CNN을 이용한 영화 리뷰 분류
Keras에서 제공하는 인터넷 영화 데이터베이스(Internet Movie DataBase, IMDB) 데이터셋은 영화와 관련된 다양한 데이터를 제공합니다. 오늘은 영화 리뷰를 이용하여 영화 비류를 분류하는 모델을 만들어 보겠습니다.
실행 코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Embedding, LSTM, Conv1D, MaxPooling1D
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
## 데이터 전처리
# 학습셋과 테스트셋 나누기
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=5000)
# 단어의 수 맞추기
X_train = sequence.pad_sequences(X_train, maxlen=500)
X_test = sequence.pad_sequences(X_test, maxlen=500)
## 모델
# 모델 구조 설정
model = Sequential()
model.add(Embedding(5000, 100))
model.add(Dropout(0.5))
model.add(Conv1D(64, 5, padding='valid', activation='relu', strides=1))
model.add(MaxPooling1D(pool_size=4))
model.add(LSTM(55))
model.add(Dense(1))
model.add(Activation('sigmoid'))
# 모델 컴파일
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 자동 중단 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
# 모델 실행
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_split=0.25, callbacks=[early_stopping_callback])
## 결과 확인
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
# 오차 저장
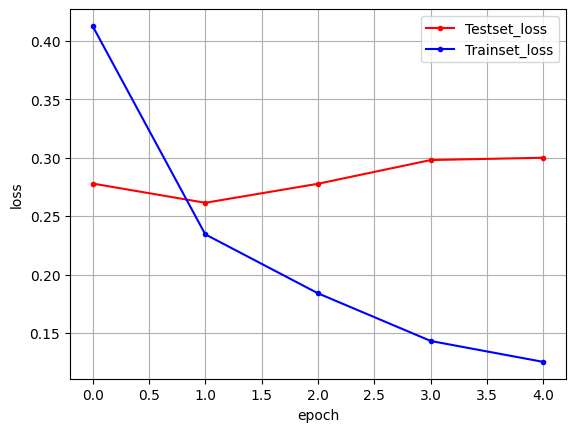
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프 그리기
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()실행 결과
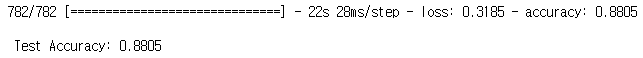
3. Attention
RNN은 마지막 노드에 담긴 값에 전체 문장의 뜻이 함축되어 있는 문맥 벡터 구조입니다. 이러한 구조는 입력 값의 길이가 길어지면 모든 값을 디코더에 제대로 전달하기 힘들어집니다. 어텐션 알고리즘은 이러한 문제를 해결할 수 있습니다. 어텐션의 구조는 인코더와 디코더 사이에 층이 추가되어 셀로부터 계산된 스코어가 모이고 소프트맥스 함수를 사용해서 어텐션 가중치를 만들어 어떤 셀을 중점적으로 볼지 결정합니다. RNN은 마지막 셀에 모든 입력이 집중되었지만 이러한 단점을 어텐션 알고리즘이 모든 입력을 두루 활용하게 하면서 보완을 했습니다.
Python에서는 Attention 라이브러리를 활용하여 어텐션 알고리즘을 사용할 수 있습니다. 앞서 진행했던 영화리뷰 실습에 적용하면 다음과 같습니다.
실행 코드
라이브러리는 pip를 이용하여 다음과 같이 설치할 수 있습니다.
pip install attentionfrom tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Embedding, LSTM, Conv1D, MaxPooling1D
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.callbacks import EarlyStopping
from attention import Attention # 어텐션 라이브러리
import numpy as np
import matplotlib.pyplot as plt
## 데이터 전처리
# 학습셋과 테스트셋 나누기
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=5000)
# 단어의 수 맞추기
X_train = sequence.pad_sequences(X_train, maxlen=500)
X_test = sequence.pad_sequences(X_test, maxlen=500)
## 모델
# 모델 구조 설정
model = Sequential()
model.add(Embedding(5000, 500))
model.add(Dropout(0.5))
model.add(LSTM(64, return_sequences=True))
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
# 모델 컴파일
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 자동 중단 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
# 모델 실행
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_split=0.25, callbacks=[early_stopping_callback])
## 결과 확인
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
# 오차 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프 그리기
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()실행 결과

Reference
- 해당 글은 "모두의 딥러닝" 18장을 기반으로 작성되었습니다.
- 조태호. 모두의 딥러닝 (개정3판). 길벗(2022)
