ML
1.데이터 탐색과 시각화
데이터 분석가가 반드시 알아야 할 모든 것 Chapter 10
2024년 7월 24일
2.[혼공머신] 첫 머신러닝
KNeighborsClassifier()
2024년 7월 28일
3.[혼공머신] 회귀 알고리즘과 모델 규제

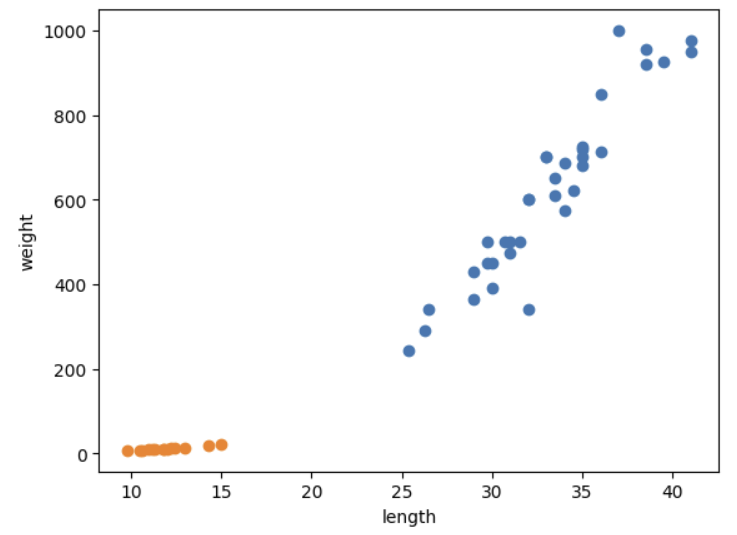
지도 학습 알고리즘은 크게 분류와 회귀로 나뉜다.회귀는 클래스 중 하나로 분류하는 것이 아니라 임의의 어떤 숫자를 예측하는 문제두 변수 사이의 상관관계를 분석하는 방법분류와 같이 예측하려는 샘플에 가장 가까운 샘플 k개를 선택.회귀이기 때문에 이웃한 샘플의 타깃은 어떤
2024년 8월 5일
4.[혼공머신] 다양한 분류 알고리즘
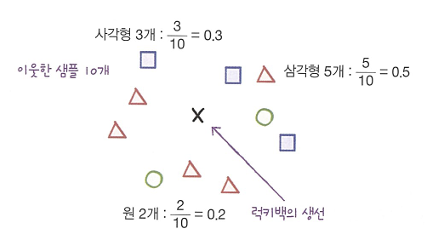
어떤 타깃에 속하는지에 대한 확률을 구하는 방법?확률은 회귀 문제? 분류?principle of knn샘플 X 주위에 가장 가까운 이웃 샘플 10개를 표시.사각형🟦이 3개, 삼각형🔺이 5개, 원🟢이 2개.이웃한 샘플의 클래스를 확률로 삼는다면 샘플 X가 사각형🟦
2024년 8월 12일
5.[혼공머신] 트리 알고리즘
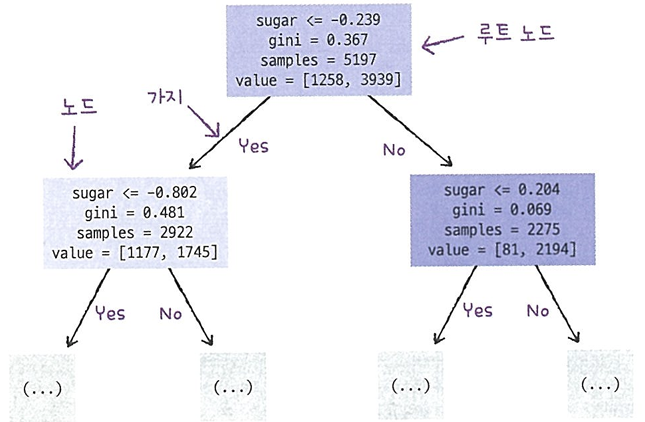
💡 methodhead() : 처음 5개의 샘플 확인info() : 데이터 프레임의 각 열의 데이터 타입과 누락된 데이터가 있는지 확인하는 데 유용describe() : 평균, 표준편차, 최소, 최대값을 확인할 수 있으며 중간값과 1사분위수 그리고 3사분위수를 알려줌
2024년 8월 19일
6.[혼공머신] 비지도 학습

Unsupervised Learning
2024년 8월 27일