나의 첫 머신러닝
1.1 인공지능과 머신러닝, 딥러닝
인공지능 Artificial Intelligence
사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술.
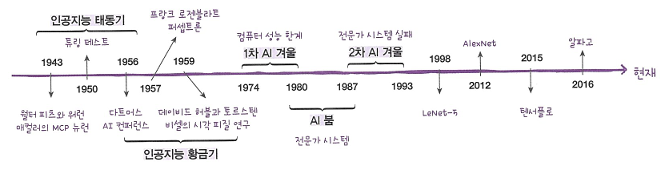
1. 인공지능 태동기
- 1943 Warren McCulloch와 Walter Pitts 뇌의 뉴런 개념의 발표
- 1950 Alan Turing이 인공지능이 사람과 같은 지능을 가졌는지 테스트할 수 있는 튜링 테스트를 발표
- 1956 다트머스 AI 컨퍼런스
- 인공지능 황금기
- 1957 Frank Rosenblan 로지스틱 회귀의 초기 버전으로 간주되는 퍼셉트론 Perceptron을 발표
- David Hubel과 Torsten Wiesel 고양이를 사용해 시각 피질에 있는 뉴런 기능 연구
- 첫 AI 겨울
- 두 번째 AI 붐
- 두 번째 AI 겨울
영화와 드라마, 소설 속에서 지능을 가진 컴퓨터 시스템이 등장하는 것이 흔하지만 영화 속에 등장하는 인공지능을 실생활에서 체험하기는 어렵다. 그 이유는 각각 표현하고 있는 기능이 다른 기술이기 때문!
인공일반지능 Aritificial General Intelligence
강인공지능 Strong AI
사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템
약인공지능 Weak AI
아직까지는 특정 분야에서 사람의 일을 도와주는 보조 역할만 가능.
ex. 음성 비서, 자율 주행 자동차, 음악 추천, 기계 번역
머신러닝 Machine Learning
규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야. 인공지능의 하위 분야 중에서 지능을 구현하기 위한 소프트웨어를 담당하는 핵심 분야.
- 통계학과 관련
통계학에서 유래된 머신러닝 알고리즘이 많으며 통계학과 컴퓨터 과학 분야가 상호 작용하면서 발전하고 있음. - 최근 머신러닝의 발전은 경험을 바탕으로 발전하는 경우도 많음
컴퓨터 과학 분야가 발전을 주도하며, 대표적인 머신러닝 라이브러리로는 사이킷런 scikit-learn이 있다.
Scikit-learn
- 사이킷런 라이브러리는 파이썬 API를 사용하는데 파이썬 언어는 배우기 쉬우며 컴파일하지 않아도 되기 때문에사용하기에 편리.
- 누구나 조금만 배워 머신러닝 프로그램을 만들 수 있다.
- 사이킷런 라이브러리에서 제공하는 클래스와 함수를 필요한 작업을 수행할 수 있다.
- 모든 머신러닝 알고리즘이 포함되어 있지는 않지만, 머신러닝 라이브러리에 포함된 알고리즘들은 안정적이며 성능이 검증되어 있다.
- 오픈소스의 발전과 함께 머신러닝 분야는 폭발적으로 성장.
- 파이썬 코드를 다룰 수 있다면 누구나 머신러닝 알고리즘을 무료로 손쉽게 제품에 활용할 수 있다.
현재의 개발자들은 머신러닝 알고리즘을 이해하고 사용할 수 있어야 한다!!!
딥러닝 Deep Learning
많은 머신러닝 알고리즘 중 인공 신경망 aritificial neural network을 기반으로 한 방법들을 통칭하는 것.
LeNet-5
두 번째 AI 겨울 기간 중 1988년 Yann Lecun이 신경망 모델을 만들어 손글씨 숫자를 인식하는데 성공했고, 이 신경망의 이름을 LeNet-5라고 함. LeNet-5는 최초의 합성곱 신경망.
AlexNet
2012년 Geoffrey Hinton의 팀이 이미지 분류 대회인 ImageNet에서 기존의 머신러닝 방법을 누르고 압도적인 성능으로 우승함. Hinton이 사용한 모델의 이름은 AlexNet이며 합성곱 신경망을 이용하였다.
이때부터 이미지 분류 작업에 합성곱 신경망이 널리 사용되기 시작했다.
인공신경망이 이전과 다르게 놀라운 성능을 달성하게 된 원동력
1. 복잡한 알고리즘을 훈련할 수 있는 풍부한 데이터
2. 컴퓨터 성능의 향상
3. 혁신적인 알고리즘 개발
TensorFlow
2015 구글이 오픈소스로 공개한 딥러닝 라이브러리 텐서플로 TensorFlow
PyTorch
2018 페이스북이 오픈소스로 발표한 딥러닝 라이브러리 파이토치 PyTorch
TensorFlow와 PyTorch의 공통점:
- 인공 신경망 알고리즘을 전문으로 다루고 있다는 것
- 모두 사용하기 쉬운 파이썬 API를 제공한다는 점
1.2 Colab과 Jupyter Notebook
Google Colab
웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있으며 머신러닝 프로그램도 만들 수 있는 서비스.
클라우드 기반의 주피터 노트북 개발 환경이다.
코랩 파일을 "노트북"이라고 부른다.
노트북의 장점: 코드를 설명하는 문서를 따로 만들지 않고 코드와 텍스트를 함께 담을 수 있다. 코드의 실행 결과도 노트북과 함께 저장되기 때문에 다른 사람에게서 노트북 파일을 받으면 코드를 실행할 필요 없이 코드 설명과 실행결과까지 바로 확인 가능하다.
코랩에서 실행할 수 있는 최소 단위를 "셀 cell"이라고 한다.
노트북
코랩은 구글이 대화식 프로그래밍 환경인 주피터를 커스터마이징한 것.
코랩 노트북은 구글 클라우드의 가상 서버 Virtual Machine를 사용.
노트북은 구글 클라우드의 컴퓨터 엔진에 연결되어 있으며 이 서버의 메모리는 약 12GB이고 디스크 공간은 100GB이다.
코랩 노트북은 구글 드라이브에 보관되며 언제든지 다시 실행할 수 있다.
Google Drive
구글이 제공하는 클라우드 파일 저장 서비스로, 코랩에서 만든 노트북은 자동으로 구글 클라우드의 특정 폴더에 저장되고 필요할 때 다시 코랩에서 열 수 있다.
1.3 마켓과 머신러닝
- 특성 feature : 데이터의 특징
- 산점도 scatter plot : x, y축으로 이뤄진 좌표계에 두 변수(x,y)의 관계를 표현하는 방법
- 맷플롯립 matplotlib : 파이썬에서 과학 계산용 그래프를 그리는 대표적인 패키지
- 임포트 import : 따로 만들어둔 파이썬 패키지를 사용하기 위해 불러오는 명령
- 훈련 training : 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정
- 모델 model : 머신러닝 프로그램에서는 알고리즘이 구현된 객체
- 정확도 : 정확한 답을 몇 개 맞혔는지를 백분율로 나타낸 값. 사이킷런의 경우 0~1 사이의 값으로 출력됨
정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
k-최근접 이웃 알고리즘 k-Nearest Neighbors Algorithm
어떤 데이터에 대한 답을 구할 때, 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용하는 알고리즘.
k-최근접 이웃 알고리즘을 위해 준비해야 할 일:
데이터를 모두 가지고 있는 것!!
새로운 데이터에 대해 예측할 때에는 가장 가가운 직선거리에 어떤 데이터가 있는지를 살피기!
단점: k-최근접 이웃 알고리즘의 이런 특징 때문에 데이터가 아주 많은 경우 사용하기 어렵다. 데이터가 크기 때문에 메모리가 많이 필요하고 직선거리를 계산하는 데도 많은 시간이 필요.
마켓과 머신러닝: 첫 번째 머신러닝 프로그램 실습
생선 분류 문제
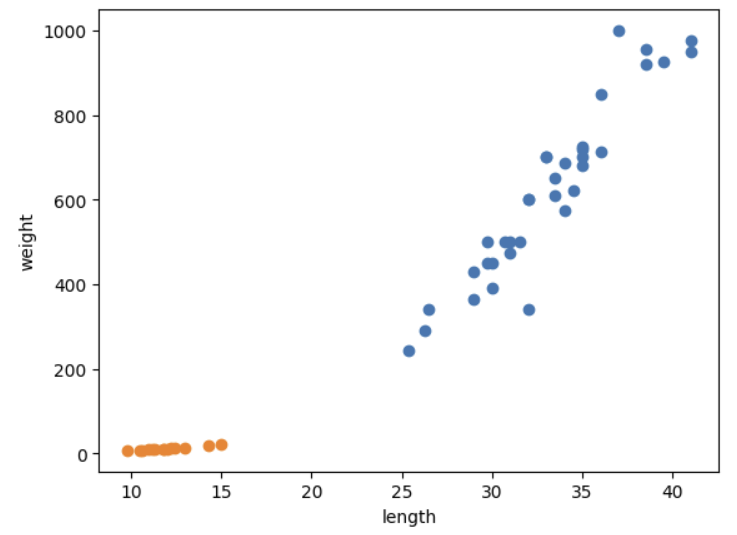
도미 데이터와 빙어 데이터를 준비하고 사용할 머신러닝 패키지인 사이킷런에 맞게 각 특성의 리스트를 2차원 리스트로 만들어야 한다.
사이킷런은 머신러닝 패키지이며, 2차원 리스트가 필요하다
파이썬의 zip()함수와 리스트 내포 list comprehension 구문을 사용.
zip() 함수는 나열된 리스트 각각에서 하나씩 원소를 꺼내 반환.
fish_data = [[l, w] for l, w in zip(length, weight)]for문은 zip()함수로 length와 weight 리스트에서 원소를 하나씩 꺼내어 l과 w에 할당함으로써 [l,w]가 하나의 원소로 구성된 리스트가 생성됨.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassfier()KNeighborsClassifier()는 k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스며, n_neighbors 매개변수로 이웃의 개수를 지정할 수 있다.
KNeighborsClassifier 클래스의 기본값: 5
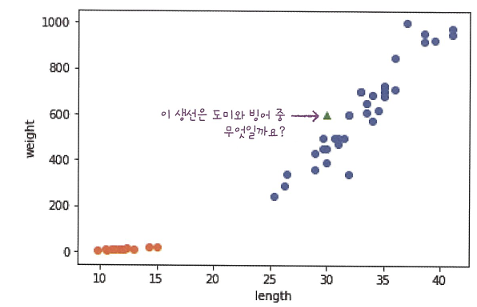
파란색 점이 도미이고 주황색 점이 빙어라면, 삼각형으로 표시된 새로운 데이터는 어디에 속할까? k-최근접 이웃 알고리즘도 우리가 직관적으로 판단하는 것과 같이 삼각형 주위에 도미 데이터가 많기 때문에 삼각형을 도미라고 판단할 것.
K-NN는 전체의 유닛과 거리비교를 하고 정렬한 다음에 K개를 선택해서 비교!!
