A 65nm 3T Dynamic Analog RAM-Based Computing-in- Memory Macro and CNN Accelerator with Retention Enhancement, Adaptive Analog Sparsity and 44TOPS/W System Energy Efficiency
Problem to solve
- 기존 CIM들이 사용한 6T/8T/10T SRAM이 CIM array의 크기를 제한.
- 기존 CIM들을 multi-bit calculation을 위해 bit-wise operation이 필요.
- Analog non-linearity로 인해 capacitor matching 및 input voltage encoding이 필요.
- ADC가 macro의 power 대부분을 차지.
How to solve
- 3T dynamic-analog-RAM(DARAM)을 통해 트랜지스터 및 면적 감소.
- Single-phase MAC을 통해 multi-phase calculation/digital accumulation으로 throughput degradation 제거.
- Linear한 time-based activation을 통해 analog non-linearity 경감 및 multi-bit capacitor들의 matching 필요성, read current compensation 제거.
- Analog sparsity-based low-power method를 통해 ADC, SA의 power bottleneck 경감.
3T DARAM
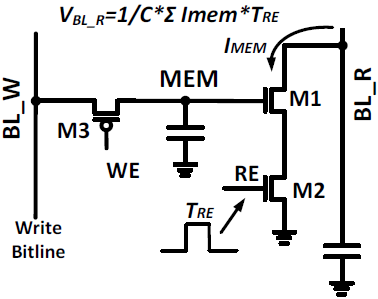
Operation
4b weight는 MEM capacitor에 저장되며, input은 4b time pulse로 표현된다.
Weight는 M3을 통해 BL_W로부터 write된다. 4b weight는 -8 ~ 7의 범위를 가지며, 범위에서 표현된다. Write에는 column-wise로 1 cycle만에 수행되며, 총 64 row가 존재하여 전체 write에는 64 cycle이 필요하다.
Input은 M2를 통해 입력되며, time pulse 형태를 가진다. Pulse의 resolution은 50 ps이며, input의 값에 비례하여 pulse의 지속시간이 증가한다. 예를 들어, 4b'1111은 750 ps의 pulse로 표현된다.
1개의 cell에 대해 로 나타내어 지며, BL_R의 전압이 input과 weight의 곱에 비례하여 변화한다.
BL_R은 세로로 64 row의 cell끼리 공유하고, RE는 가로로 32 column의 cell끼리 공유하여 64x32 MAC을 수행한다.
Weight가 1개의 cell로 표현이 가능해 4b MAC이 한 번의 DARAM read로 가능하며, 기존의 bit-wise operation에 비해 간단하다. 2개의 DARAM cell을 2 cycle에 걸쳐 같이 사용하여 8b/8b MAC로 수행할 수 있다. 그러나 M3에 dominant한 subthreshold leagkage와 weight-간의 non-linearity가 해결되어야 한다.
Leakage
Leakage로 인한 voltage drop은 로 나타내지므로, voltage drop을 줄이기 위해서는 을 증가시켜야 한다.
본 논문에서는 M1~M5에 걸친 3D inter-layer/inter-digit metal capacitor를 사용하여 을 약 3배정도 증가시켰다. 또한 M1의 경우 큰 W, L을 사용하여 variation과 capacitance를 향상시켰다.
또한, 를 0.8 V로 biasing하여 leakage를 약 20배 감소시켰다. Leakage가 감소함에 따라 typical corner에서는 약 41k cycle, fast corner에서는 약 5.6k cycle 정도의 retention time을 가졌으며, 이는 이 cycle 동안 weight re-write가 필요하지 않음을 나타낸다. 이를 통해 VGG16에 대해 5~40의 batch size를 weight refresh 없이 연산이 가능하였고, 이보다 더 큰 batch size를 가질경우 약 5.5 ~ 41k cycle마다 refresh가 필요하다. Refresh는 약 1.2%의 throughput overhead와 0.4%의 energy overhead를 가지지만 작은 batch size나 stationary weight가 적은 경우 refresh가 필요하지 않다.
Non-linearity
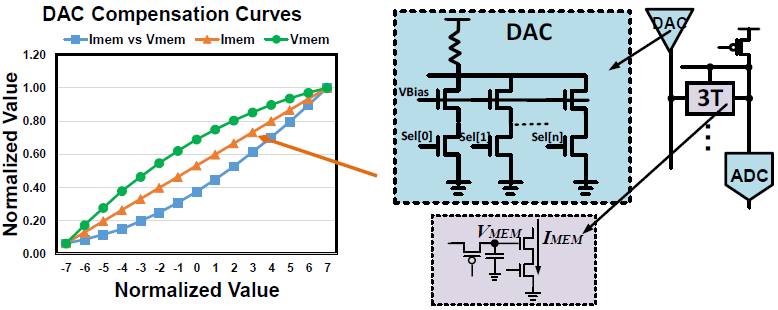
Transistor의 I-V curve로 인해 과 이 linear하지 못하고 non-linearity가 발생한다. 이를 해결하기 위해 DAC의 output 특성을 non-linear하게 조절하여 과 간의 non-linearity를 향상시켰다.
CIM architecture
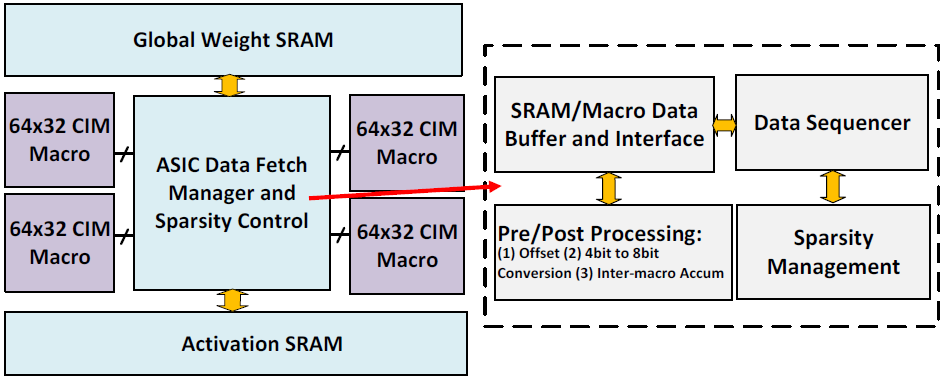
- CIM macro X4
- DTC(Digital-Time-Converter)
4b activation을 50 ps resolution의 time pulse로 변환한다. - 5b SAR ADC
- 4b current DAC
- Global weight SRAM
- Activation SRAM
- ASIC core
Data sequencing과 pre/post-processing을 수행한다.- Offsetting data for non/2's complement format support
- 4b to 8b conversion
- Accumulation at inter-macro loop
Analog sparsity
-
MAC-based ADC skipping
VGG16에서, 60% 이상의 경우에서 BL의 voltage drop이 full-swing의 27% 이하였다. 따라서, voltage drop이 충분히 작은경우 ADC operation과 BL precharge를 수행하지 않고 둘 이상의 MAC 연산을 수행한다. 이는 약 0.1~0.4%의 accuracy degradation을 발생시켰지만 약 65%의 ADC skipping이 가능하였고 ADC power를 약 2.4배 감소시켰다. -
RelU-based ADC skipping
ReLU를 기반으로 accumulation 결과가 충분히 작아 나머지 연산을 수행하더라도 0 이상의 값을 가지지 않는다고 판단되면 MAC 연산을 조기에 종료한다. 연산의 70%는 값에 상관없이 연산을 수행하며, 이후로는 미리 설정된 threshold를 바탕으로 ASIC이 조기종료여부를 결정한다. MAC-based ADC skipping과 같이 적용하여 ADC power를 약 2.9배 감소시켰다. -
Weight shifting
Weight가 그리 크지 않아 column의 dynamic range가 다 사용되지 않을경우 weight를 shift하여 MAC energy를 감소시킨다. Weight를 얼마만큼 shift할 지는 offline으로 계산되며 연산결과는 ASIC에서 원래의 값으로 복원된다. 평균적으로 3b의 shift가 수행되었고, MAC 연산의 power를 약 1.5배 감소시켰다.
Measurements
Batch size 37의 VGG16에 대해 38k cycle의 연산이 refresh없이 수행 가능하였고, 더 큰 batch size에 대해 refresh throughput overhead는 최대 0.17%였다.
ADC skipping을 사용하여 skipping threshold = 27%를 사용했을 때, ADC energy의 65%를 감소시켰고, 0.4% 이하의 accuracy degradation이 발생하였다. Skipping threshold를 낮출 경우 ADC power saving이 감소하고 높일 경우 power saving은 증가하지만 accuracy degradation이 급격히 증가한다.
