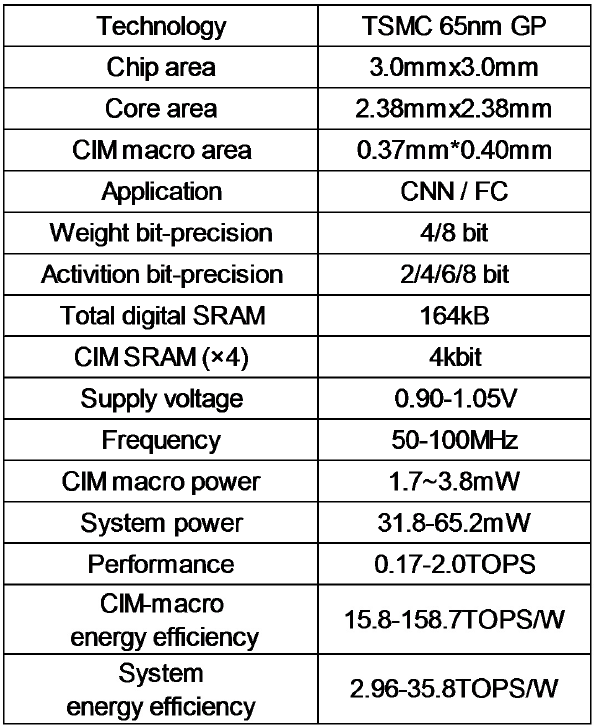
A 65nm Computing-in-Memory-Based CNN Processor with 2.9-to-35.8TOPS/W System Energy Efficiency Using Dynamic-Sparsity Performance-Scaling Architecture and Energy-Efficient Inter/Intra-Macro Data Reuse
Problem to solve
- Sparse data는 대부분 random하게 분포되어 있어 CIM macro에 바로 mapping하면 sparsity로 인한 power gating을 적용하지 못해 비효율적이다.
- Optimal macro utilization과 data reuse를 위해 NN의 layer별로 adaptive mapping, scheduling이 필요하다.
How to solve
- Activation/weight sparsity aware acceleration/power saving을 위한 Dynamic Sparsity performance Scaling architecture(DSS).
- Adaptive Kernel/Channel-Order(KCO) mapping, intra/inter-macro scheduling을 통한 macro utilization/data reuse 향상.
- Adaptive power-off Processing Unit(PU)를 포함한 efficient Block-Wise Sparsity-optimized CIM macro(BWS-CIM).
Architecture
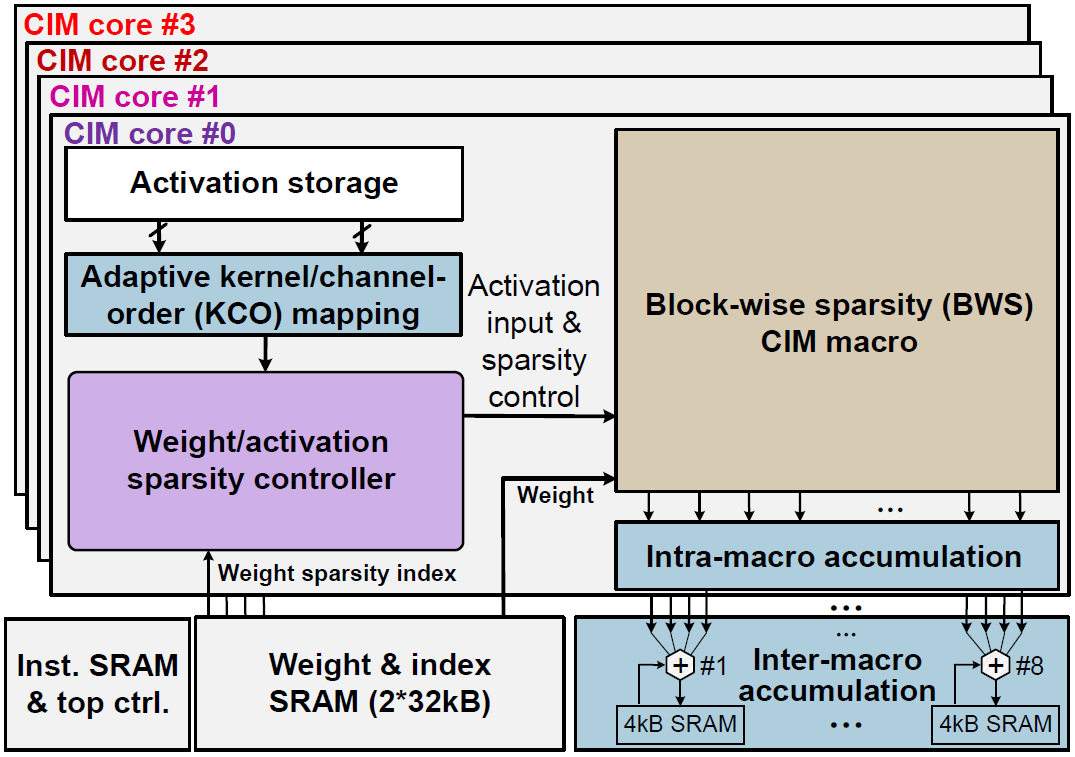
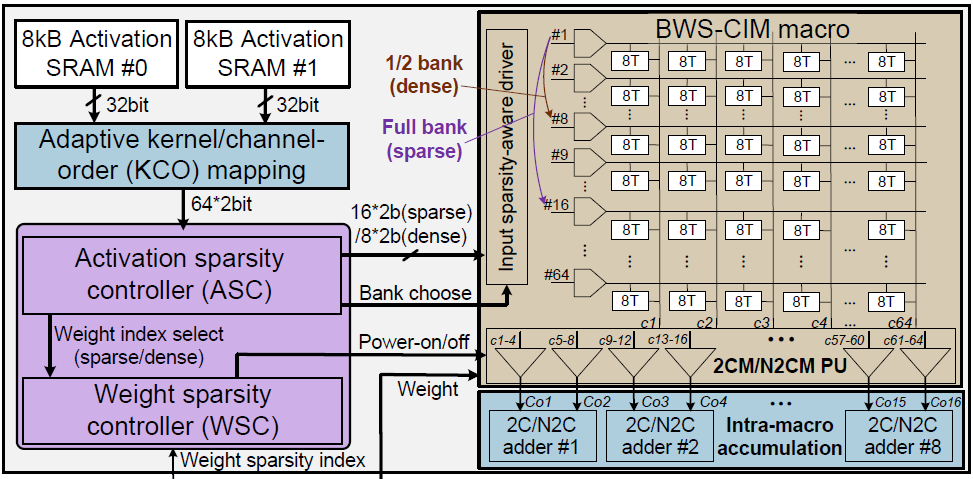
Compiler가 offline으로 각 NN layer에 맞게 KCO mapping을 결정하고, 이에 맞는 instruction을 생성한다. Weight는 mapping에 맞추어 sparse한 형태로 train되며, 각각 sparsity index를 가지고 있다. KCO mapping module은 activation SRAM에서 activation을 fetch하며, activation은 ASC에 의해 all-zero/sparse/dence의 3단계로 구분된다. Fetch된 activation과 weight sparsity index는 BWS-CIM으로 보내지고, 선택된 row가 enable되어 MAC연산을 수행한다. 연산 결과는 intra/inter-marco accumulation module에서 누적된다.
Sparsity
Weight sparsity
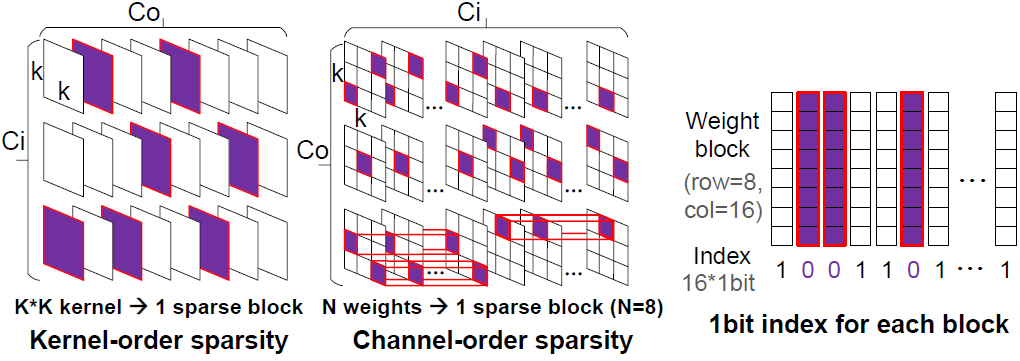
Sparsity은 channel/kernel별로 지원한다. 값이 모두 0인 block을 weight sparse block(WSB)라 하며, WSB의 sparsity index는 1이다.
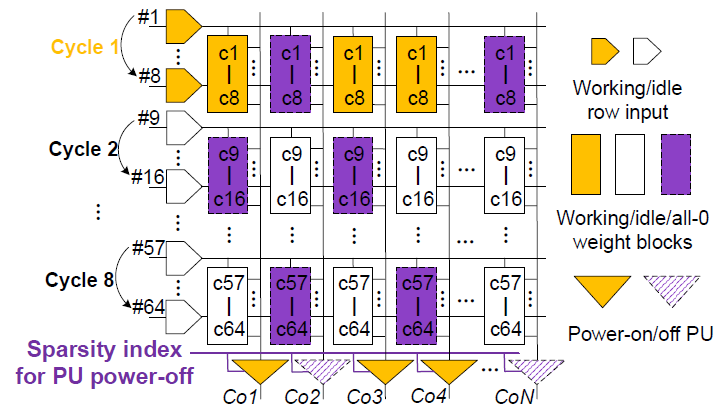
Weight는 column-wise하게 저장되므로, WSB인 column의 MAC result는 input에 상관없이 항상 0이다. 따라서, sparsity index가 1인 WSB는 skip되며 해당하는 PU는 power-off된다.
Activation sparsity
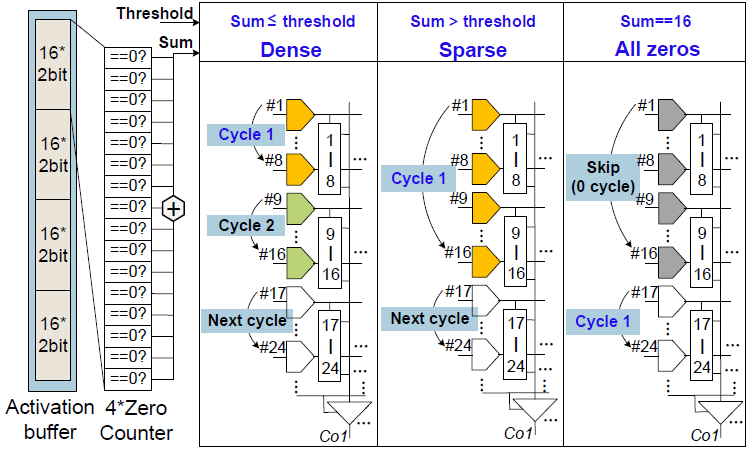
Activation sparsity를 위해 ASC는 activation buffer 내부의 16개의 2b input activation에서 0의 갯수를 계산한다. Input activation은 정해진 threshold에 의해 all-zero/sparse/dense의 3단계로 구분된다. All-zero의 경우 MAC 연산을 수행하지 않는다. Sparse한 경우 ASC는 16개의 row를 enable시키고, dense한 경우 8개의 row를 enable시킨다.
VGG16을 통해 실험한 결과, weight sparsity로 인한 2.4 ~ 1.36x의 PU power reduction과 activation sparsity로 인한 1.24 ~ 2.72x의 speedup을 달성하였다.
Sparsity-sware Weight Block(SWB)
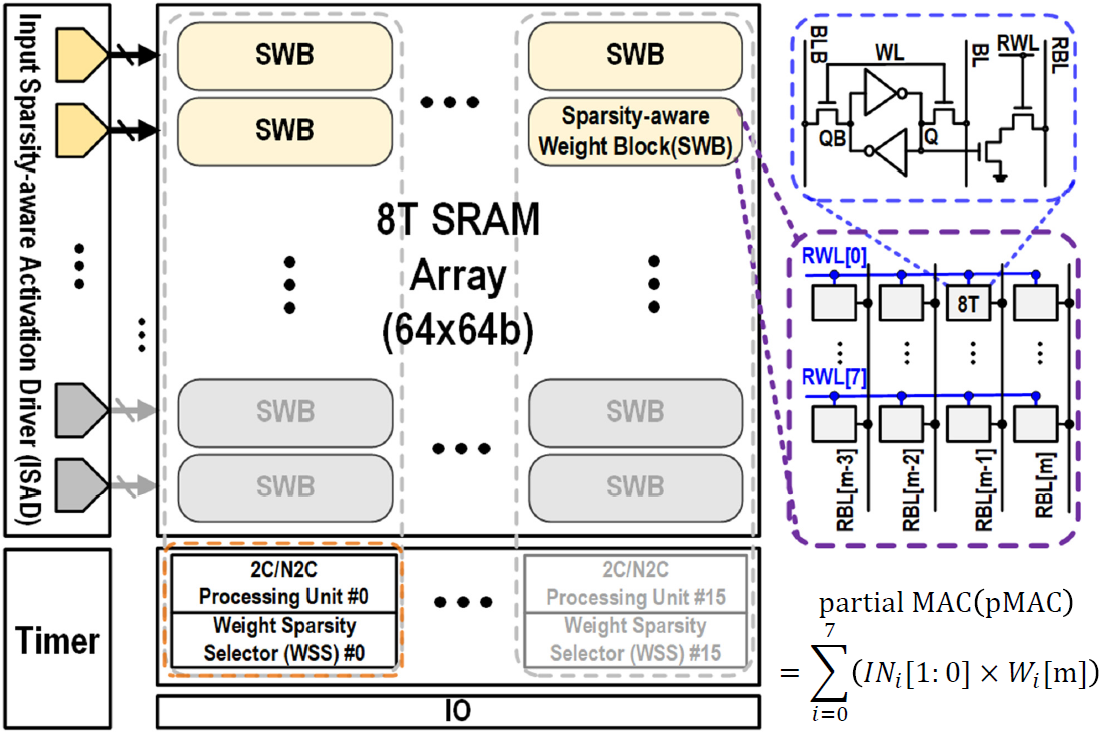
BWS-CIM은 64x64 크기이고, 이는 8x4 크기의 Sparsity-aware Weight Block(SWB)로 나뉘어져 8x16의 SWB로 구성되어있다. SWB가 8개의 row를 가지고 있기에, weight의 sparsity에 따라 한 cycle에 1/2 row의 SWB를 enable시켜 8/16 row를 enable시키는 것 같다. 또한 4b/8b weight를 지원하는데, 각 SWB가 4개의 column을 가지고 있어 weight의 precision에 따라 1/2 column의 SWB를 사용하는 것 같다.
2b input activation은 4단계의 voltage level로 변환되어 weighted SRAM current를 발생시킨다.
Weight mapping
Mapping은 input channel의 수에 따라 channel-order/kernel-order mapping 중에 선택되며, compiler에 의해 strategy가 결정된다.
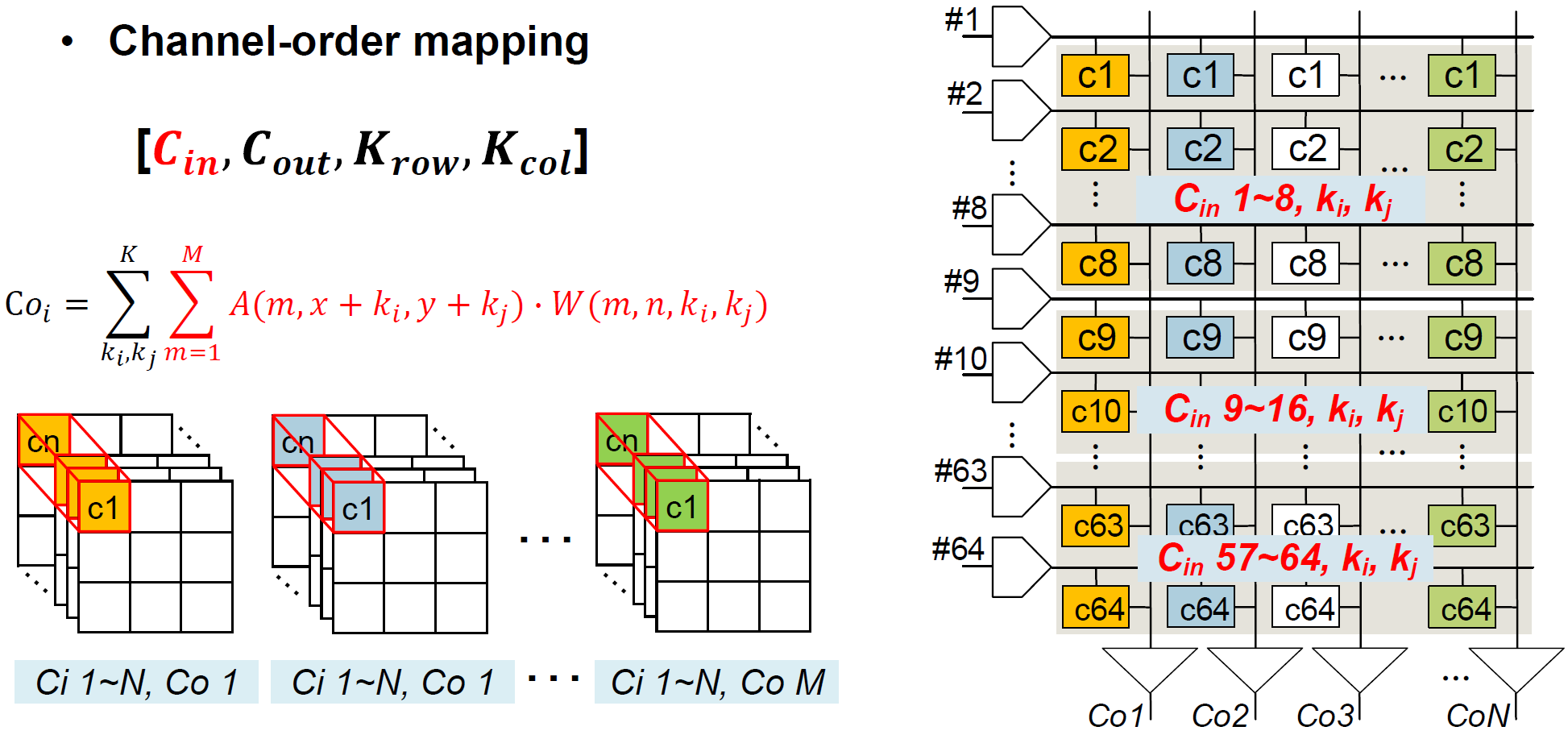
Input channel이 8개 이상인 경우, channel-order mapping을 사용한다. 64개의 column이 존재하고, 3 x 3 kernel을 사용할 경우, input channel별 weight는 9개이어서 이므로, mapping의 기준 input channel은 8개이다. Weight는 row-wise로 input channel별, column-wise로 output-channel별로 저장된다. 따라서, column별로 output channel-wise partial sum이 구해지고, 다음 timestep에서 를 변화시키며 spatial-wise로 partial sum을 누적할 것이다.
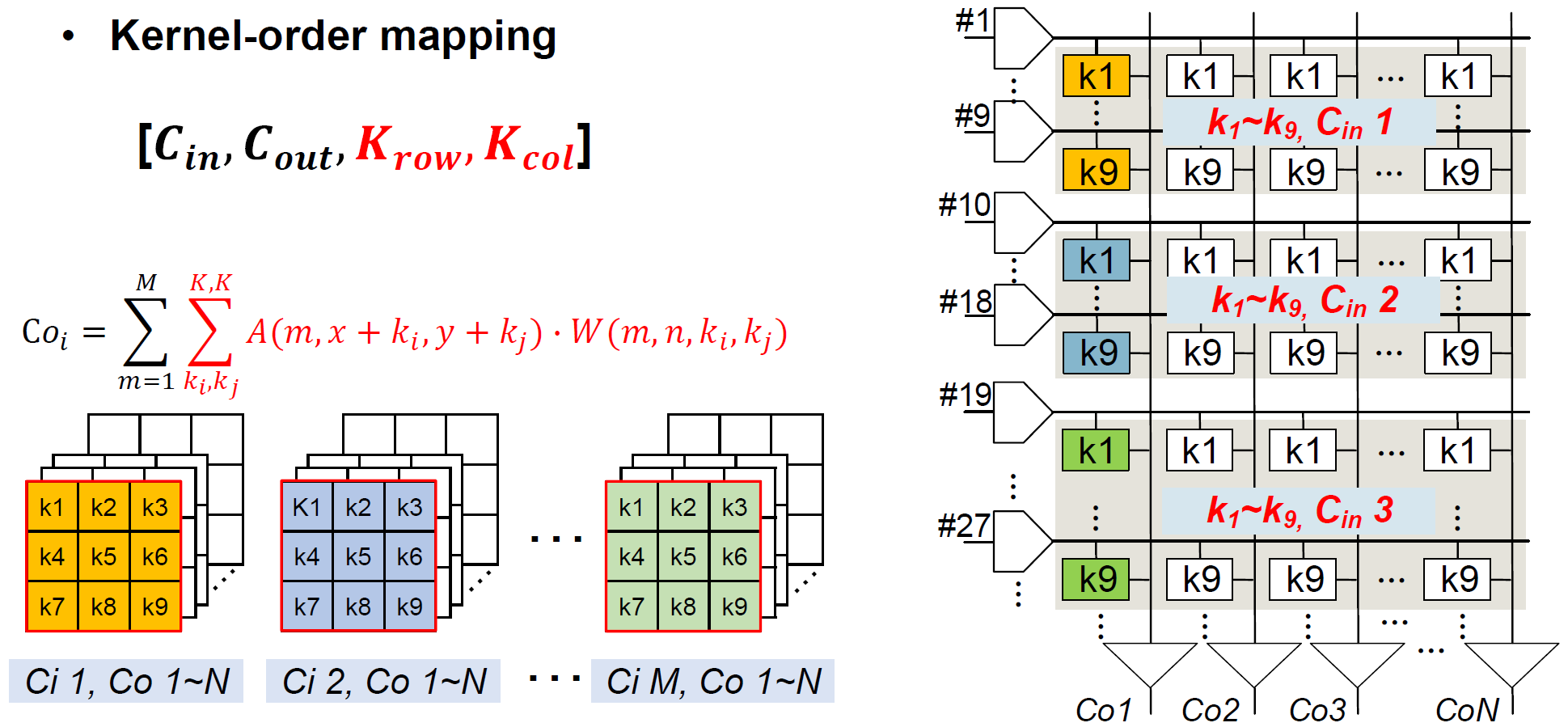
Input channel이 8개 미만인 경우, kernel-order mapping을 사용한다. 3 x 3 kernel을 사용할 경우, weight는 row-wise로 input channel별 9개씩, column-wise로 output-channel별로 저장된다. Kernel-order mapping의 경우에도 column별로 output channel-wise partial sum이 구해진다.
Data reuse
Intra-marco data reuse
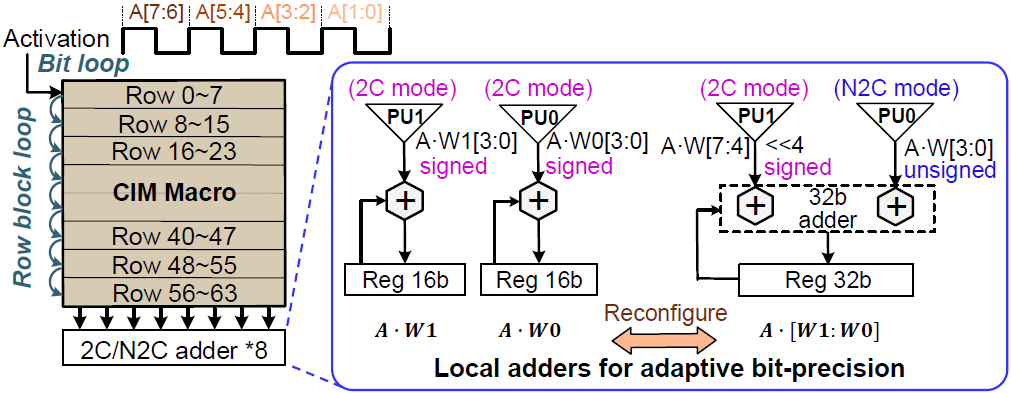
SWB는 4개의 column을 가지고 있으므로, PU도 4개의 column당 1개 존재하는 것 같다. Adder는 2개의 PU output를 입력받아 덧셈을 수행한다. 2 column의 SWB당 2개의 16b adder로 구성되어 있다.
Adder는 2C/N2C(signed/unsigned) mode로 설정할 수 있다. 4b weight인 경우 PU1과 PU0는 다른 weight에 대한 MAC result를 가지고 있다. 따라서, 각 adder는 2C mode로 동작하여 각각 psum을 계산한다. 8b weight인 경우 PU1과 PU0는 같은 weight에 대한 상위/하위 MAC result를 가지고 있다. 따라서, PU1은 2C, PU0는 N2C mode로 동작하여 2개의 16b adder가 1개의 32b adder로 동작한다.
Bit-loop accumulation
Input activation은 2b/4b/6b/8b을 지원한다. 논문의 그림상으로는 1 cycle에 2b의 input activation에 대한 연산을 수행하는 것 같고, 따라서 8b의 activation의 경우 연산에 4 cycle이 필요한 것 같다.
2b/4b/6b/8b activation에 대한 MAC result는 각각 0b/2b/4b/6b left-shift된 후 adder를 통해 output을 construction한다.
Row-block-loop accumulation
64 row에 대한 MAC result를 accumulate한다.
Inter-macro data reuse
여러 core에서 동시에 연산된 activation/kernel/channel psum을 accumulate한다.
Intra-macro data reuse를 통해 next-level memory access는 약 7.9x 감소하였고, inter-macro data reuse도 같이 사용한 경우 약 17.6x 감소하였다.
Macro utilization은 adaptive KCO mapping에 의해 향상될 수 있다. Channel이 많은 layer의 경우, 2의 지수승의 row를 enable시켜 channel-order mapping을 사용할 수 있다. Channel이 적은 layer의 경우, channel-order mapping이 비효율적이기 때문에 kernel-order mapping을 사용할 수 있다. 그러나 kernel-order mapping의 경우 3 channel/3x3 kernel에 대해서는 27 row만 enable시킬 수 있다. 이를 해결하기 위해 KCO mapping scheduler가 64x64 macro를 2개의 bank로 나누어 각각 다른 output channel에 대한 연산을 수행하여 54 row를 enable시킬 수 있다. 이러한 adaptive KCO mapping module로 인해 CIM macro utilization은 channel-order mapping 대비 42%, kernel-order mapping 대비 2.8 ~ 11% 향상되었다.
Metrics