An Energy-Efficient Deep Reinforcement Learning Accelerator With Transposable PE Array and Experience Compression
Problem to solve
- Batch size와 output channel에 따라 IF(Input Feature) reuse와 W(Weight) reuse 중 하나가 더 효율적이다
- Actor와 learner가 다른 data reuse pattern을 가진다
- DRL은 inference에 비해 required memory bandwidth가 더 크다
How to solve
- Transposable PE(tPE)로 IF, W reuse를 모두 지원.
- Learner의 experience와 partial product를 compress.
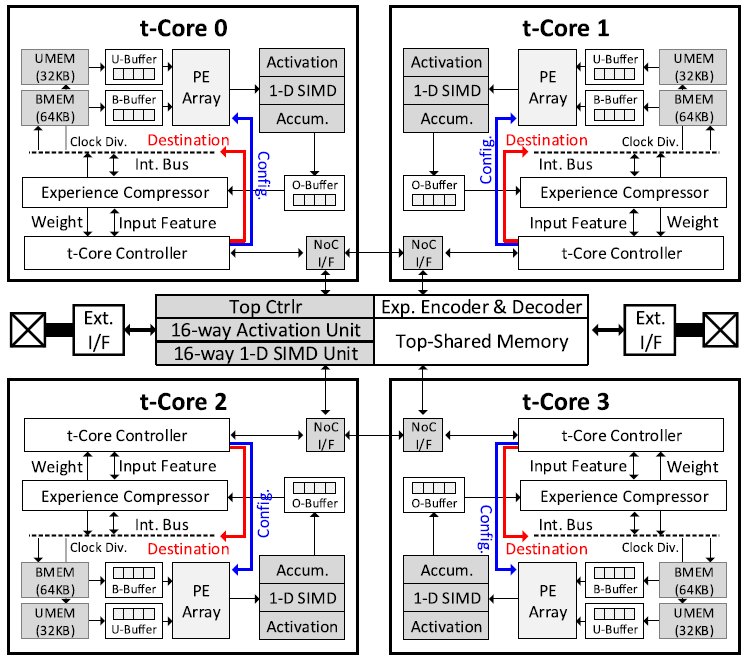
Experience compression
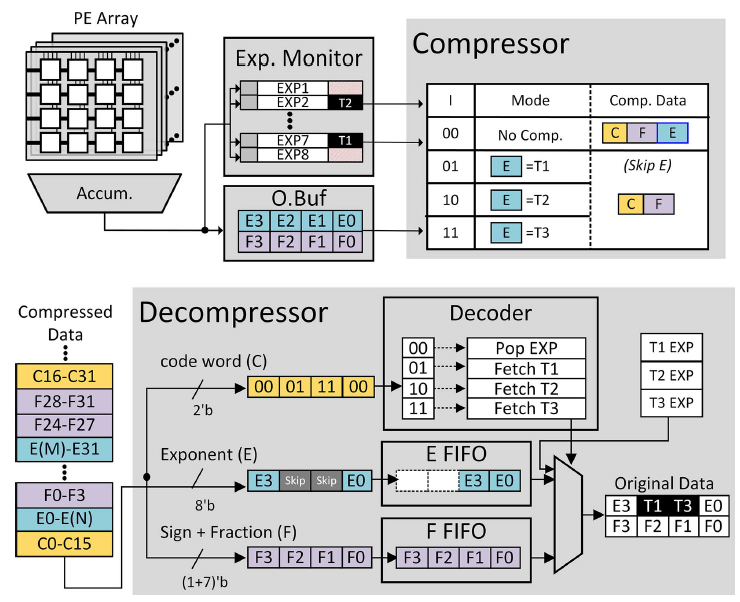
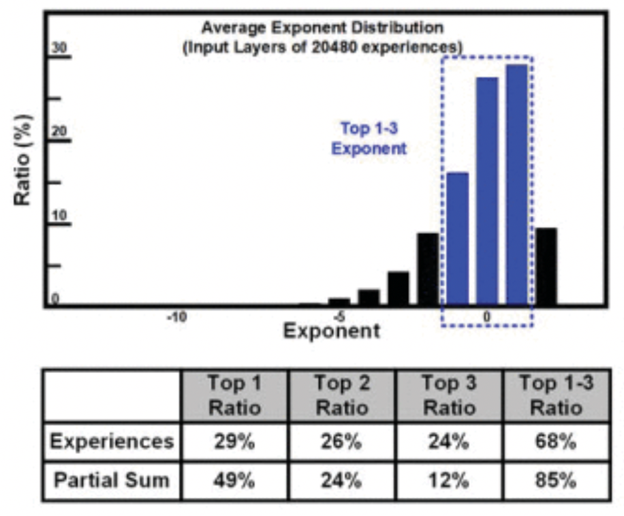
bFloat16으로 표현되는 input activation의 exponent는 위의 그림과 같이 좁은 영역에 집중되어 있다. 2b code를 사용하여 input activation이 encode되었는지를 나타낸다. 코드 00은 exponent가 top-3에 포함되지 않아 encode되지 않았음을 나타낸다. 코드 01, 10, 11은 각각 top1, top2, top3 exponent로 encode됨을 의미한다.
PE array가 연산을 수행하는 동안, experience buffer는 output buffer를 확인하여 top-3 exponent를 확인한다. 연산이 끝나면, compressor는 output buffer 내부의 data들을 compress한다.
다음 연산에서는 decompressor를 통해 원래의 값으로 복원한다.
Transposable PE(tPE)
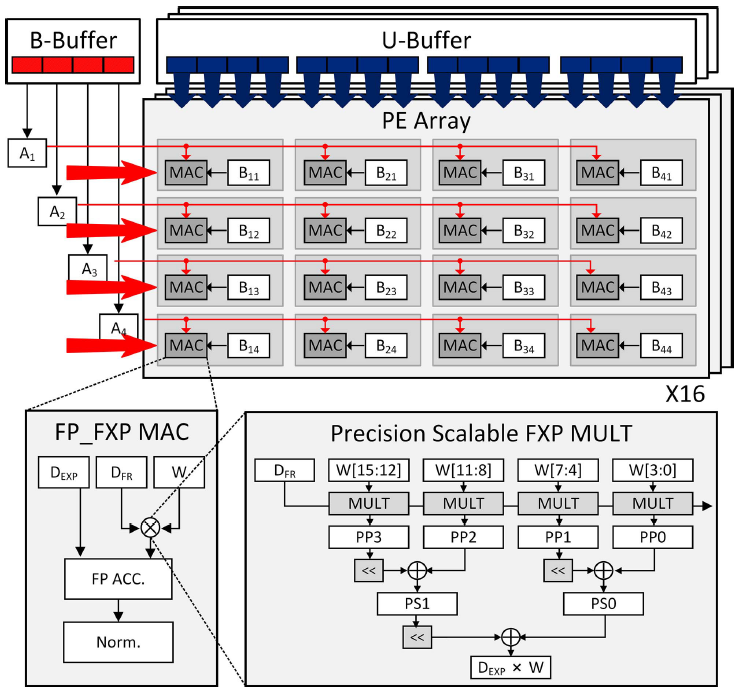
16개의 4x4 tPE array은 Broadcast buffer와 Unicast buffer로 부터 데이터를 입력받는다. Unicast buffer는 각 PE마다 데이터를 뿌려주며, Broadcast buffer는 각 row마다 데이터를 뿌려주는 row buffer 역할을 수행한다.
Broadcase buffer는 매 cycle마다 데이터를 뿌려주며, 연산이 끝나면 unicast buffer가 새로운 데이터를 뿌려준다.
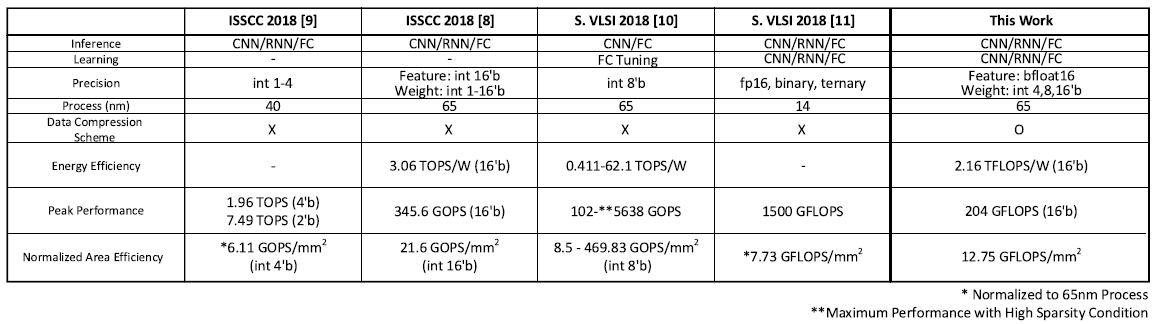
Comparison table