An Energy-Efficient Deep Reinforcement Learning FPGA Accelerator for Online Fast Adaptation with Selective Mixed-precision Re-training
0
Problems to solve
- Experience gathering 때문에 DRL finetuning의 workload 감소가 어렵다
- Selective retraining(SELRET)이 앞쪽 layer에 대해 수행되므로, computation reduction이 제한적이다.
How to solve
- Heterogeneous Replay Buffer(HRB)를 사용하여 이전 workload에 대한 experience도 활용
- Mixed-Precision Selective Retraining(MP-SELRET)으로, retraining layer 이전의 연산은 FP32로, 이후 연산은 FXP16으로 수행
Heterogeneous Replay Buffer(HRB)
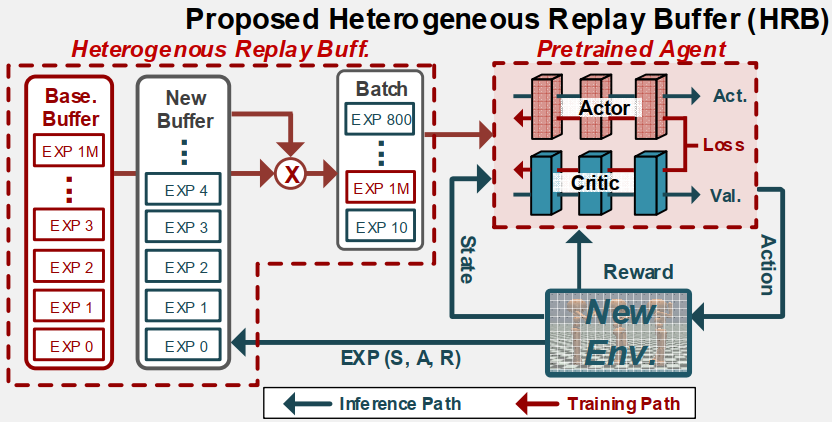
HRB는 baseline buffer와 new buffer로 나뉜다. Baseline buffer는 baseline workload에 대한 experience를 갖고 있으며, 새로운 환경에 대한 experience는 new buffer에 저장된다.
Training시에는 baseline buffer와 new buffer 모두에서 experience를 sampling하여 사용한다.
HRB를 사용함으로써 training iteration이 80~88% 감소하였다.
Mixed-Precision Selective Retraining(MP-SELRET)
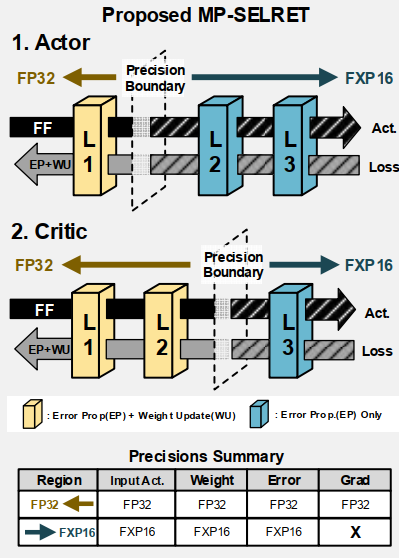
기존 SELRET 논문의 아이디어를 확장한 논문이다. SELRET과 같이 한 layer를 정하여 해당 layer만 WU를 수행하며, 해당 layer 이후의 layer들은 EP만 수행한다.
MP-SELRET는 SELRET을 확장하여, training layer 이전의 layer들은 FP32로 연산을 수행하고, 이후 layer들은 FXP16으로 연산을 수행한다.
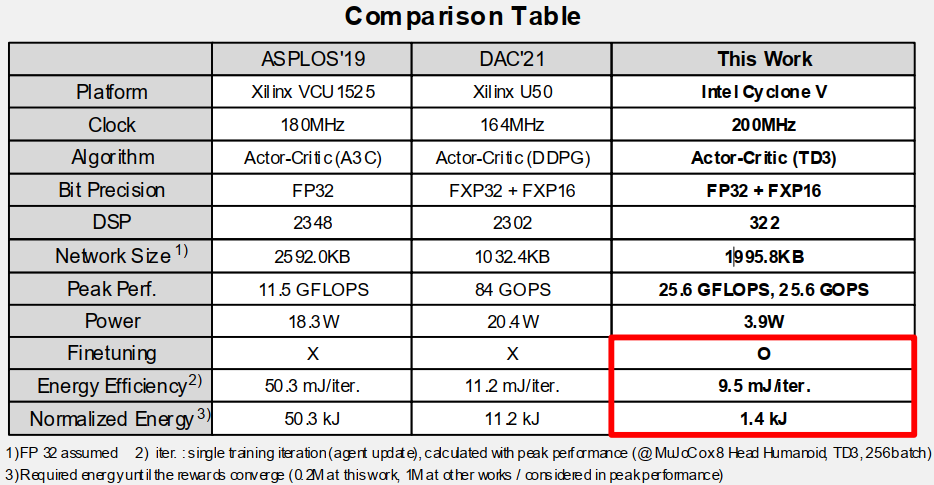
Comparison Table
Reference
[1] S. Kim, S. Kang, D. Han, S. Kim, S. Kim and H. -j. Yoo, "An Energy-Efficient GAN Accelerator with On-chip Training for Domain Specific Optimization," 2020 IEEE Asian Solid-State Circuits Conference (A-SSCC), Hiroshima, Japan, 2020, pp. 1-4, doi: 10.1109/A-SSCC48613.2020.9336128.
