FIXAR: A Fixed-Point Deep Reinforcement Learning Platform with Quantization-Aware Training and Adaptive Parallelism
Problems to solve
- DRL은 training accuracy를 위해 여전히 FP16을 사용하고 있음.
How to solve
- Fixed-point QAT algorithm
- QAT를 지원하는 configurable PE
FIXAR
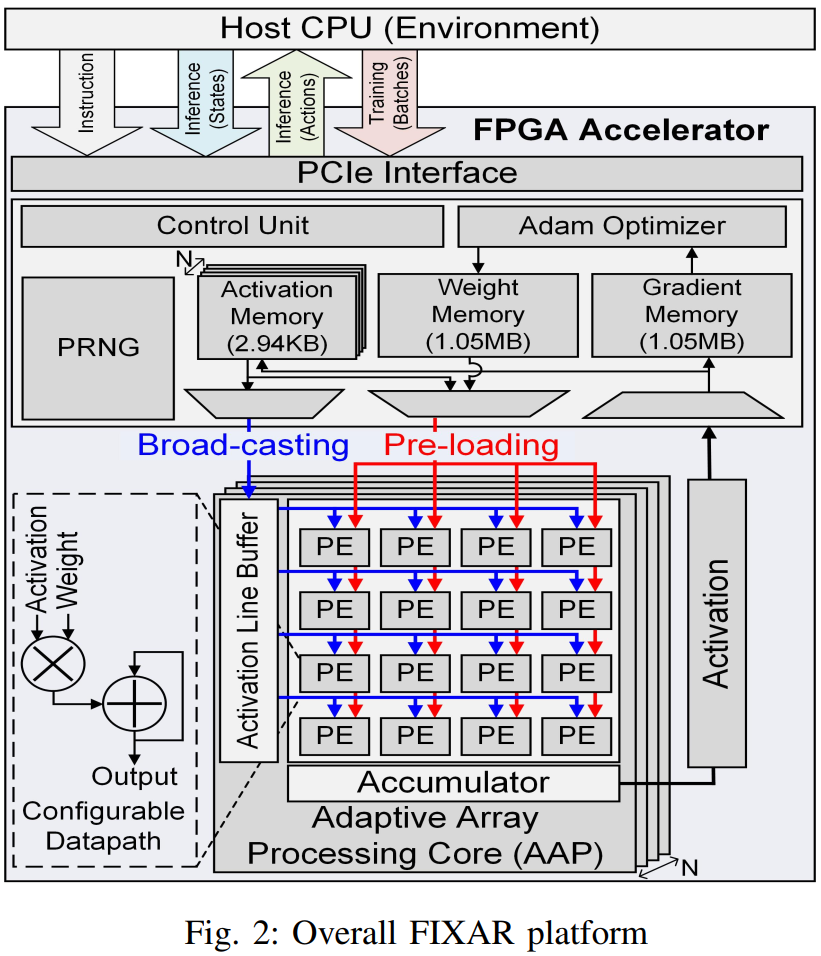
FIXAR는 N개의 AAP(Adaptive Array Processing) core로 구성되어 있고, 각 AAP는 4x4 PE array로 구성되어있다.
Activation line buffer가 activation을 row-wise로 broadcast하며, weight는 각 pe에 unicast된다. Partial sum은 column-wise로 accumulate된다.
Dataflow
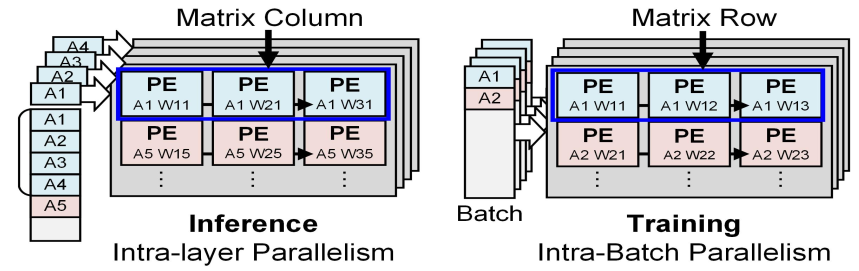
Inference 시에는 개의 AAP에 하나의 batch에 속하는 activation을 뿌려주며 각 AAP 내부에서는 의 activation을 row-wise로 broadcast한다. 이러한 dataflow로 인해 하나의 batch를 배 빠르게 처리할 수 있다.
Training 시에는 각 AAP가 하나의 batch를 처리하며, 각 AAP 내부에서는 각 배치의 의 activation을 row-wise로 broadcast한다. 이러한 dataflow로 인해 개의 batch를 한번에 처리할 수 있다.
Weight Memory
Weight memory는 16개의 bank로 구성되어 있고, 사이클당 512b read/16b write가 가능하다. Inferece 시에는 weight를 읽어 PE array에 16개의 weight를 unicast하며, training 시에는 index를 transpose하여 16개의 weight를 unicast한다.
PE w/ Configurable Datapath
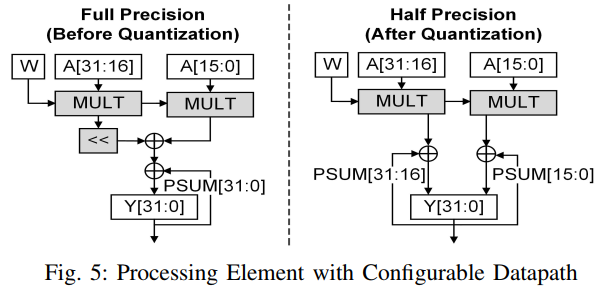
AAP는 256개의 FXP PE로 구성되어 있다. 각 PE는 FXP32와 FXP16 연산을 모두 지원하기 위해 두개의 FXP16 datapath로 구성이 되어있다. FXP32 mode에서는 상위 bit 연산결과가 shift left되어 하위 bit 연산결과에 더해지며, FXP16 mode에서는 2개의 partial sum이 독립적으로 계산된다.
Dynamic Fixed-Point Quantization
QuaRL의 QAT 알고리즘을 기반으로 quantization을 수행했으며, QuaRL의 경우 FP32로 training 하다가 quantization delay 이후에 FP16으로 quantize하는데, 본 논문에서는 FXP32으로 training 하다가 quantization delay 이후에 FXP16으로 quantize한다.
Quantization delay 이후에도 activation은 FXP16을 사용하지만, weight와 gradient는 FXP32를 사용한다.
Comparison Table
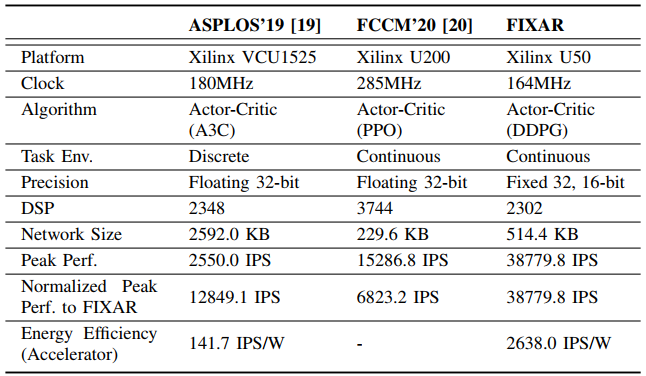
Reference
[1] S. Krishnan, S. Chitlangia, M. Lam, Z. Wan, A. Faust, and V. J.
Reddi, “Quantized reinforcement learning (quarl),” arXiv preprint
arXiv:1910.01055, 2019
