일자 : 10주차 2차시
[1] MySQL이란?
- MySQL은 관계형 데이터베이스 관리 시스템이다.
- MySQL은 오픈 소스이다.
- MySQL은 무료로 제공된다.
- MySQL은 소규모 애플리케이션부터 대규모 애플리케이션까지 적합하다.
- MySQL은 매우 빠르고 신뢰할 수 있으며 확장 가능하고 사용하기 쉽다.
- MySQL은 여러 플랫폼에서 사용할 수 있다.
- MySQL은 ANSI SQL 표준을 준수한다.
- MySQL은 1995년에 처음 출시되었다.
- MySQL은 Oracle Corporation에서 개발, 배포, 지원한다.
- MySQL 이름은 공동 설립자인 Monty Widenius의 딸 이름(My)에서 따왔다.
[2] RDBMS란?
- RDBMS는 Relational Database Management System(관계형 데이터베이스 관리 시스템)을 의미한다.
- RDBMS는 관계형 데이터베이스를 관리하는 프로그램이다.
- RDBMS는 MySQL, Microsoft SQL Server, Oracle, Microsoft Access와 같은 모든 현대 데이터베이스 시스템의 기반이다.
- RDBMS는 SQL 쿼리를 사용해 데이터베이스의 데이터를 액세스한다.
[3] 데이터베이스 테이블이란?
- 테이블은 관련된 데이터 항목의 모음으로 열(Column)과 행(Row)으로 구성된다.
- 열(Column)은 테이블의 각 레코드에 대한 특정 정보를 저장한다.
- 행(Row) 또는 레코드는 테이블에 존재하는 각 개별 항목이다.
1) 예시
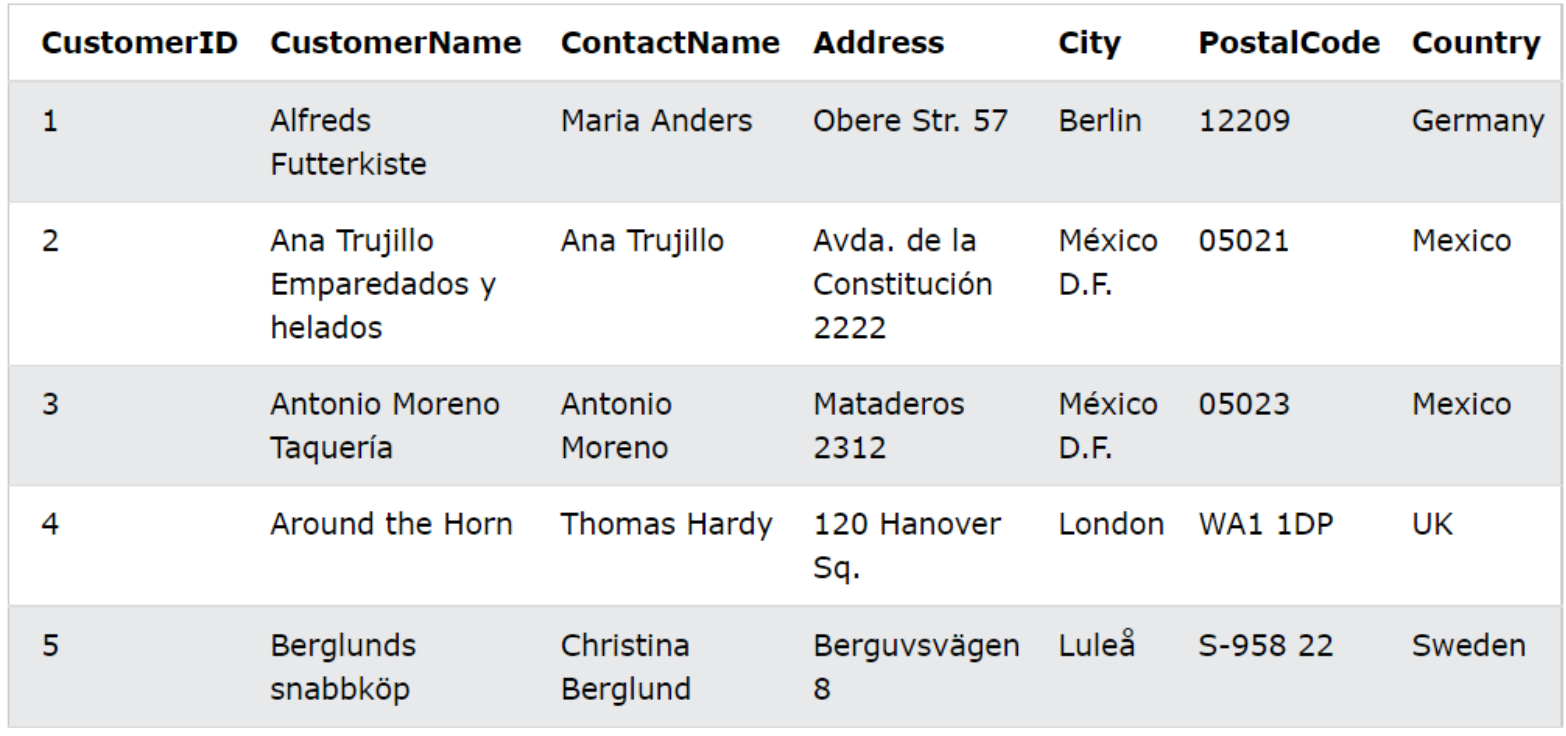
[4] 관계형 데이터베이스란?
관계형 데이터베이스는 테이블 형식으로 데이터베이스 간의 관계를 정의한다. 테이블들은 공통 데이터를 기반으로 서로 연결된다.
1) Customers 테이블

CREATE TABLE Customers (
CustomerID INT(10) NOT NULL AUTO_INCREMENT, -- 고객 ID, 자동 증가 및 기본 키
CustomerName VARCHAR(50) NOT NULL, -- 고객 이름
ContactName VARCHAR(50) NULL, -- 연락처 이름
Address VARCHAR(50) NULL, -- 주소
City VARCHAR(50) NULL, -- 도시
PostalCode INT(10) NULL, -- 우편번호
Country VARCHAR(50) NULL, -- 국가
CONSTRAINT Customers_PK PRIMARY KEY (CustomerID) -- 기본 키 제약 조건 설정
);
2) Shippers 테이블
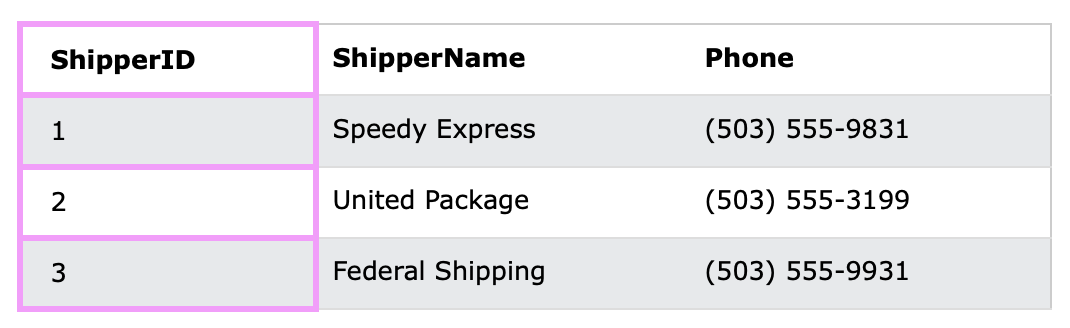
- "Orders" 테이블과 "Shippers" 테이블 간의 관계는 ShipperID 열에 기반을 둔다.
CREATE TABLE Shippers (
ShipperID INT(10) NOT NULL AUTO_INCREMENT, -- 배달업체 ID, 자동 증가 및 기본 키
ShipperName VARCHAR(50) NOT NULL, -- 배달업체 이름
Phone VARCHAR(50) NOT NULL, -- 전화번호
CONSTRAINT Shippers_PK PRIMARY KEY (ShipperID) -- 기본 키 제약 조건 설정
);3) Orders 테이블
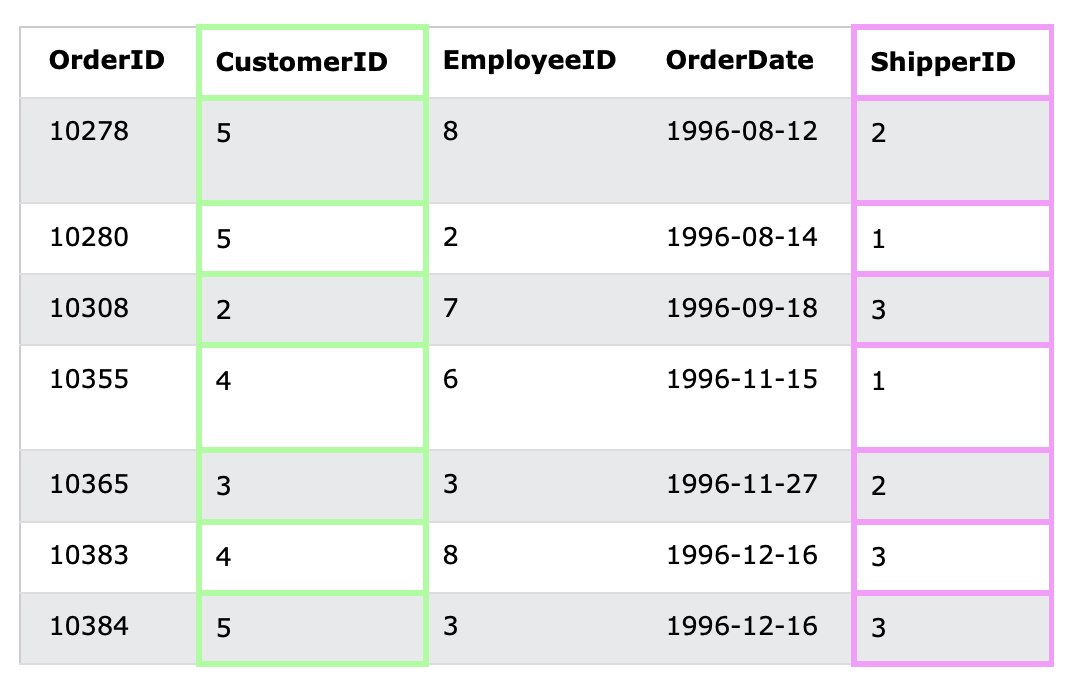
- "Customers" 테이블과 "Orders" 테이블 간의 관계는 CustomerID 열에 기반을 둔다.
CREATE TABLE Orders (
OrderID INT(10) NOT NULL AUTO_INCREMENT, -- 주문 ID, 자동 증가 및 기본 키
CustomerID INT(10) NOT NULL, -- 고객 ID, 외래 키
EmployeeID INT(10) NOT NULL, -- 직원 ID
OrderDate DATE NOT NULL, -- 주문 날짜
ShipperID INT(10) NOT NULL, -- 배달업체 ID, 외래 키
CONSTRAINT Orders_PK PRIMARY KEY (OrderID), -- 기본 키 제약 조건 설정
CONSTRAINT Orders_CustomerID_FK FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID), -- 외래 키 제약 조건
CONSTRAINT Orders_ShipperID_FK FOREIGN KEY (ShipperID) REFERENCES Shippers(ShipperID) -- 외래 키 제약 조건
);
[5-1] SQL - SELECT
1) SELECT ALL
SELECT * FROM {테이블명};- 전체 데이터를 선택할 때 사용한다. 모든 컬럼의 데이터를 반환한다.
2) SELECT Column
SELECT {컬럼명}, {컬럼명} FROM {테이블명};- 특정 컬럼만 선택하여 데이터를 조회할 때 사용한다. 반환되는 결과에는 지정한 컬럼의 데이터만 포함된다.
3) SELECT with DISTINCT
: 중복된 데이터를 제거하고 고유한 값만 선택할 때 사용한다. 예를 들어, 특정 컬럼에 있는 모든 고유한 값의 목록을 가져올 수 있다.
SELECT DISTINCT {컬럼명} FROM {테이블명};개수 사용 : COUNT()
SELECT COUNT(DISTINCT {컬럼명}) FROM {테이블명};
- 특정 컬럼의 고유한 값의 개수를 세는 데 사용한다.
4) SELECT with WHERE
: 특정 조건을 만족하는 데이터만 선택할 때 사용한다. 조건에 맞는 레코드만 반환되며, 데이터 필터링에 유용하다.
SELECT * FROM {테이블명} WHERE {조건}- 조건 예시 : WHERE Country = 'Country A'
- Operators in The WHERE Clause
=: 두 값이 같음을 의미한다.>: 왼쪽 값이 오른쪽 값보다 큼을 의미한다.<: 왼쪽 값이 오른쪽 값보다 작음을 의미한다.>=: 왼쪽 값이 오른쪽 값보다 크거나 같음을 의미한다.<=: 왼쪽 값이 오른쪽 값보다 작거나 같음을 의미한다.<>: 두 값이 같지 않음을 의미한다.BETWEEN: 특정 범위 내의 값을 의미하며, 시작 값과 끝 값 모두 포함된다.LIKE: 특정 패턴과 일치하는 값을 찾을 때 사용하며, 일반적으로 와일드카드 문자(예:%,_)와 함께 사용된다.IN: 지정된 값 목록 중 하나와 일치하는 값을 찾을 때 사용한다.
- 조건 여러 개 예시
- WHERE Country = 'Country A' AND City = 'City A'; -- 두 조건 모두 만족해야 함
- WHERE Country = 'Country A' AND NOT City = 'City A'; -- 첫 번째 조건은 만족하되 두 번째 조건은 만족하지 않아야 함
5) ORDER BY
: 결과 집합을 특정 컬럼을 기준으로 정렬할 때 사용한다. 기본적으로 오름차순으로 정렬되지만, 내림차순으로도 정렬할 수 있다.
SELECT * FROM {테이블명} ORDER BY {컬럼명} {정렬 조건}- 정렬 조건
- DESC : 내림차순으로 정렬한다. 큰 값에서 작은 값으로 정렬된다.
- ASC : 오름차순으로 정렬한다. 작은 값에서 큰 값으로 정렬된다.
- 컬럼 별로 다르게 정렬하는 예시
- ORDER BY Country ASC, CustomerName DESC
- Country를 기준으로 오름차순 정렬하고, 같은 Country 내에서는 CustomerName을 기준으로 내림차순 정렬한다.
- ORDER BY Country ASC, CustomerName DESC
[5-2] SQL - INSERT
1) INSERT
INSERT INTO {테이블명} (컬럼명, 컬럼명) VALUES ('데이터값', '데이터값');- 정수: 정수는 작은 따옴표 없이 입력한다.
- 예: INSERT INTO table_name (integer_column) VALUES (123);
- 소수: 소수(부동 소수점 숫자)도 작은 따옴표 없이 입력한다.
- 예: INSERT INTO table_name (float_column) VALUES (45.67);
- 문자열: 문자열, 날짜, 시간 등은 반드시 작은 따옴표로 감싸야 한다.
- 예: INSERT INTO table_name (string_column) VALUES ('Hello, World!');
- NULL: NULL 값은 따옴표 없이 입력한다.
- 예: INSERT INTO table_name (nullable_column) VALUES (NULL);
- Boolean: 불리언값은 따옴표 없이 0(false), 1(true)로 입력한다.
- 예: INSERT INTO table_name (bool_column) VALUES (1);
2) NULL 값이란 무엇인가?
-
NULL 값이 있는 필드는 값이 없는 필드이다.
-
테이블의 필드가 선택적일 경우, 이 필드에 값을 추가하지 않고 새 레코드를 삽입하거나 레코드를 업데이트할 수 있다. 그러면 이 필드는 NULL 값으로 저장된다.
-
주의: NULL 값은 0 값이나 공백이 포함된 필드와 다르다. NULL 값이 있는 필드는 레코드 생성 시 비워 둔 필드이다!
[5-3] SQL - UPDATE
UPDATE {테이블명} SET {컬럼명} = {값}, {컬럼명} = {값} WHERE {조건}1) 여러 레코드 업데이트
- 업데이트될 레코드 수를 결정하는 것은
WHERE절이다.
2) 업데이트 경고!
- 레코드를 업데이트할 때 주의해야 한다.
WHERE절을 생략하면 모든 레코드가 업데이트된다!
아래는 SQL - DELETE에 대한 설명이다.
[5-4] SQL - DELETE
DELETE문은 테이블에서 기존 레코드를 삭제하는 데 사용된다.
DELETE FROM {테이블명} WHERE {조건}1) 모든 레코드 삭제
- 테이블을 삭제하지 않고 테이블의 모든 행을 삭제할 수 있다. 이는 테이블 구조, 속성 및 인덱스는 그대로 유지된다는 것을 의미한다:
DELETE FROM {테이블명};

안녕하세요, 사용자들의 문제 해결을 중심으로 하는 프론트엔드 개발자입니다. 티스토리로 전환했어요 : https://pangil-log.tistory.com