MySQL
1.MySQL < Select >
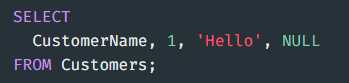
💡 테이블의 컬럼이 아닌 값도 선택할 수 있습니다.\-> 1번째 정렬 우선순위 ProductID, 2번째 정렬 순위 Quantity LIMIT {가져올 갯수} , LIMIT {건너뛸 갯수}, {가져올 갯수} AS 를 사용하여 Column(열)명을 변경할 수 있다
2.MySQL < 연산자 >
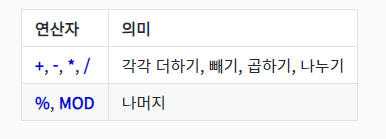
❗ 문자열에 사칙연산을 가하면 0으로 인식1번 결과는 0+3 = 32번 결과는 0\*3 = 0\-> 숫자로 구성된 문자열은 숫자로 자동인식 : 3\*2+1 = 7\-> OrderID, ProductID 행이 더해진 결과가 나온다\-> 0 = TRUE : 거짓이기 때문에
3.MySQL < 숫자 ,문자열 다루는 함수들 >
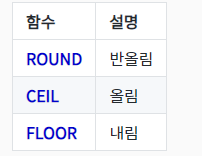
\-> 결과 : 1, 1, 0\-> 결과 : 1, 1, 7\-> OrderDetails 테이블에서 Quantity-10 의 절대값이 5보다 작은 항목 출력\-> 결과 : 3, 1\-> OrderDetailID 가 20과 30사이에 있는 항목중 Quantity 항목의 각
4.MySQL < 시간/날짜 관련 및 IF 함수 >
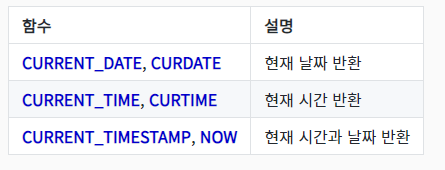
\-> 결과 : 날짜 , 시간 , 날짜 + 시간 \-> 결과 : False , True , False , True\-> 결과 : False , True , True , False, True, True\-> 결과 : 년도/월/일 / 요일 왼쪽 3글자(ex. THU)\-
5.MySQL < 조건에 따라 그룹으로 묶기 >
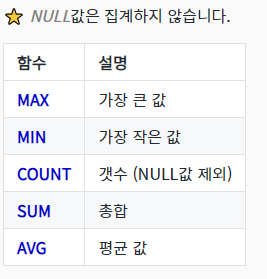
보통 그룹화는 MySQL에서 유형별로 개수를 가져오고 싶을 때 , 단순히 COUNT 함수로는 전체 데이터의 개수만 가져오기 때문에 유형별 개수가 필요할 때 GROUP BY를 이용\-> Country 를 그룹화 해준다\-> CategoryID 를 그룹화해줌 ( 1 ~ 8
6.MySQL <쿼리 안에 서브쿼리 >
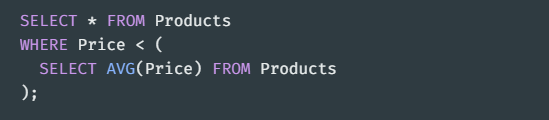
서브쿼리가 본 쿼리와 상관없이 독립적으로 돌아가는 것\-> Products 에서 모든 데이터를 가져오는데, 서브쿼리로 Products의 평균 Price로 조건을 걸어서 출력한다.\-> CategoryID = 2인 것들의 가격보다 큰 (= 젤 높은 값보다 큰) 녀석
7.MySQL < JOIN >

양쪽 모두에 값이 있는 행(NOT NULL) 반환'INNER'는 선택사항교집합이라고 표현 데이터의 중복을 피하기 위하여 관계형 데이터베이스에서 테이블을 나누지만 , JOIN은 이를 적절하게 합쳐주는 역할을 한다.\-> C.CategoryID = P.CategoryID
8.MySQL < UNION >
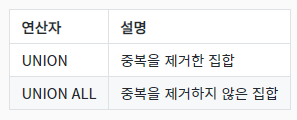
\-> Customers 테이블과 Suppliers 테이블을 중복을 제거하여 합친 결과를 출력\-> UNION ALL 로 바꾸면 중복되는 값도 모두 출력된다.
9.MySQL < 테이블 생성 , 입력 및 기능 >
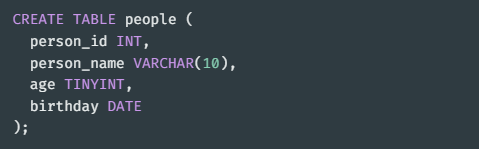
\-> 컬럼명 자료형 , \-> INSERT INTO 테이블명 (컬럼명 , 컬럼명.. ) VALUES(삽입 값 , 삽입 값 ... ) person_id : AUTO_INCREMENT(새 행 생성시 자동으로 1씩증가), PRIMARY KEY(중복 입력 불가 , NULL(
10.MySQL < 자료형 >
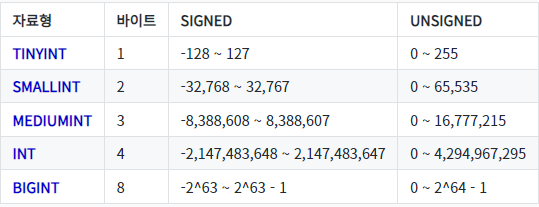
좁은 범위의 수 표현 가능 , 정확한 값 넓은 범위의 수 표현 가능 , 정확하지 않은 값 (일반적으로 충분히 정확)검색시 CHAR가 더 빠름VARCHAR 컬럼 길이값이 4글자보다 적을 경우 CHAR로 자동 변환시간 데이터를 가감없이 기록할 때 DATETIME시간 자동기
11.MySQL < 데이터 변경 , 삭제 >

해당 데이터를 삽입한다고 했을 때, DELETE는 단순히 테이블내의 행을 모두 지운 것이기 때문에 PRIMARY KEY의 AUTO_INCREMENT 기능이 가장 마지막의 값을 기억하고 있고 , 삽입을 했을 시에 해당 값의 다음값으로 다시 적용이 되어 id가 설정된다 하
12.MySQL < WITH >
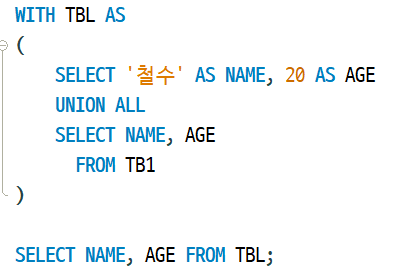
WITH > 가상 테이블 생성 ❗❗❗ WITH 절을 너무 남발하게 되면 임시테이블이 견딜 수 있는 정도가 넘어가 오히려 느려진다.