GROUP BY - 조건에 따라 집계된 값 가져온다.
보통 그룹화는 MySQL에서 유형별로 개수를 가져오고 싶을 때 , 단순히 COUNT 함수로는 전체 데이터의 개수만 가져오기 때문에 유형별 개수가 필요할 때 GROUP BY를 이용
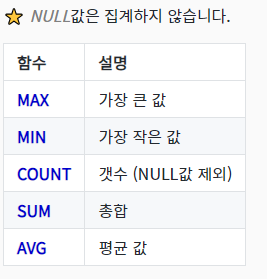

-> Country 를 그룹화 해준다


-> CategoryID 를 그룹화해줌 ( 1 ~ 8 까지 있음 )
💡 여러 컬럼을 기준으로 그룹화할 수도 있습니다.
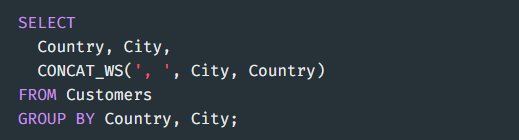
두 개의 컬럼을 그룹으로 묶는다면 나올 수 있는 경우의 수가 다 나옴
ex. 지역과 성별 두개의 컬럼이 있다고 하면
GROUP BY 지역 , 성별 이라 한다면 경우의 수는
서울/남성 , 서울/여성 , 경기도/남성 , 경기도/여성 과 같이 나온다
📚 그룹 함수 활용하기
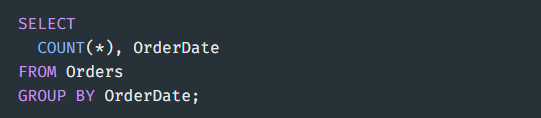
-> OrderDate의 각 case에 따른 count 개수 출력
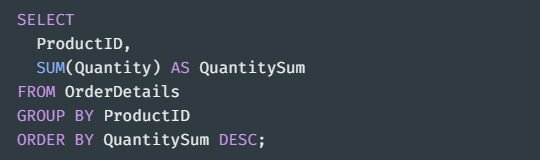
-> ProductID와 QuantitySum 컬럼을 그룹화하여 각 ProductID에 대한 QuantitySum을 내림차순으로 정렬하여 출력한다
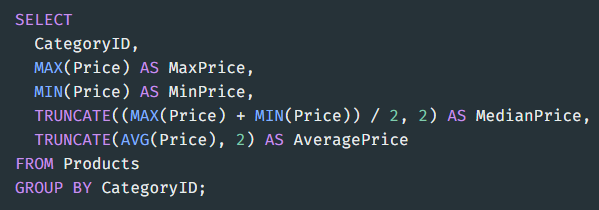
- MaxPrice : 가장 높은 가격
- MinPrice : 가장 낮은 가격
- MedianPrice : 중간 값의 가격 , 소숫점 2자리 까지 표현(버림)
- AveragePrice : 평균 가격
CategoryID 를 그룹화하여 각 케이스별로 위의 4가지 컬럼을 출력
-> Country마다 올 수 있는 City의 경우로 그룹화되어 출력
💡 WITH ROLLUP - 전체의 집계값

- ⚠️ ORDER BY 는 함께 사용될 수 없다!!!!
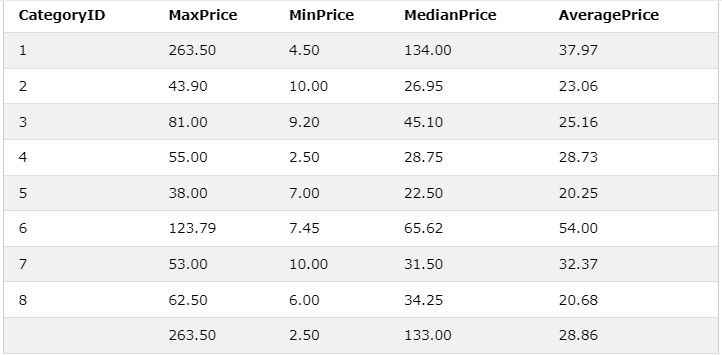
-> 다음과 같이 맨 아래에 집계값이 표현된다
HAVING - 그룹화된 데이터 걸러내기 ( 조건 )
HAVING은 그룹화를 한 후에 조건을 걸어줄 때 주로 사용합니다.
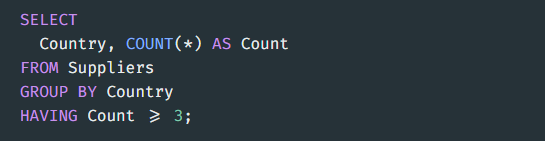
-> Count가 3보다 크거나 같은 항목만 출력
💡 WHERE는 그룹하기 전 데이터, HAVING은 그룹 후 집계에 사용합니다.
WHERE와 HAVING 을 혼동하지 말자 !
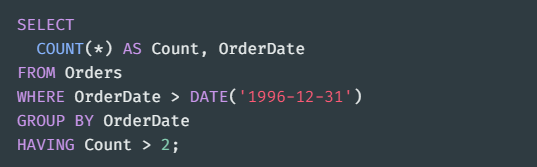
-> WHERE는 GROUP BY 전 데이터 , HAVING은 GROUP BY 후 데이터

-> CategoryID 가 2보다 크고 , AveragePrice BETWEEN 20 과 30 사이, MedianPrice가 40보다 작은 항목 출력
DISTINCT - 중복된 값 제거
- GROUP BY와 달리 집계함수가 사용되지 않는다.
- GROUP BY와 달리 정렬하지 않으므로 더 빠르다.

-> CategoryID를 중복되지 않게 출력 ( 정렬하지 않는다 )

-> DISTINCT 컬럼1,컬럼2... 의 경우 컬럼을 합쳤을 때 중복되는 값 제거 후 출력

-> 오류 발생 , 중복되지 않게 COUNT하고 싶으면 COUNT(DISTINCT CategoryID) 로 작성
DISTINCT와 GROUP BY 의 차이
GROUP BY 는 "GROUPING" + "정렬"
DISTINCT 는 "GROUPING" 작업만 수행
!! DISTINCT는 함수가 아니다
DISTINCT는 함수가 아니라 키워드
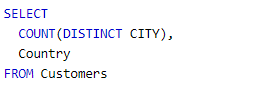
우리는 City의 Unique 값 , Country의 전체 값 출력을 원한다
그러나 위와 같이 작성하면 Country의 전체 값을 출력할 수 없다.
SELECT절에 DISTINCT라는 키워드가 있으면, MySQL은 SELECT되는 모든 Column(Tuple)들에 대해서 DISTINCT를 적용해서 결과를 출력한다.
❗ 해결책

-> GROUP BY 로만 해결 가능
