레코드 기록 💡
1. 레코드 키(Record key) 💡
- 화일 검색의 문제 : 파일 내의 특정 레코드 검색
- 레코드 내용을 근거로 특정한 레코드를 검색하는 것이 편리
"1st record", "2nd record" vs "Ames record", "Mason record"
- 키(key) (Ames ,Mason) 를 레코드 주소로 변환하는 규칙필요
- 검색 키의 정규 형태(canonical form)필요
- 기본 키(primary key) : 하나의 레코드를 유일하게 식별하는 키
-> ex) 학번 , 주민번호 - 보조키(secondary key)
-> ex) 이름 , 학과 / 중복 가능
2. 순차 검색 💡
- 순차 검색의 성능 평가
평가기준 : Read 함수의 호출 수(메모리 내에서의 비교시간은 무시)
n개의 레코드를 갖고 있는 파일
- n에 비례 -> 차수 O(n)
- 평균 n/2회의 호출 필요

-> 4000 / 16 = 250 개의 묶음 ( 평균은 250 / 2 = 125 회 )
- 순차 검색의 장점
- 프로그래밍 쉽다
- 단순한 형태의 화일 구조 요구
- 순차 검색이 좋은 경우 (일상적인 컴퓨팅에서 자주 일어남)
- 레코드의 개수가 적은 화일들 ( ex) 10개의 레코드)
- 좀처럼 검색될 필요가 없는 화일
백업 테이프 화일
- 특정한 보조키 값에 일치하는 레코드의 개수가 매우 크게 예상되는 화일
ex) 수업에 IT정보공학과의 학생이 많을 때 ( 케이스가 많은 경우 )
수업에 몇명의 IT정보공학과의 학생이 있는지 탐색할 때
- 레코드 Blocking을 사용한 순차 검색 성능
Blocking : 레코드의 묶음으로 성능 측정을 위해 사용 , 디스크 드라이브
의 물리적 속성에 관계(섹터 크기의 배수)
여러 레코드로 구성된 블록을 한꺼번에 판독한 뒤,
메모리에서 그 레코드를 처리
3. 직접 검색 💡
- Direct Access : 레코드의 시작위치를 바로 찾아가서 판독 가능할 때
순차 검색은 O(n) , 직접 접근은 O(1) 연산
- Direct Access의 주요문제 : 레코드의 시작 위치를 알아야 함
RRN(relative record number) : 화일의 시작에 대한 레코드의 상대적 위치
가변길이 레코드인 경우 도움 x
고정길이 레코드인 경우
- byte offset = n r (n:레코드 RRN , r: 레코드의 크기)
ex) 4000 개의 레코드 512byte , 1번에 접근할 때 ( 1 512 = 512 )
2. 레코드 구조 (자세히) 💡
1. 레코드 구조와 레코드 길이의 선택
방법 1. 고정길이 필드 , 고정길이 레코드 ✔
- 장점 : 단순성
- 단점 : 제일 긴것을 기준으로 고정길이로 만들기 때문에 레코드의 크기가 커짐

방법 2. 가변길이 필드 , 고정길이 레코드 ✔
- 장점 : 평균(averageing-out)효과 (작은 공간을 효과적으로 이용)
- 해결과제 : 레코드 내에서 사용되지 않는 부분과 데이터 부분 구별
- 방법 1에 비해 레코드가 짧은 길이를 가진다.

2. Header Records
- 화일에 대한 정보를 유지하는 특수 레코드
- 정보 유지를 위해 화일의 시작부분에 놓임
- 보통 화일에 있는 데이터 레코드와는 다른 구조
- 화일 설계를 위한 중요한 도구
- Header Records의 내용
레코드의 수 , 레코드 길이 , 최근 변경일 등
3. 파일 접근 & 파일 구성 ❗❗
- 화일 접근 : 순차 , 직접 접근
- 화일 구성 : 가변길이 , 고정길이 레코드
- 화일의 구성과 화일의 접근 사이에는 상관관계 존재
레코드 시작위치를 모를 경우 -> 순차 접근
직접 접근하기 위해서는 -> 고정 길이 레코드
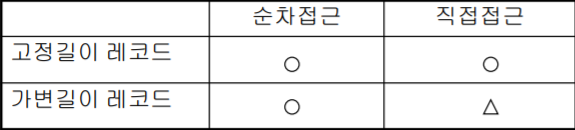
중요 ❗❗ Q) 가변길이 레코드 (직접 접근 x 인 이유 )
직접 접근을 완전히 할 수는 없지만 중간 정도 쯤은 할 수 있게 만들 수 있다.
-> 인덱스 파일을 이용
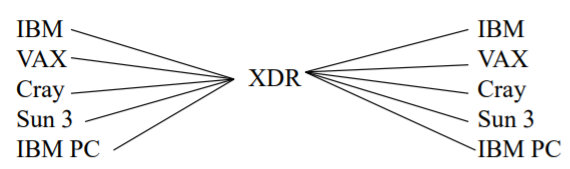
4. 이식성 및 표준화
변환 1. 직접 변환 형태 💿
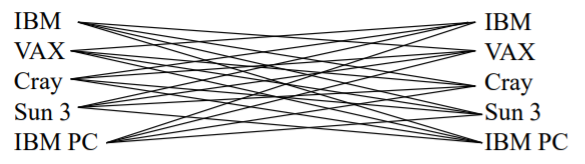
변환 2. 중간 표준 형태 💿