KOOC에서 제공하는 KAIST 문인철 교수님의 "인공지능 및 기계학습 개론 1" 수업입니다.
Review
지난 시간에 Optimal Classifier에 대해 배웠다. 다시 복습해보자.
Optimal Classification은 Bayes Risk를 줄이는 데 최적화된 Classification이다. 즉 오류를 최소화하는 optimize function인 것이다!
Bayes Theorm을 이용해 given과 R.V를 switch해 표현해주었다. 이때 Prior()는 알 수 있지만, Likelihood()는 Random Variable X가 여러 개일 경우 문제가 될 수 있다. 이를 해결하기 위한 것이 Naive Classification!!
그 놈의 Navie Clssification이 무엇인지 알아보자.
Dateset for Optimal Classifier Learning

주어진 6개의 Random Variable(Sky, Temp, Humid, Wind, Water, Forecst)을 통해 EnjoSpt를 예측해보는 모델을 만든다고 하자.
Random Variable이 여러 개가 됐으니, 이를 생각해주어야 한다.
즉, 변수 사이에 Compound가 생겨 Joint Prob이 되는 것이다. Prior는 어떨까?
Prior 는 전체 경우의 수 중 yes가 나올 확률이므로, 위의 표에서는 0.75가 된다. 쉽다.
자, 그렇다면 필요한 Parameter의 수는 얼마나 될까??
Likelihood의 경우, 각 Random Variable이 가질 수 있는 경우의 수가 2라고 보면 이 된다. 따라서 위의 표는 64개의 Condition이 존재한다. 이때 모든 64개의 Comdition의 Sumation은 1이 Probability Simplex 속에 존재해야 한다. 따라서 마지막 64번 째 값은 1에서 63개의 값을 빼주면 되는 값이다. 그리고 Class 개수 k를 곱한 수 만큼의 Parameter가 필요하다.
Prior의 경우, Binary Classifier이기 때문에 Y=yes에 대한 확률만 안다면 Y=no인 확률도 알게된다. 따라서 1개의 parameter만 필요하다. 그래서 Class 개수 k에서 하나를 뺀 만큼의 parameter가 필요하다.
만큼의 parameter가 필요하다...너무 많이 필요하다. 줄일 필요가 있다.
Why need an additional assumption?
Joint Probability Distribution 때문에 너무 많은 parameter가 필요하다.
x is a vector value, and the length of the vector is d
벡터의 길이 d를 줄여야 한다는 말이다. Input feature를 많이 늘려놨더니 줄여라? 그건 또 좋지 않은 방법이다. 누가 기껏 늘려놨더니 줄이고 싶겠냐 이거다. 그래서 새로운 가정(additional assumption)이 필요하다. 그게 바로 Conditional Independence이다.
Conditional Independence Assumtion
given y인 상황에서 개별 는 모두 conditionally independence하다고 가정하자는 것이다. 이게 무슨 말이냐 하면,
라고 보자는 것이다. 이렇게 하면 parameter의 수가 인 것을 줄일 수 있다 이거다.
conditional independence에 대해 좀 더 알아보자. is conditionally independent of given y. given y인 상황에서 x1과 x2가 서로 conditionally independent 하다는 말은,
이다. 따라서
가 된다는 것이다.
Conditional vs. Marginal Independence
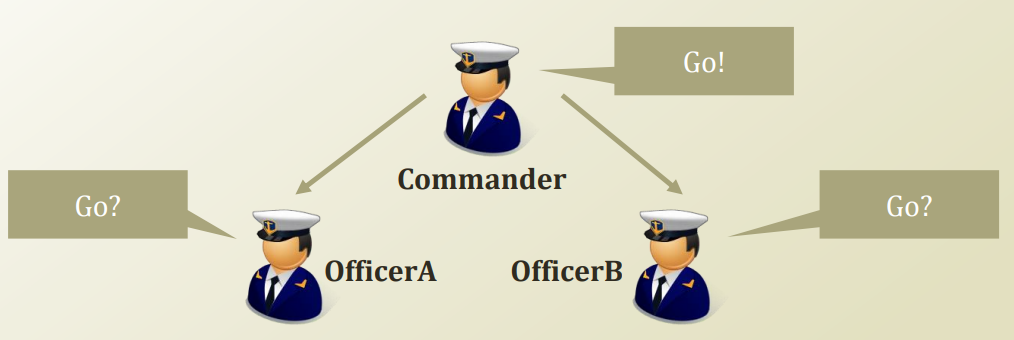
쉽게 말해서 Commander의 명령을 아는가 모르는가에 따라 구분된다. 즉, 두 Random Variable 사이에 오작교를 할 사람이 있으면 Conditional Independence하고, 없으면 Marginal Independence하다!!
latent variable에 기반해서 Conditional Indepence하게 정의할 수 있다는 것이다.
결론!! Navie Bayes Classifier은 Class variable을 동인(動因, drive)으로 생각하고, 그것을 기반으로 Conditional로 두어 X1과 X2 사이의 독립을 정의하는 Classifier인 것이다.
