KOOC에서 제공하는 KAIST 문인철 교수님의 "인공지능 및 기계학습 개론 1" 수업입니다.
Ch 3. Naive Bayes Classifier
3.1. Optimal Classification
머신러닝은 Probably, Approximately, Correct한 Function을 만드는 것!!
Classification은 쉽게 말해 X라는 데이터를 받아 Y에 대해 True of False인지 판별하는 것이라 할 수 있다. 예를 들면, X가 given일 때 Y가 초록색일지 빨강색일지 결정하는 것이다.
다시 말하면, 어떤 given X가 주어진 상황에서 Classification 될 Target class Y에 대한 확률값을 계산해야 한다. 이를 위해 PDF를 정의해 조정해주는 것이 좋을텐데, 이때 Bayes Classifiaction을 정의해보자.
이것은 Function approximation of error minimization이다. 이런 이름이 붙는 이유에 대해 알보자.
먼저 는 error항을 가진 라고 생각하면 된다. 따라서 는 error가 있을 확률을 뜻한다.
그리고 은 error를 갖지 않을 확률을 최소화시켜주는 f를 찾는다. 그것이 함수 이다. 즉, error를 minize하는 f를 찾는 opimize function이다.
만약 두 개의 클래스에 대해 다루면 어떨까?
argmin이 argmax로 바뀌었다. 그럼 다른 것을 뜻하는 것일까? 아니! 아닌데!? 똑같은데!?ㅎㅎ
가 될 확률을 maximize한다는 것은, 두 개의 클래스니까 다른 클래스에 대해서는 minimize한다고 볼 수 있다. 즉, 될 확률은 위와 같이 minimize 시킨다.
Bayes Risk
우리는 이전 시간에 MLE와 MAP에 대해 다루었다.
MLE는 Binomial Dist을 따르고, MAP는 Beta Dist을 따르고 Bayes Theorm을 이용해 위와 같이 정리할 수 있었다.
이제 이 둘을 이용해 Naive Classification에 적용해보자.
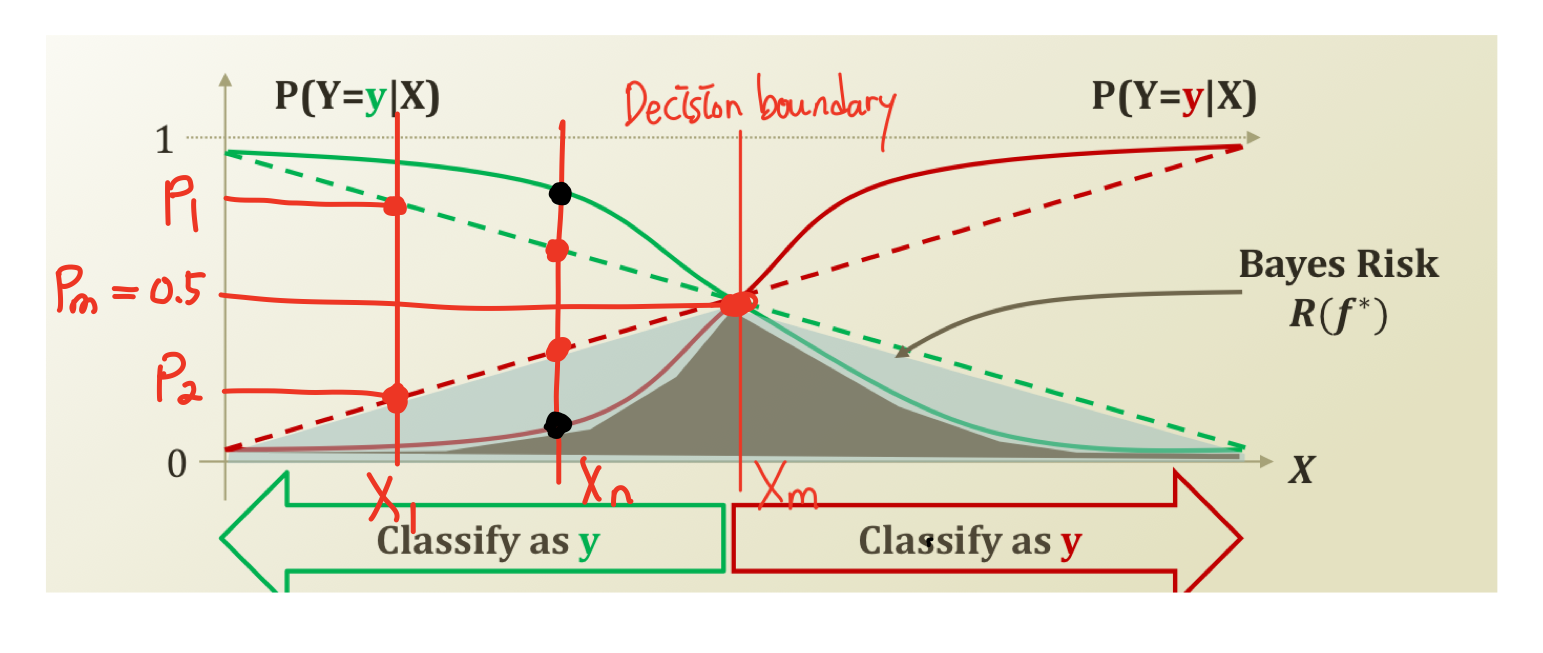
사진에서 given X를 분류하는 두 개의 linear, 두 개의 non-linear classification이 있다. 데이터 이 주어질 때, 확률을 P라고 하면 두 클래스가 만나는 지점(Decision boundary)에서 확률P는 0.5가 된다.
우리는 더 높은 확률을 선택해야 한다. 즉, 위쪽에 있는 클래스를 선택해야 하는데 두 개의 linear class의 확률차이는 non-linear class의 확률차이보다 작다. 다시 말하면 non-linear class가 더 높은 확률로 클래스를 잘 구분할 수 있다는 말이다.
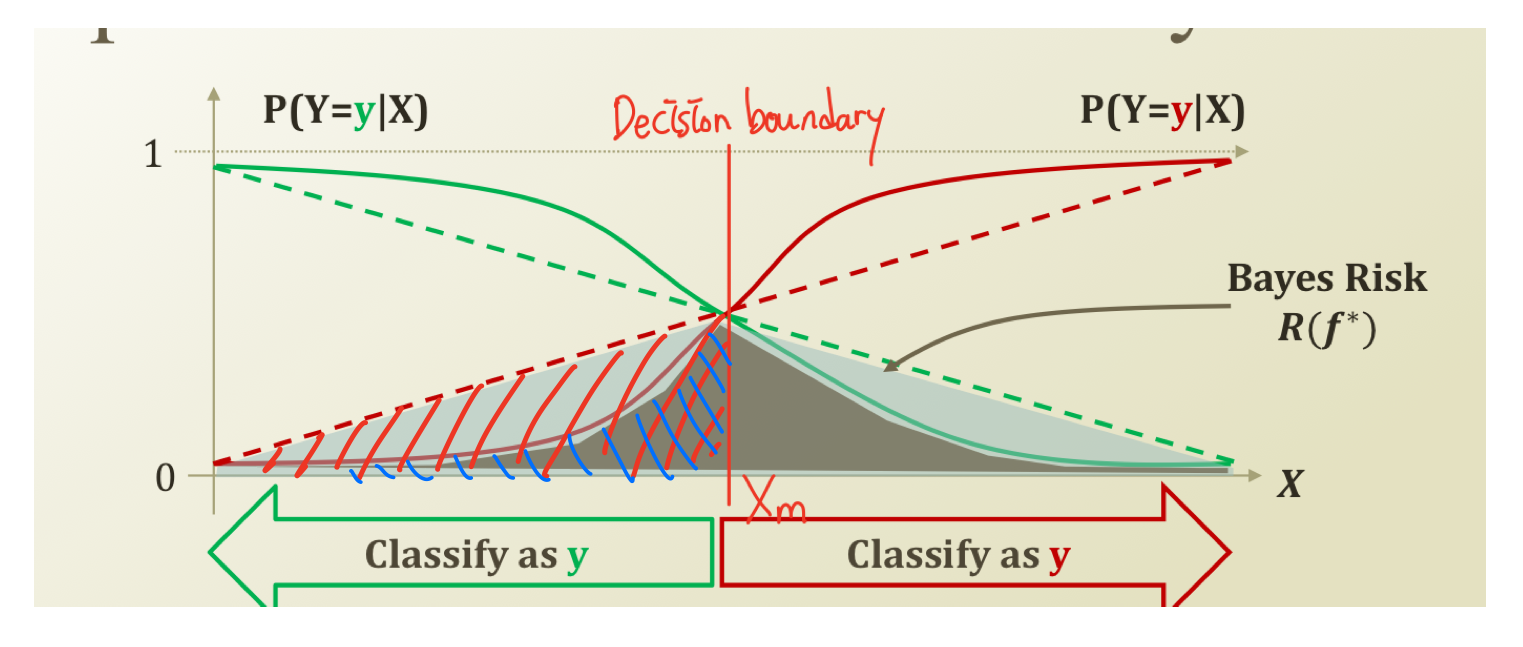
전에 더 높은 확률을 선택해야 하기 때문에 위쪽에 있는 클래스를 선택해야 한다고 했다. 그래서 위쪽의 클래스를 선택하면 다른 클래스의 아래 영역은 error가 된다.
그 영역의 넓이를 보면 linear class가 non-linear class보다 더 크다는 것을 그래프를 보면 알 수 있다. linear class가 더 많은 error를 가지고 있다는 것이다. 그 넓이의 차이가 두 클래스 방식의 성능차이가 된다. 그리고 이 error 영역을 Bayes Risk라고 부른다.
자! 그럼 Optimal Classification은 뭘까? Bayes Risk를 줄이는데 최적화된 Classification이라고 보면 된다. 그렇다면 그 함수 형태는 어떤 모습일까? Bayes Risk를 줄이는 형태여야 할텐데, 그것을 알아보는 것이 이번 학습의 핵심목표이다.
Learning the Optimal Classifier
Bayes Risk를 줄이기 위한 함수의 형태는 직선보단 곡선이 더 유리할 것이다 라는 것을 알았다.
Opimal Classifier는 다음과 같다.
데이터로 주어진 y와 우리가 판별해서 나오는 Y가 같은 값을 갖도록 만들어주는 확률을 function approximation된 값이다.
이것을 좀 더 쉬운 형태로 바꾸어 주려고 하는데, prior를 이용해 Bayes Theorm을 이용한다.
이때 이고,
이다.
Bayes Theorm의 장점은 given과 Random Variable을 switch시켜줄 수 있다는 것이다. Prior는 우리가 아는 정보이다. 데이터에서 Y가 y와 같은 확률이다.
Prior은 MLE, MAP를 이용해 구할 수도 있다. Likelihood는 Y가 True or False인 경우를 나눠 구할 수 있다.
이때 문제는 X가 하나의 Random Variable이 아니라 여러개일 경우 문제가 될 수 있다. 여러 Variable이 서로 combination, interaction되면 문제가 복잡해진다. 이를 해결하기 위한 것이 Naive Classification!!!!
