큰 클래스나 밀접한 관련이 있는 클래스들을 추상화와 구현이라는
독립적으로 개발될 수 있는 두 계층으로 나누는 구조 패턴문제
도형을 나타내는 Shape 라는 클래스에 Circle과 Square 라는 서브클래스가 있다고 가정
이 클래스 계층을 확장해 색상을 도입하기 위해 Red와 Blue라는 서브클래스를 만들려고 하는 상황
→ 이미 두 서브클래스가 있기 때문에 총 4개의 클래스 조합 필요 (e.g. RedCircle, BlueSquare)
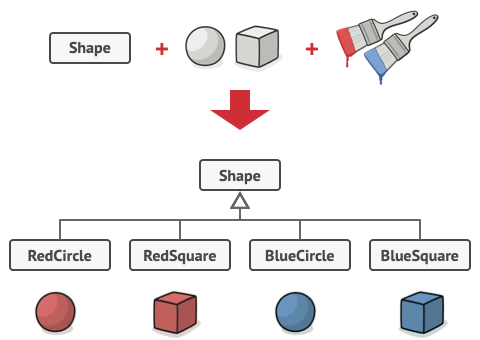
새로운 모양과 색이 추가될 때마다 계층은 기하급수적으로 커질 것
해결책
이 문제는 모양 클래스를 형태와 색이라는 두 독립적인 차원에서 확장하려고 하기 때문 → 클래스 상속에서 매우 흔한 이슈
브리지 패턴은 상속을 객체 합성으로 바꿔 문제 해결
→ 한 클래스에 모든 상태와 행위를 포함하는 대신, 차원 중 하나를 추출해 별도의 클래스 계층으로 만들어서 기존 클래스들이 새 계층의 객체를 참조하는 방식
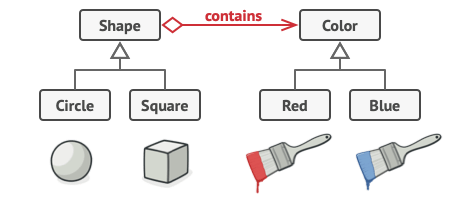
위 문제는 색상과 관련된 코드를 하나의 클래스로 추출해서, Shape 클래스에 색상 객체를 참조하는 필드를 추가하는 것으로 해결 가능
구조
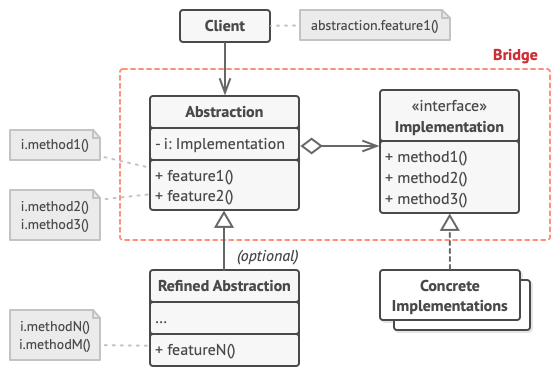
1. 추상화 - 하이 레벨 제어 로직 제공, 실질적인 로우 레벨 작업은 구현 객체에 의존
2. 구현 - 모든 concrete 구현에 대한 공통 인터페이스 선언,
추상화는 이곳에 선언된 메서드를 통해서만 구현 객체와 소통 가능
- 추상화는 구현과 같은 메서드를 나열할 수도 있지만,
대개 추상화는 구현에서 선언된 다양한 원시 작업들에 의존하는 복잡한 행위들을 선언함
3. Concete 구현 - 플랫폼 맞춤형 코드 포함
4. 정제된 추상화 - 제어 로직의 변형 제공, 추상화(부모)처럼 일반 구현 인터페이스를 통해 다양한 구현들을 다룸
5. 클라이언트 - 추상화만 사용하지만 추상화 객체를 구현 객체 중 하나와 연결해주는 일도 클라이언트가 해야 함적용
특정 기능에 대한 여러 변형을 가지는 모놀리식 클래스를 나눠서 정돈하려는 경우 (e.g. 클래스가 여러 데이터베이스 서버를 다루는 경우)
- 클래스가 크면 클수록 어떻게 작동하는지 알아내기가 어렵고 변경하는 데 시간이 오래 걸림
→ 한 변형 기능에 적용된 변경 사항은 클래스 전체의 변경을 필요로 할 수도 있음
→ 부작용으로 인한 에러 자주 발생
- 브리지 패턴 - 모놀리식 클래스를 여러 클래스 계층으로 나눠서,
각 계층의 클래스들을 다른 클래스들과 독립적으로 변경할 수 있음
→ 기존 코드를 훼손할 위험성을 줄여 유지보수성 향상한 클래스를 여러 독립 차원으로 확장하려는 경우
- 브리지는 각 차원마다 별개의 클래스를 추출
→ 기존 클래스는 관련 작업을 혼자서 모두 수행하는 대신 해당 계층의 객체에 위임런타임에서 구현을 전환할 필요가 있는 경우
- 브리지 패턴 - 추상화 내부의 구현 객체를 선택적으로 바꿀 수 있게 해줌 → 필드에 새로운 값 할당하면 됨
- 브리지 패턴과 전략 패턴을 많은 사람들이 헷갈려하는 이유이기도 함구현방법
1. 클래스에서 독립 차원들을 찾아냄
- e.g. 추상화/플랫폼, 도메인/인프라, 프론트엔드/백엔드, 인터페이스/구현
2. 클라이언트가 필요로 하는 작업들을 기본 추상화 클래스에 정의
3. 모든 플랫폼에 제공되는 작업들을 결정하고, 일반 구현 인터페이스에 추상화가 필요로 하는 작업들을 선언
4. 도메인의 모든 플랫폼에 대해 구현 인터페이스를 따르는 concrete 구현 클래스 생성
5. 추상 클래스 안에 구현 유형에 대한 참조 필드 추가
- 추상화는 해당 필드에 참조된 구현 객체에게 대부분의 작업 위임
6. 하이 레벨 로직의 여러 변형이 있다면, 기본 추상화 클래스를 확장해 각 변형마다 정제된 추상화 생성
7. 클라이언트 코드는 추상화의 생성자에 구현 객체를 전달해 서로를 연결시키고, 그 이후로는 추상화 객체만 다루면 됨장단점
장점
- 플랫폼에 의존하지 않는 클래스와 앱을 만들 수 있음
- 클라이언트 코드는 높은 수준의 추상화를 통해 작동하며, 플랫폼의 세부 사항에 노출되지 않음
- OCP - 새로운 추상화와 구현을 독립적으로 도입 가능
- SRP - 추상화에서는 하이 레벨 로직에 중점을 두고, 구현에서는 플랫폼 세부 사항에 중점을 둠단점
- 응집도가 높은 클래스에 적용하면 코드가 더 복잡해짐다른 패턴과의 관계
- 브리지 - 보통 사전에 설계되어 프로그램의 각 부분들을 독립적으로 개발 가능하게 함
어댑터 - 대개 기존 프로그램과 함께 사용돼 원래 호환되지 않는 클래스가 잘 동작하도록 만듦
- 브리지, 파사드, 전략, 어댑터 - 다른 객체에 작업을 위임하는 합성 기반 패턴이라는 점에서 유사하지만
모두 다른 문제를 해결함
- 추상 팩토리를 브리지와 함께 사용 가능 - 브리지가 정의한 추상화가 특정한 구현만 다룰 수 있는 경우,
추상 팩토리가 이 관계를 캡슐화해 클라이언트 코드에서 복잡성을 숨길 수 있음
- 빌더 + 브리지 - 디렉터가 추상화 역할 수행, 빌더들이 구현 역할 수행TypeScript 예제
/**
* The Abstraction defines the interface for the "control" part of the two class
* hierarchies. It maintains a reference to an object of the Implementation
* hierarchy and delegates all of the real work to this object.
*/
class Abstraction {
protected implementation: Implementation;
constructor(implementation: Implementation) {
this.implementation = implementation;
}
public operation(): string {
const result = this.implementation.operationImplementation();
return `Abstraction: Base operation with:\n${result}`;
}
}
/**
* You can extend the Abstraction without changing the Implementation classes.
*/
class ExtendedAbstraction extends Abstraction {
public operation(): string {
const result = this.implementation.operationImplementation();
return `ExtendedAbstraction: Extended operation with:\n${result}`;
}
}
/**
* The Implementation defines the interface for all implementation classes. It
* doesn't have to match the Abstraction's interface. In fact, the two
* interfaces can be entirely different. Typically the Implementation interface
* provides only primitive operations, while the Abstraction defines higher-
* level operations based on those primitives.
*/
interface Implementation {
operationImplementation(): string;
}
/**
* Each Concrete Implementation corresponds to a specific platform and
* implements the Implementation interface using that platform's API.
*/
class ConcreteImplementationA implements Implementation {
public operationImplementation(): string {
return 'ConcreteImplementationA: Here\'s the result on the platform A.';
}
}
class ConcreteImplementationB implements Implementation {
public operationImplementation(): string {
return 'ConcreteImplementationB: Here\'s the result on the platform B.';
}
}
/**
* Except for the initialization phase, where an Abstraction object gets linked
* with a specific Implementation object, the client code should only depend on
* the Abstraction class. This way the client code can support any abstraction-
* implementation combination.
*/
function clientCode(abstraction: Abstraction) {
// ..
console.log(abstraction.operation());
// ..
}
/**
* The client code should be able to work with any pre-configured abstraction-
* implementation combination.
*/
let implementation = new ConcreteImplementationA();
let abstraction = new Abstraction(implementation);
clientCode(abstraction);
console.log('');
implementation = new ConcreteImplementationB();
abstraction = new ExtendedAbstraction(implementation);
clientCode(abstraction);// Output.txt
Abstraction: Base operation with:
ConcreteImplementationA: Here's the result on the platform A.
ExtendedAbstraction: Extended operation with:
ConcreteImplementationB: Here's the result on the platform B.참고 자료: Refactoring.guru
