Comment :
Attention + seq2seq의 작동원리 학습 이후, Scoring function 및 아래의 두 기법을 배우면서 보다 확실하게 Attention에 대해서 알아야 된다고 판단하여 이 글 작성함
- Additive Attention - Dzmitry Bahdanau; Neural Machine Translation by Jointly learning to align and translate
- Multiplicative Attention - Thang Luong; Effective Approaches to Attention-based Neural Machine Translation
Attention
0. Sequence to Sequence의 한계점
참고 : Sequence to Sequence
seq2seq모델의 한계점은 바로
"긴 입력 시퀀스, 즉 긴 문장을 하나의 고정된 크기의 벡터로 압축하면서 정보손실 발생"
한다는 점이다.
아래의 그림처럼 (초록색) 출력단어를 예측하는 시점마다 Encoder의 (자두색) 입력시퀀스(단어)를 참고하되, 예측할 단어와 연관이 큰 단어에 더 집중해서 참고하는 방법으로 위와 같은 seq2seq 모델의 한계점을 극복할 수 있다.
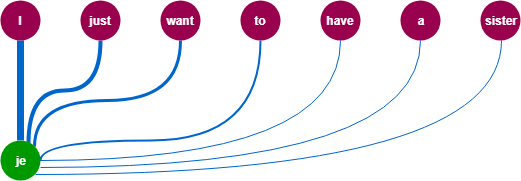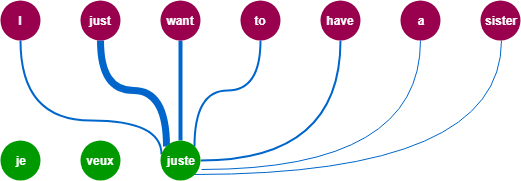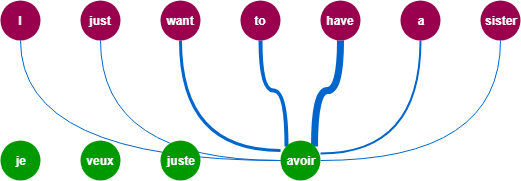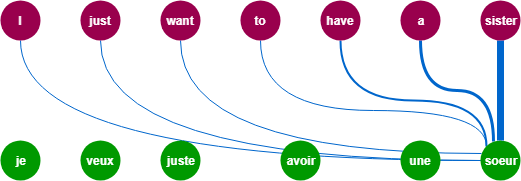
1. Attention 맛보기
참고 : [NLP] Attention Mechanism(어텐션)-Hyen4110
seq2seq에 대한 직관적인 이해
한 번역가는 독일어를 처음부터 끝까지 읽습니다. 그 일이 끝나면, 그는 단어들을 하나씩 영어로 번역하기 시작합니다. 이때, 만약 문장이 과도하게 길다면 그는 아마 앞쪽 텍스트에서 무엇을 읽었는지를 잊어버렸을 것입니다.
attention+seq2seq에 대한 직관적인 이해
한 번역가는 독일어 텍스트를 처음부터 끝까지 키워드를 적으면서 읽은 후 영어로 번역을 시작합니다. 각 독일어 단어를 번역할때, 그는 그가 적어놓은 키워드를 활용합니다.
예컨대 독일어 "Ich mochte ein bier"를 영어 "I'd like a beer"로 번역하는 seq2seq 모델을 만든다고 칩시다. 모델이 네번째 단어인 'beer'를 예측할 때 'bier'에 주목하게 만들고자 합니다. 어텐션 메커니즘의 가정은 인코더가 'bier'를 받아서 만든 벡터가 디코더가 'beer'를 예측할 때 쓰는 벡터와 유사할 것이라는 점이다.
2. Attention mechanism
[Step 0] Getting ready to pay attention
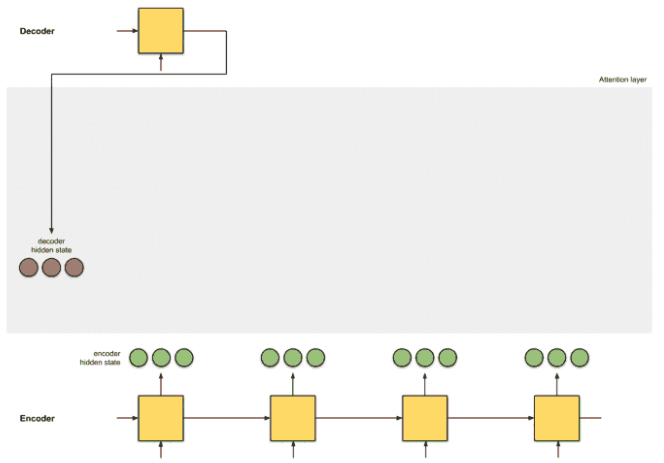
(위 그림과 같이) Encoder의 Hidden state들과 Decoder의 첫번째 Hidden state를 준비한다.
ex) 독일어 "Ich mochte ein bier" 영어 "I'd like a beer" 번역을 한다고 해보자. 그러면 독일어 Ich, mochte, ein, bier가 Encoder에 입력될때마다 Hidden state들 이 생성될 것이다.
- :
Ich에 영향을 받은 벡터 (거의 'Ich'에 대한 정보만 있음) - :
mochte에 영향을 많이 받은 벡터 ('Ich'에 대한 정보도 있긴함) - :
ein에 영향을 많이 받은 벡터 ('Ich', 'mochte'에 대한 정보도 있긴함) - :
bier에 영향을 많이 받은 벡터 ('Ich', 'mochte', 'ein'에 대한 정보도 있긴함)
또한, Encoder의 마지막 통합 은닉상태인 는 (문장의 시작을 알리는 sos 토큰과 함께) Decoder의 첫번째 Time step으로 입력되고, Decoder는 첫번째 Hidden state 와 첫번째 output인 'I'를 출력할 것이다.
- Decoder 입력
sos토큰- Hidden state
Encoder의 마지막 통합 Hidden state; h4, Decoder는 이를 Context vector로 본다
- Decoder 출력
'I'- Hidden state
다음 단어('like')를 예측하기 위한 벡터
🔥 자 여기까지만 봤을 때에는 (Attention 기법이 적용되지 않은) seq2seq와 다를것이 없다! 이제 Attention mechanism이 어떻게 작동되는지 봐보자
🔥 seq2seq without attention vs with attention의 차이는 문장을 번역할때 번역 전의 문장에 대한 정보를 1개로 압축해서 번역하느냐 / 번역 전의 문장 속 단어 각각의 정보를 모두 넘겨주고 주의깊게 봐야할 부분을 조금 더 집중해서 보느냐의 차이이다. Encoder가 만든 Hidden state들 을 넘겨준다는 부분에 있어서 번역 전의 문장 속 단어 각각의 정보를 넘겨주는것 실현되었다. 그러면 조금 더 집중해서 볼 부분을 어떻게 정할까?
[Step 1] Get the scores
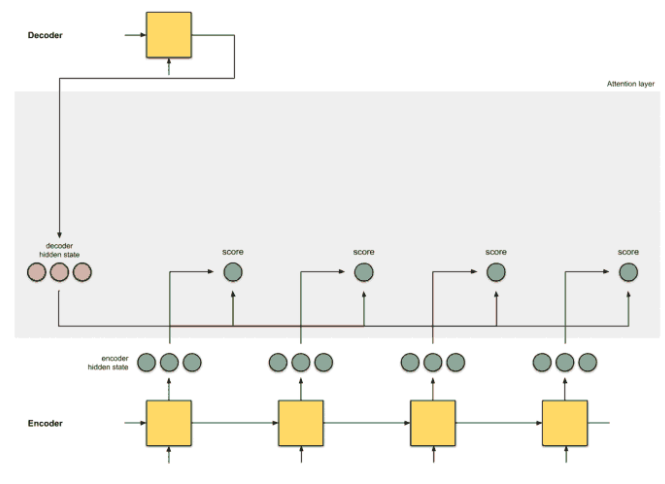
번역 전 문장, 즉 단어들의 정보들(Hidden state들)에서 어떤 놈을 집중해서 봐야할지 '점수'를 메기는 과정이다.
독일어 "Ich mochte ein bier" 영어 "I'd like a beer" 번역과정에서 'Ich' 'I'd'는 번역이 되었고 우리에게 주어진 것은 Decoder는 첫번째 출력 Hidden state 이다. 여기에는 'I'd'의 다음 단어인 'like'를 예측하기 위한 정보(?)가 담겨있을 것이다. 그러면 우리가 Hidden state들 에서 가장 집중해서 볼 것은 바로 'mochte'에 대한 정보를 많이 가진 이다.
따라서 'like'를 예측하기 위한 Hidden state 와 Hidden state들 과의 어떠한 연산을 통해서 'like'를 예측하기 위한, 'like'와 가장 대응되는, 즉 유사한 번역 전 단어의 Hidden state를 찾을 수 있다.
- : Score
- : alignment model, (Decoder의 Hidden state)와 (Encoder의 Hidden state들)간 유사도를 뽑는 Function
- : Decoder가 생성한 Hidden state
- : Encoder가 생성해서 넘겨준 Hidden state!
- : Decoder의 Timestep
- : Encoder의 Timestep
따라서 e_ij는 디코더가 출력을 만드는 시점 i에서의 / 인코더로부터 전달받은 j번째 Hidden state와, 디코더가 생성해낸 i-1번째, 즉 이전 Hidden state와의 유사도, Score! 스칼라값
[Step 2] Get the softmaxed scores
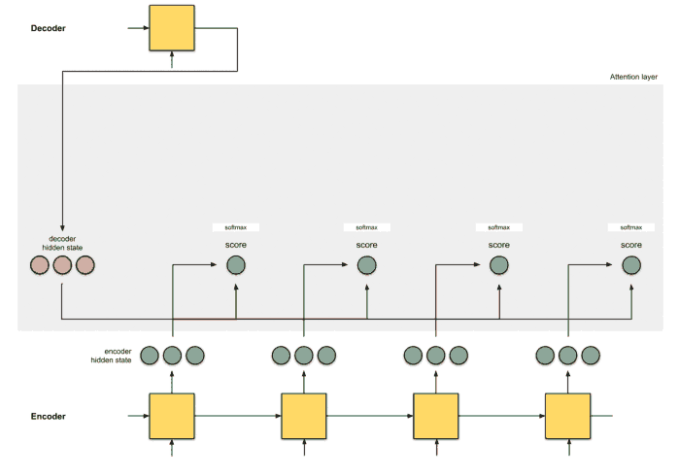
자 이제 구한 Score값들을 Softmax function에 통과시켜서 값들이 0~1사이의 값이고, 모두 더했을때 1이 되게끔 만든다
- : Softmaxed Score값, Attention vector의 요소
- : Softmaxed Score값(스칼라값)들로 이루어진 벡터
- : Score값
- : 인코더 입력 단어의 개수
- : 디코더의 시점
어렵게 생각할거없다. 그냥 이전 Step에서 만든 Score값을 Softmax, 즉 Score값들에 모두 를 취한다음 각각의 값을 모든 Score + 값들의 합으로 나눠준것임. 이러면 비율을 구할 수 있음
[Step 3] Get the Alignment vectors
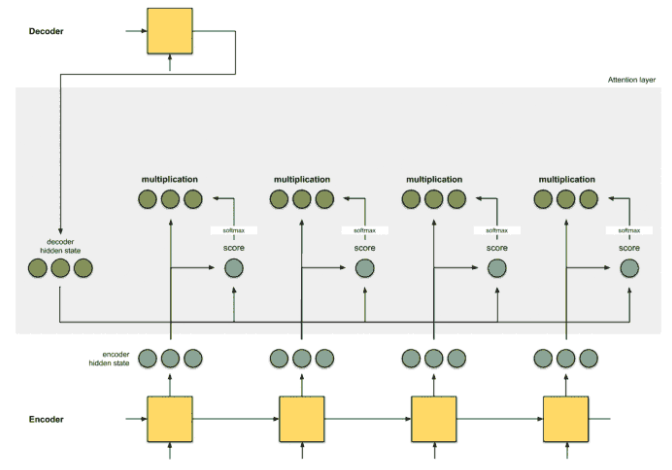
자 앞서 만든 Softmaxed score의 의미는 각 Hidden state, 의 중요도 비율 느낌이다. 무슨 느낌이냐면... 굳이 모든 Hidden state들, 을 봐야한다면 어떤 놈이 가장 중요할까?를 비율적으로 나타낸것이다. 따라서 앞서 만든 Softmaxed score값, 즉 중요도 비율을 각각의 Hidden state들에게 곱해준다면 별로 중요하지 않은 애들은 값이 작아질것이고, 중요한 애들은 값이 커질것이다! 일종의 가중치같은 느낌
Softmaxed score 와 Hidden state 의 multiplication 값을 Alignment vector(or annotation vector)라고 한다.
[Step 4] Get the context vector
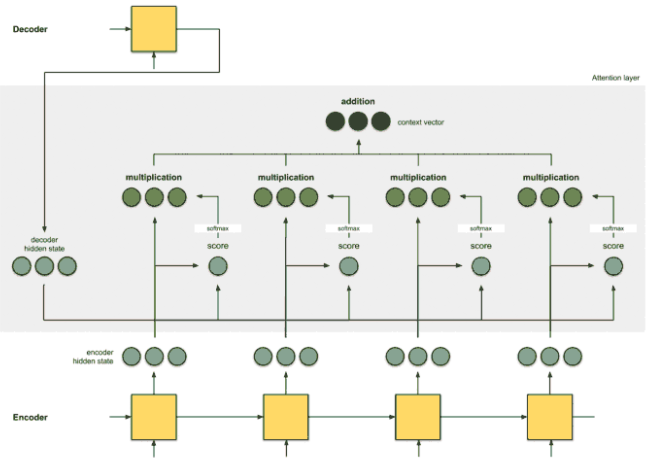
이제 Alignment vector들을 모두 합해서 Context vector를 만든다. 번역기 예시관점에서의 이 vector의 의미는... 번역 전 단어인 'Ich', 'mochte', 'ein', 'bier'의 Hidden state들을 현재시점('like'를 예측해야 하는 시점)에서 중요한 정도별로 비중을 조정하여 1개로 합친것이다.
- : Context vector
- : 입력 문장의 단어개수, 즉 (Encoder로 부터 넘겨받은) Hidden state개수
- : 인코더의 번째 시점의 Hidden state와 디코더의 번째 시점의 Hidden state와의 유사정도인 Score의 Softmax 값
- : 인코더가 넘겨주는 Hidden state
[Step 5] Feed the context vector to decoder
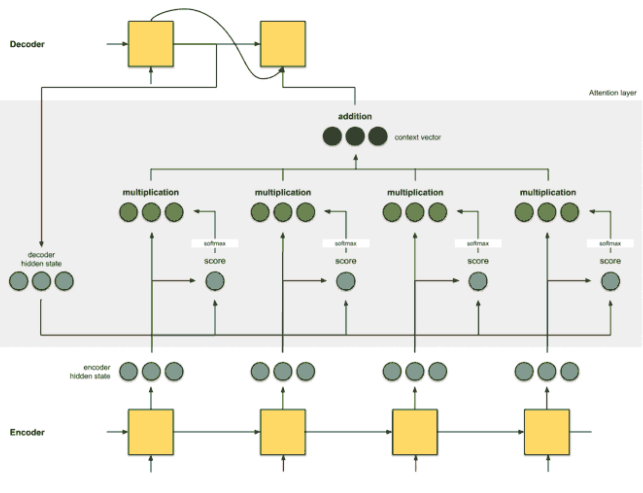
위의 과정들로 생성된 귀하디귀한 Context vector를 번째 Timestep 디코더에 넣어주고, 번째 디코더가 생성해낸 단어도 넣어줘서 번째 단어를 생성해낸다.
[+] 디코더의 현시점 i를 두번째 단어를 생성해내는 시점으로 한다
번역기 예시로 히스토리를 적어보면 아래와 같다
-
i-1시점의 디코더라는 뜻...- 입력 : ,
sos토큰 - 출력 : ,
'I'- 해당 디코더내에서 은 Attention기법을 통하여 다음 시점의 단어를 예측하는데 사용되는 Context vector; 로 변환됨
- 입력 : ,
-
- 입력 : ,
'I' - 출력 : ,
'like'
- 입력 : ,
- ...
3. Scoring function
