[+] pivot :
n. (회전하는 물체의 균형을 잡아 주는) 중심점(축),
v. (축을 중심으로) 회전하다, 회전시키다Python Pandas DataFrame에서의
groupby와 유사한(?) 기능을 할 수 있는 Excel의 Pivot Table을 조금만 알아보자
Data
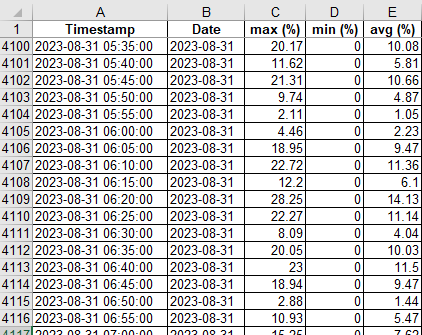
먼저 위와 같은 5분 간격으로 GPU Utilzation max, min, avg값이 찍힌 행들이 있는 엑셀파일이 있다고 해보자
- Timestamp :
yyyy-mm-dd HH:MM:SS의 timestamp (5분 간격) - Date : A column, 즉 Timestamp에서 추출해낸
yyyy-mm-dd형식의 일자값
[+]=text(A2, "yyyy-mm-dd") - max(%), min(%), avg(%) : 해당 timestamp의 GPU 사용률 최고, 최저, 평균
위 엑셀파일을 가지고 일자별 GPU 최대 and 평균 사용률과 같은 Grouping을 하고싶음
Pivot Table
- 먼저 사용하고 싶은 데이터(Row, Column 범위)의 범위를 지정
여기서는 Date, max(%), avg(%) column만 사용하면 될듯 - Pivot Table 만들기
'삽입' - '피벗테이블' - 행, 열, 값 지정
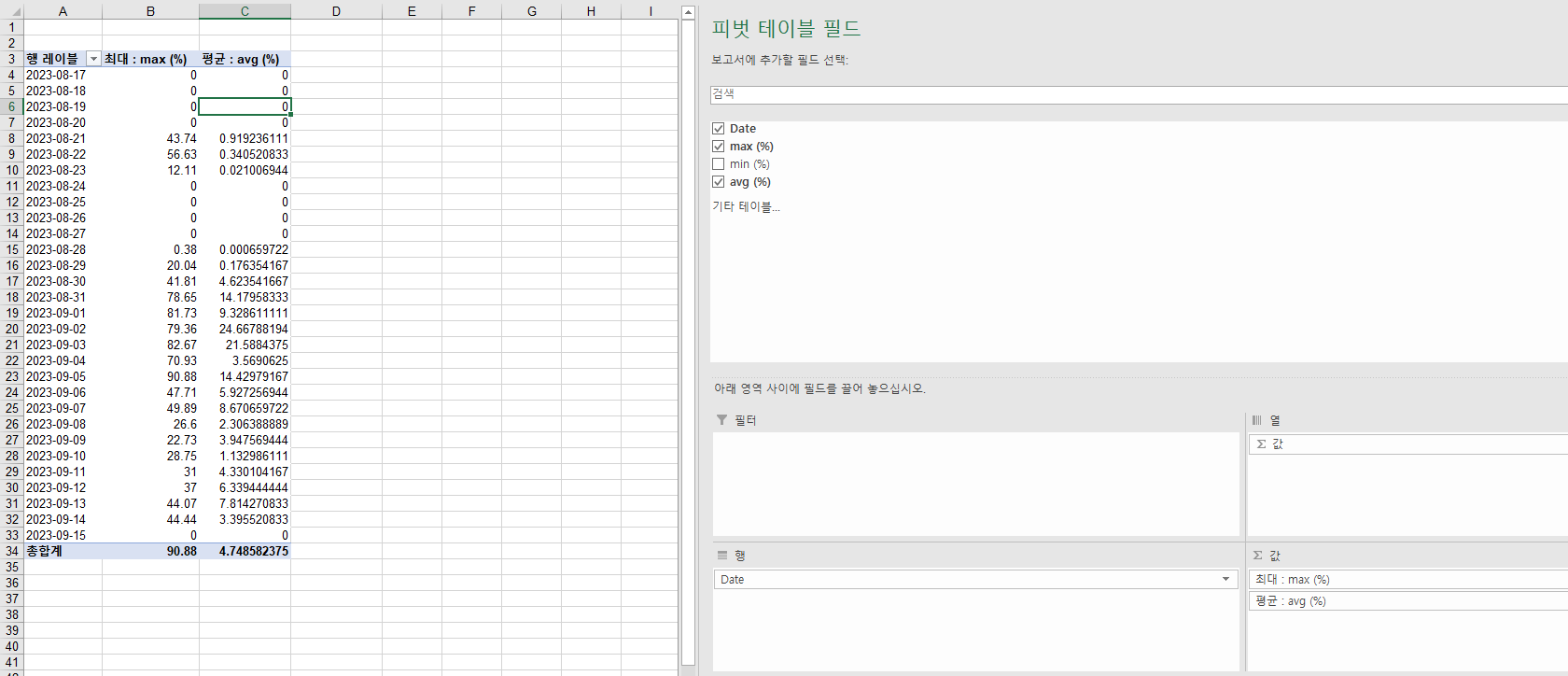
✅ 일자별 GPU 최대 and 평균 사용률
- 일자별 말그대로 일자별로 ~~한 값들을 구하고 싶은 것이므로 Date column의 값들로 묶여서 Row에 나타나야함, 따라서 피벗테이블 필드 '행'에 Date column을 위치시킨다.
- GPU 최대 사용률 1개의 일자에는 5분간격으로 찍힌 GPU 최대사용률이 있는데 그 중 제일 높은 값을 나타내야하므로 피벗테이블 필드 '값'에 max(%) column을 위치시키고 '최대'로 설정한다
- GPU 평균 사용률 1개의 일자에는 5분간격으로 찍힌 GPU 평균사용률이 있는데 그 평균사용률의 일평균 값을 나타내야하므로 피벗테이블 필드 '값'에 avg(%) column을 위치시키고 '평균'으로 설정한다.

예술과 기술