시작
카프카 책을 보며, 헷갈렸던 점을 정리해 놓는다.
ConsumerGroup, Partition, Rebalance
기본 구조
우선 헷갈리지 않으려면 개념이 중요하다.
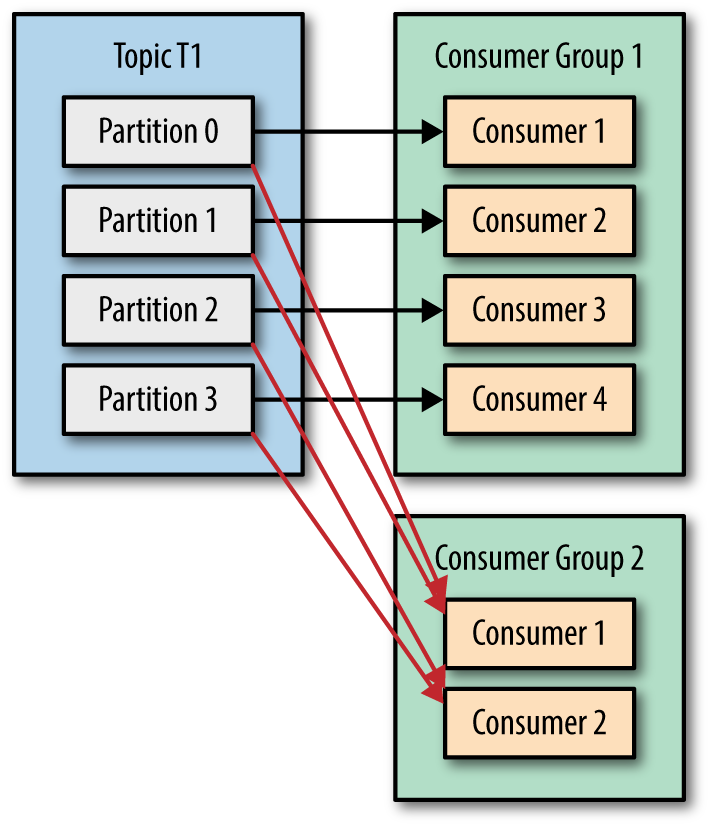
카프카는 위와 같은 구조로 되어 있다. 그리고 몇가지 중요한 포인트는 다음과 같다
- 오프셋은 Consumer Group당 그리고 Topic당 관리된다.
따라서 Consumer Group 이 다르면 Topic이 같아도 서로 각자 오프셋을 관리한다. - 파티션은 컨슈머 그룹내에서 오직 1개의 컨슈머에게만 배치 될 수 있다.
저 두번째 포인트가 매우매우 중요하다. 즉 컨슈머 그룹 내에서는 1개의 파티션은 1개의 컨슈머에게 배정된다. 그러니 다음과 같은 말도 성립한다.
- 한개의 컨슈머가 여러개의 파티션을 가질 수는 있다.
- 한개의 파티션이 여러개의 컨슈머에 배정될 수는 없다.
- 파티션의 갯수보다 컨슈머 그룹내 컨슈머의 갯수가 많으면, 유휴 컨슈머가 발생한다.
여기서 우리는 두가지 사실을 배울 수 있다.
- 파티션의 갯수는 항상 컨슈머 그룹의 컨슈머 갯수보다 많이 설정해야한다.
- 한개의 파티션은 항상 한개의 컨슈머가 담당한다(그 컨슈머 그룹에 한해서)
자 이 점을 명심하고, 계속 읽어보자
리밸런싱
만약 컨슈머중 하나가 장애가 난다면 어떻게 될까?
그렇다 그 컨슈머가 맡고 있는 파티션은 오직 그 컨슈머에 배정되었으므로, 그 파티션의 레코드들을 소비되지 않고 멈출 것이다.
카프카가 이를 감지하면 리밸런싱이라는 작업을 하게 된다.
리밸런싱이라는 작업은 쉽게 말하면, 컨슈머들에게 파티션을 다시 배정시켜준다는 것이다.
리밸런싱 중에는 컨슈머가 데이터를 읽지 못한다. 따라서 리밸런싱이 잦으면 성능에 매우 큰 문제를 일으키며, 이외에도 많은 위험성이 도사린다. 따라서 리밸런싱을 최소화하도록 해야한다.
커밋
커밋은 컨슈머가 poll()을 호출했을때 넘겨주기 시작할 번호를 기록한다.
즉 오프셋 6을 커밋하면 다음 poll() 때 컨슈머 쪽으로 6부터 데이터를 보내준다. 약간 TCP 랑 비슷한 느낌이다.
리밸런싱의 문제 상황
만약 이런 경우라면 어떨까? poll()을 통해 10개의 레코드를 가져온 상태에서, 6개째 처리하고 있는데, 리밸런싱이 일어난다면? 그리고 아직 커밋을 안한 상황이라면?
그러면 당연히 리밸런싱 후 그 파티션을 담당받은 컨슈머가 데이터를 중복해서 조회해서 처리를 시작할 것이다.
이는 큰 문제다.
따라서 다음 코드를 보면 어떻게 해결할지 좀 감을 잡을 수 있다.(완벽한 해결은 아닌거 같다. 맹목적 카피는 금지)
public class ReactToRebalance {
private static Logger logger = LoggerFactory.getLogger(ReactToRebalance.class.getName());
private static KafkaConsumer<String,String> consumer;
private static Map<TopicPartition, OffsetAndMetadata> currentOffsets;
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
try {
consumer = new KafkaConsumer<>(configs);
consumer.subscribe(List.of(TOPIC_NAME), new RebalanceListener()); //여기에 리밸런스 리스너를 넣어 준다.
currentOffsets = new HashMap<>();
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String,String> record : records){
logger.info("{}",record);
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, null)
//이렇게 +1을 해줌으로서 컨슈머 재시작시 파티션에서 가장 마지막 값을 기준으로 레코드를 읽기 시작한다.
);
consumer.commitSync(currentOffsets);
/*
컨슈머가 리밸런싱 동안에는 데이터를 읽지 못한다.
따라서 컨슈머 재 시작시
*/
}
}
} finally {
consumer.close();
}
}
private static class RebalanceListener implements ConsumerRebalanceListener {
//리밸런싱이 이루어지기 직전에 호출된다.
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
logger.warn("Partitions are revoked");
//리밸런싱이 이루어 지기 적전에 커밋을 해준다.
consumer.commitSync(currentOffsets);
currentOffsets.clear();
}
/*
리밸런싱이 진행되는 동안에는 컨슈머 그룹 내의 컨슈머 들이 토픽의 데이터를 읽지 못한다.
*/
//리밸런싱이 완료된 후에 호출된다.
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
logger.warn("Partitions are assigned");
}
}
}
위 코드에서는 ConsumerRebalanceListener라는 인터페이스를 구현하여 사용하였는데, onPartitionsRevoked의 경우 리밸런싱이 이루어지기 직전에 호출되게 된다.
여기에 커밋을 하는 코드를 넣어서, 리밸런싱 이후 다음 컨슈머가 이 파티션의 값을 가져가려고 할때, 내가 처리한 그 다음 레코드 부터 가져가도록 할 수 있다.
그리고 저 Map을 지워주지 않으면 이후에도 계속해서 이전 데이터가 오프셋에 덮어 씌워지므로 주의하자.
https://blog.voidmainvoid.net/264
이건 책에 나오지 않았는데, 내 생각에는, 리밸런싱이 일어난다면, 저 for 루프를 탈출해야하는것이 아닌가? 라는 생각이 든다. 왜냐하면, 리밸런싱 이후에는 다음 배정받은 컨슈머가 레코드를 처리하기 시작할텐데, 그러면 내가 커밋한 이후의 데이터는 처리하면 안되는게 아닌가 싶다.
따라서 내 생각에 제대로 구현하려면 다음과 같은 흐름이어야하지 않나 싶다.
for (record : records) {
value = currentOffset.put();
if (value == null) break; // put 이전에 이미 리밸런싱 사전작업 끝남
//이 데이터에 대한 작업
if (rebalancing started) break
}이 또한 완벽하지 않고, 이제 저 콜백 함수가 별도 쓰레드에서 진행되는건지, 또 동기화는 어떻게 할지 원자적으로 실행해야하는거라던지, 좀더 고려해 보아야할 것 같다.
