[Kafka]
1.[Kafka] 리밸런싱 발생시 중복 처리 방지하는 법
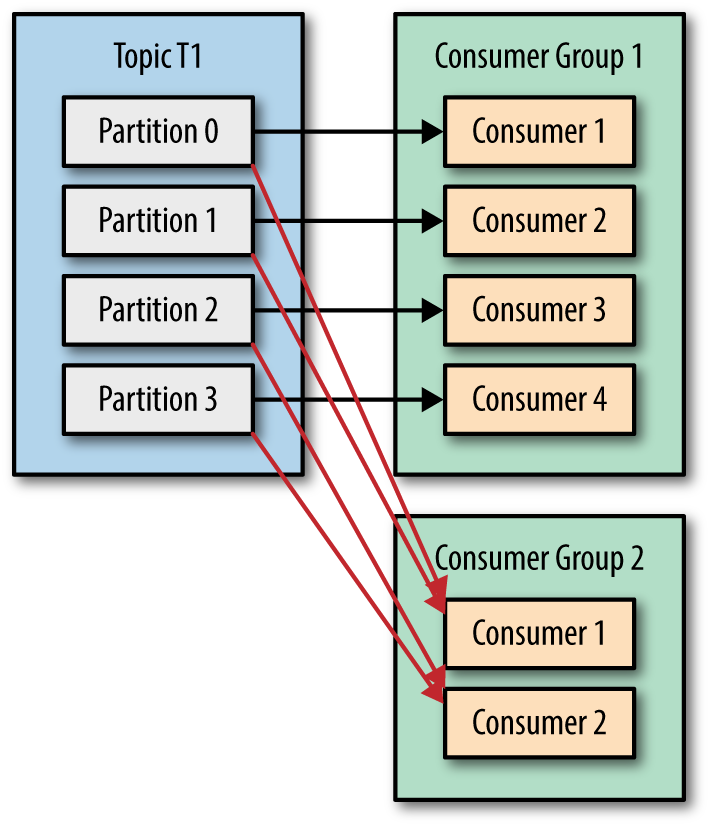
카프카 책을 보며, 헷갈렸던 점을 정리해 놓는다.우선 헷갈리지 않으려면 개념이 중요하다.카프카는 위와 같은 구조로 되어 있다. 그리고 몇가지 중요한 포인트는 다음과 같다오프셋은 Consumer Group당 그리고 Topic당 관리된다.따라서 Consumer Group
2.[Kafka] ConsumerRebalanceListener의 올바른 구현

이 글에서는 공식 Java Doc을 기반으로 ConsumerRebalanceListener에 대해 자세히 알아보고 어떻게 구현해야하는지 공부한다.책에는 간단하게 커밋을 하는 것으로 구현하였지만, 많은 의문점이 생겼다.(커밋만 하고, 아직 남은 레코드는 처리해도 되는건지
3.[Kafka] KafkaConsumer 자세히 알아보기
시작 이번 글에서는 저번 글에 이어서, KafkaConsumer의 JavaDoc을 읽고, 해석하고 요약해보겠다. >컨슈머를 구현하다가, 한개의 poll()당 수동 커밋을 하는 방식에서, 최대한 지연 커밋을 하고, 리밸런싱 이벤트가 발생했을 때만 커밋을 하는 것이 가능
4.[Kafka] 삽질 기록 - KafkaStreams try-with-resource 사용금지!!
간단하게 설명하지만, 이것을 발견하려고 얼마나 생쇼를 했는지 누구도 모를 것이다.집에 있는 서버로 띄워보고 로컬으로 띄워보고, 카프카, 주키퍼 로그를 다 읽어보고, 에러를 구글에 검색해도, 해결이 되지 않았다.위 코드에서 이상한 점을 찾을 수 있겠는가? 그렇다.. 책의
5.[Docker,Kafka] docker-compose 로 간단하게 카프카 띄우기
여기 저기에 카프카를 띄울 때 마다, wget 해서 환경 변수 설정하고, 설정바꾸고, 엄청 번거로웠다.마침 오라클 클라우드를 사용하다가 뭔가 자꾸 막혀서 도커를 사용해보았더니, 정말 엄청 편리했다.나의 설정 같은 경우 1MB 메모리를 가진 저렴한 서버에 띄우다 보니 저