13. 웹 애플리케이션과 영속성 관리
트랜잭션 범위의 영속성 컨텍스트
스프링 컨테이너의 기본 전략
- 스프링 컨테이너는 트랜잭션이 시작할 때 영속성 컨텍스트를 생성하고
트랜잭션이 끝날 때 영속성 컨텍스트를 종료한다. - 같은 트랜잭션 안에서는 항상 같은 영속성 컨텍스트에 접근한다.
@Transactional이 있으면 해당 메서드가 실행되기 전에트랜잭션 AOP가 먼저 동작한다.
@Controller
class HelloController {
@Autowired HelloService helloService;
public void hello(){
Member member = helloService.logic(); // 반환된 Member 엔티티는 준영속 상태
}
}
@Service
class HelloService {
@PersistenceContext
EntityManager em;
@Autowired Repository1 repository1;
@Autowired Repository2 repository2;
// 메소드를 호출할 때 트랜잭션을 먼저 시작
@Transactional
public void logic() {
repository1.hello();
// member는 영속상태 : 현재 트랜잭션 범위 안에 있으므로 영속성 컨텍스트의 관리를 받는다.
Member member = repository2.findMember();
return member;
}
// 트랜잭션 종료 : 트랜잭션 커밋, 영속성 컨텍스트 종료, 조회한 member는 이제부터 준영속 상태
}
@Repository
class Repository1 {
@PersistenceContext
EntityManager em;
public void hello(){
em.xxx(); // 영속성 컨텍스트 접근
}
}
@Repository
class Repository2 {
@PersistenceContext
EntityManager em;
public void findMember(){
return em.find(Member.class, "id1"); // 영속성 컨텍스트 접근
}
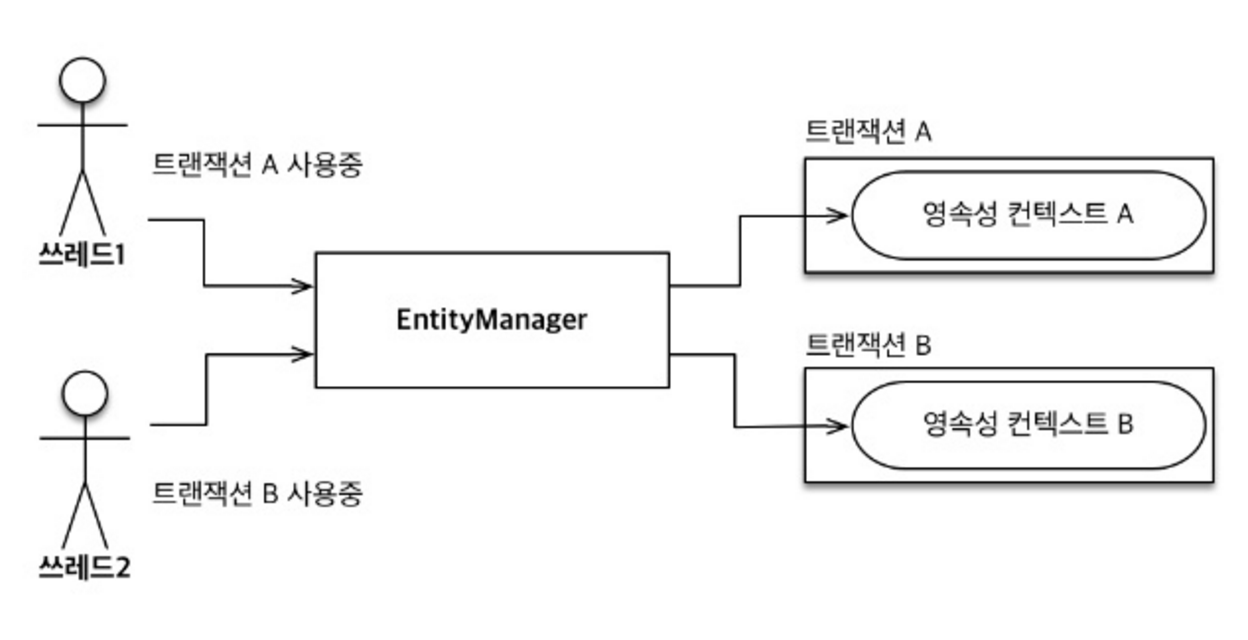
}트랜잭션이 같으면 같은 영속성 컨텍스트에 접근한다.
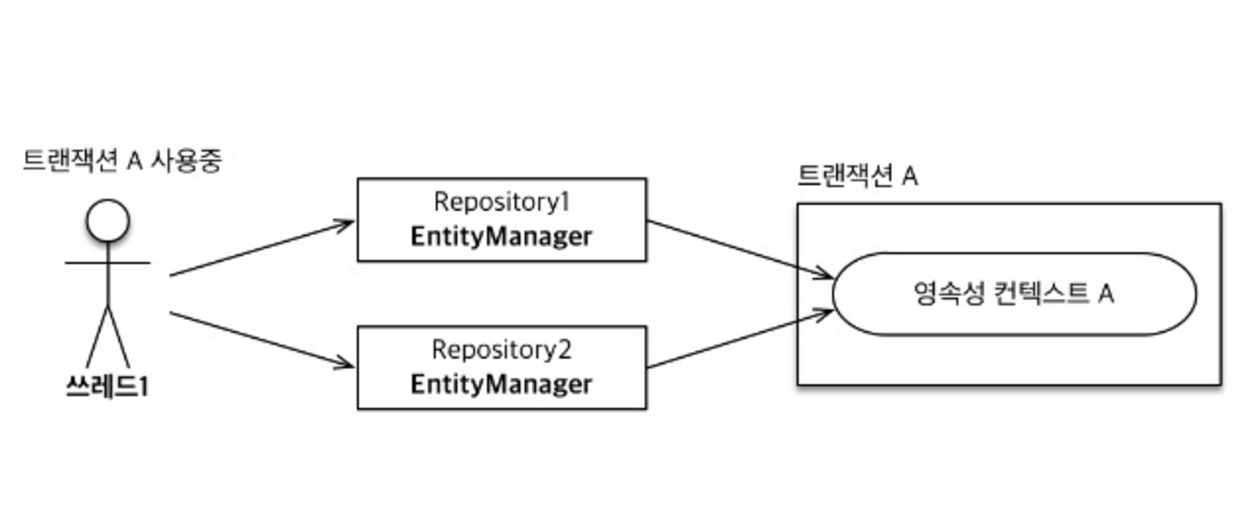
트랜잭션이 다르면 다른 영속성 컨텍스트에 접근한다.
- 같은 엔티티 매니저를 사용해도 트랜잭션이 다르기 때문에 다른 영속성 컨텍스트 사용
- 즉, 이렇게 되면 멀티 스레드 환경에서 스프링 컨테이너는 각 스레드마다 각각의 트랜잭션을 할당해주고 영속성 컨텍스트 또한 각각 배정하게 된다.
- 스프링 컨테이너는 복잡한 트랜잭션 처리를 해준다. 따라서 개발자는 비즈니스 로직에 집중할 수 있게 된다.
준영속 상태와 지연 로딩
서비스 계층에서 트랜잭션을 걸게되면 서비스 로직이 끝나는 시점에 트랜잭션이 종료되면서 영속성 컨텍스트도 함께 종료된다.
따라서, 조회한 엔티티가 서비스나 리포지토리 계층에서는 영속 상태로 관리가 되지만, 컨트롤러나 뷰 같은 프리젠테이션 계층에서는 준영속 상태가 된다.
- 현재
Order와Member는ManyToOne에 지연로딩이 걸려있는 상태 - 이때,
Order객체는 준영속 상태이기 때문에 지연로딩이나 변경감지가 작동하지 않는다.- 변경감지는 무분별한 데이터 변경을 방지하기 위해 프리젠테이션 영역에서는 못하는게 당연하다.
order.getMember()로 조회한Member객체는 프록시 객체이다.member.getName()으로 초기화를 시도하지만, 준영속 상태이기 때문에 지연로딩이 작동하지 않고
값을 불러오지 못해 예외가 발생한다.
class OrderController {
public String view(Long orderId) {
Order order = orderService.findOne(orderId);
Member member = order.getMember();
member.getName(); //지연 로딩 시 예외 발생
}
}글로벌 페치 전략 수정
- 지연로딩 → 즉시로딩
Order를 불러올 때 연관된Member도 실제 객체로 함께 불러온다.
@Entity
public class Order{
@Id @GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.EAGER)
private Member member; // 주문 회원
}
Order order = orderService.findOne(orderId);
Member member = order.getMember();
member.getName(); //이미 로딩된 엔티티즉시 로딩 사용 시 단점
- 사용하지 않는 엔티티를 로딩한다.
- 화면 A에서는
order와member가 모두 필요할 수 있지만, 화면 B에서는order만 필요할 수 있다. - 따라서 화면 B는 의미 없는
member까지 같이 호출해야 하는 상황이 발생한다.
- 화면 A에서는
- N+1 문제가 발생한다.
-
JPA를 사용하면서 가장 조심해야 할 성능 이슈 (최우선 최적화 대상)
-
order를 엔티티 매니저를 통해 조회했을 때는join을 통해 하나의 쿼리로 조회한다. -
하지만,
JPQL을 통해 조회하면JPQL은 글로벌 페치 전략을 참고하지 않고SQL을 생성하기 때문에
일단order에 대한 쿼리만 생성 -
Order.member의 전략이 즉시 로딩이므로order를 로딩하는 즉시 연관된member도 로딩해야 함. -
연관된
member를 영속성 컨텍스트에서 찾고 없으면 조회 쿼리를 날린다. -
이때, 조회 쿼리를
order수만큼 날리는 문제가 발생한다.Order order = em.find(Order.class, 1L); //SQL select o.*, m.* from Order o left outer join Member m on o.MEMBER_ID=m.MEMBER_ID where o.id = 1 ------------------------------------------------------------------------ List<Order> orders = em.createQuery("select o from Order o", Order.class) .getResultList(); //SQL select * from Order // JPQL로 실행된 SQL select * from Member where id = ? // EAGER로 실행된 SQL select * from Member where id = ? // EAGER로 실행된 SQL select * from Member where id = ? // EAGER로 실행된 SQL select * from Member where id = ? // EAGER로 실행된 SQL
-
JPQL 페치 조인
- 페치 조인을 사용하면
SQL JOIN을 사용해서 페치 조인 대상까지 함께 조회한다. - 따라서, N+1 문제를 해결할 수 있다.
- 단점
- 무분별하게 사용하면 화면에 맞춘 리포지토리 메소드가 증가할 수 있다.
- 결국, 프리젠테이션 계층이 알게 모르게 데이터 접근 계층을 침범하게 된다.
- 무분별한 최적화로 프리젠테이션 계층과 데이터 접근 계층 간에 의존관계가 급격하게 증가하는 것보다는
적절한 선에서 타협점을 찾는 것이 합리적이다.
JPQL:
select o
from Order o
join fetch o.member
SQL:
select o.*, m.*
from Order o
join Member m on o.MEMBER_ID = m.MEMBER_ID강제로 초기화
- 영속성 컨텍스트가 살아있을 때 프리젠테이션 계층이 필요한 엔티티를 강제로 초기화해서 반환하는 방법
member.getName()처럼 실제 값을 호출하는 시점에 초기화가 된다.- 프록시를 초기화하는 역할을 서비스 계층이 담당하면 뷰가 필요한 엔티티에 따라 서비스 계층의 로직을 변경해야 한다.
- 프리젠테이션 계층이 서비스 계층을 침범하는 상황
class OrderService{
@Transactional
public Order findOrder(id){
Order order = orderRepository.findOrder(id);
order.getMember().getName(); //프록시 객체를 강제로 초기화
return order;
}
}FACADE 계층 추가
프리젠테이션 계층과 서비스 계층 사이에 파사드 계층을 하나 더 두는 방법
뷰를 위한 프록시 객체 초기화는 이곳에서 담당한다.
파사드 계층을 도입해서 프리젠테이션 계층과 서비스 계층 사이의 논리적 의존성을 분리할 수 있다.
- 서비스 계층을 호출해서 비즈니스 로직을 실행한다.
- 실용적인 관점에서 볼 때 단점은 중간에 계층이 하나 더 끼어든다는 점이다.
- 결국 더 많은 코드를 작성해야 한다.
class OrderFacade {
@Autowired OrderService orderService;
public Order = orderService.findOrder(id);
// 프레젠테이션 계층이 필요한 프록시 객체를 강제로 초기화
order.getMember().getName();
return order;
}
class OrderService{
public Order findOrder(id){
return ordeRepository.findOrder(id);
}
}준영속 상태와 지연 로딩의 문제점
뷰를 개발할 때 필요한 엔티티를 미리 초기화 해두는 방법은 생각보다 요류가 발생할 가능성이 높다.
왜냐하면, 필요한 엔티티가 초기화된 상태인지 아닌지 확인하는 것은 상당히 번거롭고 놓치기 쉽기 때문이다.
OSIV (Open Session In View)
영속성 컨텍스트를 뷰까지 열어둔다는 뜻이다.
이렇게 되면 뷰에서도 지연 로딩을 사용할 수 있다.
과거 OSIV : 요청 당 트랜잭션
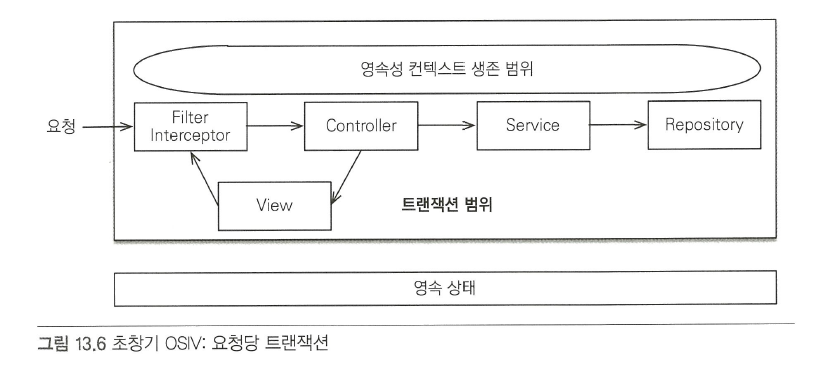
- 서블릿 필터나 스프링 인터셉터에서 트랜잭션을 시작하고 요청이 끝날 때 트랜잭션도 끝내는 방식
- 컨트롤러나 뷰 같은 프리젠테이션 계층에서 엔티티를 변경할 수 있다는 문제점이 있다.
- 프리젠테이션 계층에서 엔티티를 수정하지 못하게 막는 방법
- 프리젠테이션 계층에 엔티티를 읽기 전용 인터페이스로 제공
- 프리젠테이션 계층에 엔티티의 읽기 메소드만 제공하는 레핑 객체 반환
- DTO만 반환
- 위의 방식들은 모두 코드량이 상당히 증가한다는 단점이 있다.
스프링 OSIV : 비즈니스 계층 트랜잭션
위의 방식에서 단점을 보완해 비즈니스 계층에서만 트랜잭션을 유지하는 방식의 OSIV
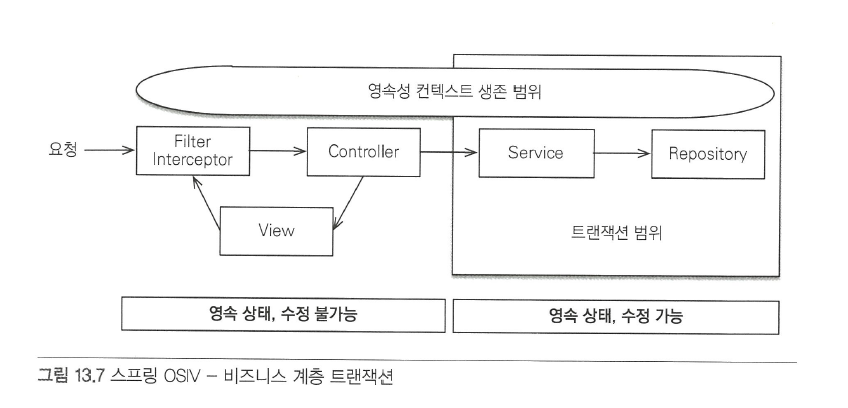
- 클라이언트의 요청이 들어오면 서블릿 필터나, 스프링 인터셉터에서 영속성 컨텍스트 생성 (트랜잭션 X)
- 서비스 계층에서
@Transactional로 트랜잭션을 시작할 때 미리 생성해둔 영속성 컨텍스트를 찾아와서
트랜잭션을 시작한다. - 서비스 계층이 끝나면 트랜잭션을 커밋하고 영속성 컨텍스트를 플러시한다. (영속성 컨텍스트 종료 X)
- 컨트롤러와 뷰까지 영속성 컨텍스트가 유지되므로 조회한 엔티티는 여전히 영속 상태
- 서블릿 필터나, 스프링 인터셉터로 요청이 돌아오면 영속성 컨텍스트 종료 (이때, 플러시 호출 X)
- 영속성 컨텍스트는 트랜잭션 밖에서 엔티티를 조회할 수 만 있다. 이것을 트랜잭션 없이 읽기라고 한다.
- 이를 이용하면, 프리젠테이션 계층에서 지연 로딩을 사용할 수 있다.
스프링 OSIV 주의사항
- 프리젠테이션 계층에서 엔티티를 수정한 직후에 서비스 계층에서 트랜잭션을 시작하면 문제가 발생한다.
- 트랜잭션 AOP가 동작하면서 변경 감지를 수행하기 때문에 수정 사항이 db에 적용되게 된다.
- 따라서, 컨트롤러에서는 비즈니스 로직을 모두 호출하고나서 엔티티를 변경하면 된다.
class MemberController {
public String viewMember(Long id) {
Member member = memberService.getMember(id);
member.setName("XXX"); // 보안상의 이유로 고객 이름을 XXX로 변경했다.
memberService.biz(); // 비즈니스 로직
return "view";
}
}
class MemberService {
@Transactional
public void biz() {...}
}OSIV 정리
스프링 OSIV의 특징
- 한 번 조회한 엔티티는 요청이 끝날 때까지 영속 상태를 유지한다.
- 엔티티 수정은 트랜잭션이 있는 계층에서만 동작한다.
스프링 OSIV의 단점
- OSIV를 적용하면 같은 영속성 컨텍스트를 여러 트랜잭션이 공유할 수 있다는 점을 주의해야 한다.
- 프리젠테이션 계층에서 엔티티를 수정 하고나서 비즈니스 로직을 수행하면 엔티티가 수정될 수 있다.
- 프리젠테이션 계층에서 지연 로딩에 의한 SQL이 실행된다.
- 따라서 성능 튜닝시에 확인해야 할 부분이 넓다.
OSIV vs FACADE vs DTO
- OSIV를 사용하지 않는 대안은 FACADE 계층이나 그것을 조금 변형해서 사용하는 방법이 있는데 어떤 방법을 사용하든 준영속 상태가 되기 전에 프록시를 초기화해야 하는 단점이 있다.
OSIV를 사용하는 방법이 만능은 아니다
- OSIV를 사용하면 화면을 출력할 때 엔티티를 유지하면서 객체 그래프를 마음껏 탐색할 수 있다.
- 하지만 복잡한 화면을 구성할 때는 이 방법이 효과적이지 않은 경우가 많다.
- 엔티티를 직접 조회하기보다는 JPQL로 필요한 데이터들만 조회해서 DTO로 반환하는 것이 더 나은 해결책일 수 있다.
너무 엄격한 계층
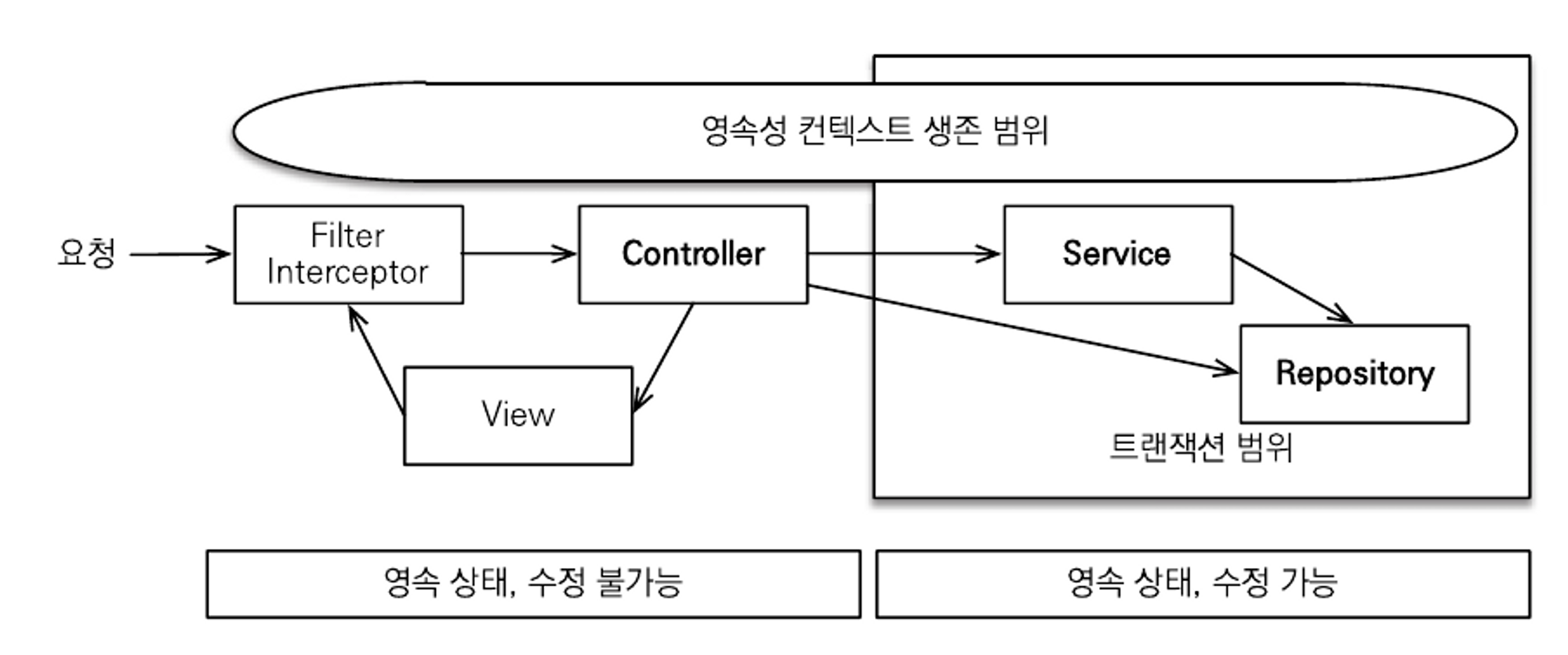
- OSIV를 사용하기 전에는 프레젠테이션 계층에서 사용할 지연 로딩된 엔티티를 미리 초기화해야 했다. 그리고 초기화는 서비스 계층이나 FACADE 계층이 담당했다.
- OSIV를 사용하게 되면 영속성 컨텍스트가 프레젠테이션 계층까지 살아있으므로 미리 초기화 할 필요가 없으므로 단순한 엔티티 조회는 컨트롤러에서 Repository를 호출해도 상관 없다.
14. 컬렉션과 부가 기능
컬렉션
JPA와 컬렉션
- 하이버네이트는 엔티티를 영속상태로 만들 때 컬렉션 필드를 하이버네이트에서 준비한 컬렉션으로 감싸서
사용한다.
- Collection, List → PersistentBag
- Set → PersistentSet
- List + @OrderColumn → PersistentList - 이는 하이버네이트가 컬렉션을 효율적으로 관리하기 위함이다.
- 하이버네이트는 원본 컬렉션을 감싸고 있는 내장 컬렉션을 생성해서 이 내장 컬렉션을 사용하도록 참조를
변경한다. - 하이버네이트는 이런 특징 때문에 컬렉션 사용 시 즉시 초기화해서 사용하는 것을 권장한다.
Collection<Member> members = new ArrayList<>();
Collection, List
- 중복을 허용하는 컬렉션
- PersistentBag을 래퍼 컬렉션으로 사용한다.
- ArrayList로 초기화해주면 된다.
- 엔티티를 추가할 때 중복 검사를 안하고 바로 추가하기 때문에 지연 로딩된 컬렉션을 초기화하지 않는다.
@OneToMany(mappedBy = "parent")
Collection<Child> children = new ArrayList<>();
//또는
@OneToMany(mappedBy = "parent")
List<Child> children = new ArrayList<>();Set
- 중복을 허용하지 않는 컬렉션
- PersistentSet을 컬렉션 래퍼로 사용
- HashSet으로 초기화해주면 된다.
- 엔티티를 추가할 때 중복된 엔티티가 있는지 확인해야 하므로 지연 로딩된 컬렉션을 초기화한다.
@OneToMany(mappedBy = "parent")
Set<Child> children = new HashSet<>();List + @OrderColumn
- List 인터페이스에
@OrderColumn을 추가하면 순서가 있는 특수한 컬렉션으로 인식한다. - 순서가 있다는 말은 데이터베이스에 순서 값을 저장해서 조회할 때 사용한다는 의미다.
PersistentList를 사용한다.@OrderColumn(name = "POSITION")- JPA는 List의 위치 값을 테이블의
POSITION컬럼에 보관한다. - 하지만 일대다 관계이므로
POSITION컬럼은Comment테이블에 매핑된다.
- JPA는 List의 위치 값을 테이블의
@Entity
class Board{
@Id @GeneratedValue
private Integer id;
@OneToMany(mappedBy = "board")
@OrderColumn(name = "POSITION")
private List<Comment> comments = new ArrayList<>();
}
@Entity
class Comment{
@Id @GeneratedValue
private Integer id;
@ManyToOne
@JoinColumn(name = "BOARD_ID")
private Board board;
}@OrderColumn의 단점
@OrderColumn은Board엔티티에서 매핑하므로Comment는POSITION의 값을 알 수 없다.List를 변경하면 연관된 많은 위치 값을 변경하기 위한 추가 쿼리 발생- 중간에
POSITION값이null이면 컬렉션을 순회할 때NullPointerException발생
@OrderBy
- 데이터베이스의 order by 절을 사용해서 컬렉션을 정렬한다.
- 따라서 순서용 컬럼을 매핑하지 않아도 된다.
- 모든 컬렉션에 사용 가능하다.
- 엔티티의 필드를 대상으로 한다.
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
@OrderBy("username desc, id asc")
private Set<Member> members = new HashSet<Member>();
...
}@Converter
- 컨버터를 사용하면 엔티티의 데이터를 변환해서 데이터베이스에 저장 가능하다.
boolean타입 필드를 데이터베이스에 숫자 대신 Y, N 으로 저장할 수 있다.- 단, 매핑할 컬럼이
varchar타입이어야 한다.
- 단, 매핑할 컬럼이
@Entity
public class Member {
@Id
private String id;
private String username;
@Convert(converter=BooleanToYNConverter.class)
private boolean vip;
...
}
AttributeConverter<from, to>를 구현해야 한다.convertToDatabaseColumn()- 엔티티의 데이터를 데이터베이스 컬럼에 저장할 데이터로 변환한다.
convertToEntityAttribute()- 데이터베이스에서 조회한 컬럼 데이터를 엔티티의 데이터로 변환한다.
@Converter
class BooleanToYNConverter implements AttributeConverter<Boolean, String>{
@Override
public String convertToDatabaseColumn(Boolean attribute){
return (attribute != null && attribute) ? "Y" : "N";
}
@Override
public Boolean convertToEntityAttribute(String dbData){
return "Y".equals(dbData);
}
}글로벌 설정
- 모든 Boolean 타입에 컨버터를 적용하려면
@Converter(autoApply = true)를 적용한다. - 이렇게 하면 모든 Boolean 타입에 자동으로 컨버터가 적용된다.
@Converter(autoApply = true)
class BooleanToYNConverter implements AttributeConverter<Boolean, String>{
// ...
}리스너
이벤트 종류
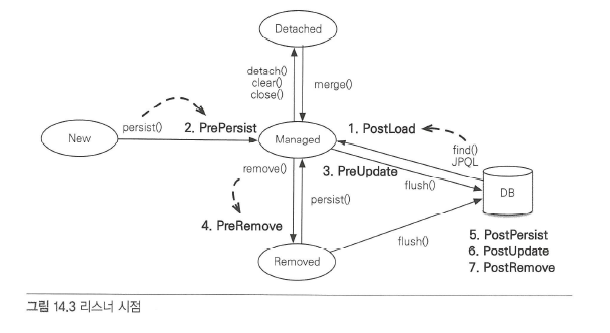
PostLoad- 엔티티가 영속성 컨텍스트에 조회된 직후 또는
refresh를 호출한 후(2차 캐시에 저장되어 있어도 호출된다.)
- 엔티티가 영속성 컨텍스트에 조회된 직후 또는
PrePersistpersist()메소드를 호출해서 엔티티를 영속성 컨텍스트에 관리하기 직전에 호출된다.
PreUpdateflush나commit을 호출해서 엔티티를 데이터베이스에 수정하기 직전에 호출된다.
PreRemoveremove()메소드를 호출해서 엔티티를 영속성 컨텍스트에서 삭제하기 직전에 호출된다. 또한 삭제
명령어로 영속성 전이가 일어날 때도 호출된다.orphanRemoval에 대해서는flush나commit
시에 호출된다.
PostPersistflush나commit을 호출해서 엔티티를 데이터베이스에 저장한 직후에 호출된다. 식별자가 항상 존재한다. 참고로 식별자 생성 전략이IDENTITY면 식별자를 생성하기 위해persist()를 호출하면서
데이터베이스에 해당 엔티티를 저장하므로 이때는persist()를 호출한 직후에 바로PostPersist가 호출된다.
PostUpdateflush나commit을 호출해서 엔티티를 데이터베이스에 수정한 직후에 호출된다.
PostRemoveflush나commit을 호출해서 엔티티를 데이터베이스에 삭제한 직후에 호출된다.
이벤트 적용 위치
- 엔티티에 직접 적용
-
엔티티에 이벤트가 발생할 때마다 어노테이션으로 지정한 메소드가 실행된다.
@Entity public class Member { @Id @GeneratedValue @Column(name = "MEMBER_ID") private Long id; private String name; @PostLoad public void PostLoad(){ System.out.println("PostLoad"); } @PrePersist public void prePersist(){ System.out.println("prePersist"); } @PreUpdate public void PreUpdate(){ System.out.println("PreUpdate"); } @PreRemove public void PreRemove (){ System.out.println("PreRemove "); } @PostPersist public void PostPersist (){ System.out.println("PostPersist "); } @PostUpdate public void PostUpdate (){ System.out.println("PostUpdate "); } @PostRemove public void PostRemove(){ System.out.println("PostRemove "); } }
-
- 별도의 리스너 등록
-
리스너는 대상 엔티티를 파라미터로 받을 수 있다.
-
반환 타입은 void로 설정
@Entity @EntityListeners(DuckListener.class) public class Duck { ... } public class DuckListener { @PrePersist private void prePersist(Object obj) { ... } // 위와 같이 나머지 이벤트 오버라이딩 }
-
- 기본 리스너 사용
- xml에 default 리스너 등록
- 여러 리스너의 이벤트 호출 순서
- 기본 리스너 - 부모 클래스 리스너 - 리스너 - 엔티티
엔티티 그래프
- 엔티티를 조회할 때 연관된 엔티티를 함께 조회하려면 즉시 로딩 또는 fetch join을 사용한다.
- 즉시 로딩은 어플리케이션 전체에 영향을 주고 변경할 수 없으므로 잘 사용하지 않는다.
- 그래서 지연로딩에 연관된 엔티티도 함께 조회할 필요가 있을 때 fetch join을 사용한다.
- 하지만 페치 조인을 사용하면 같은 JPQL을 중복해서 작성하는 경우가 많다.
- 주문 조회
- 주문과 회원 조회
- 주문과 주문상품 조회
- 엔티티 그래프 기능을 사용하면 엔티티를 조회하는 시점에 함께 조회할 연관된 엔티티를 선택할 수 있다.
- 엔티티 그래프는 정적으로 정의하는 Named 엔티티 그래프와 동적으로 정의하는 엔티티 그래프가 있다.
Named 엔티티 그래프
name: 엔티티 그래프의 이름attributeNodes: 함께 조회할 속성 선택- 이때,
@NamedAttributeNode를 사용하고 그 값으로 함께 조회할 속성을 선택하면 된다.
- 이때,
@NamedEntityGraph(name = "Order.withMember", attributeNodes = {
@NamedAttributeNode("member")
})
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "MEMBER_ID")
private Member member;
}em.find()에서 엔티티 그래프 사용
- Named 엔티티 그래프를 사용하려면
em.getEntityGraph()를 통해서 찾아오면 된다. - 엔티티 그래프는 JPA의 힌트 기능을 사용해서 동작한다.
- 힌트의 키로
javax.persistence.fetchgraph사용, 값으로 찾아온 엔티티 그래프를 사용
EntityGraph graph = em.getEntityGraph("Order.withMember");
Map hints = new HashMap();
hints.put("javax.persistence.fetchgraph", graph);
Order order = em.find(Order.class, orderId, hints);subgraph
Order→OrderItem→Item과 같이 연달아서 엔티티 그래프를 조회할 경우 사용- 현재 상황은
Order → Member,Order → OrderItem,OrderItem → Item
@NamedEntityGraph(name = "Order.withAll", attributeNodes = {
@NamedAttributeNode("member"),
@NamedAttributeNode(value = "orderItems", subgraph = "orderItems")
},
subgraphs = @NamedSubgraph(name = "orderItems", attributeNodes = {
@NamedAttributeNode("item")
})
)
@Entity
public class Order {
...
}JPQL에서 엔티티 그래프 사용
setHint를 통해 힌트를 추가해주면 된다.
List<Order> resultList =
em.createQuery("select o from Order o where o.id = :orderId",
Order.class)
.setParameter("orderId", orderId)
.setHint("javax.persistence.fetchgraph", em.getEntityGraph("Order.withAll"))
.getResultList();동적 엔티티 그래프
- 엔티티 그래프를 동적으로 구성하려면
createEntityGraph()메소드를 사용하면 된다.
EntityGraph<Order> graph = em.createEntityGraph(Order.class);
graph.addAttributeNodes("member");
Map hints = new HashMap();
hints.put("javax.persistence.fetchgraph", graph);
Order order = em.find(Order.class, orderId, hints);
//subgraph 사용
EntityGraph<Order> graph = em.createEntityGraph(Order.class);
graph.addAttributeNodes("member");
Subgraph<OrderItem> orderItems = graph.addSubgraph("orderItems");
orderItems.addAttributeNodes("item");
Map hints = new HashMap();
hints.put("javax.persistence.fetchgraph", graph);
Order order = em.find(Order.class, orderId, hints);엔티티 그래프 정리
- ROOT에서 시작
- 엔티티 그래프는 항상 조회하는 엔티티의 루트에서 시작해야 한다.
- 이미 로딩된 엔티티
- 영속성 컨텍스트에 해당 엔티티가 이미 로딩되어 있으면 엔티티 그래프가 적용되지 않는다.
- fetchgraph, loadgraph 차이
fetchgraph는 지정한 속성만 함께 조회loadgraph는 지정한 속성뿐만 아니라 즉시로딩으로 설정된 연관관계도 함께 조회한다.
