개요
- 현재 목록 페이지의 페이징 처리를 무한 스크롤로 구현한 상황
- 40만개 데이터 기준 스크롤을 내렸을 때 약 2초정도의 딜레이가 발생했다.
- 기존의 offset 방식의 정렬을 no offset 방식으로 바꿔보기로 결정했다.
기존 offset 방식 쿼리 로그
//JPQL
select search
from Search search
order by search.sellDate desc;
//SQL
select s1_0.id,s1_0.area,s1_0.create_date,s1_0.image_link,s1_0.link,s1_0.modify_date,s1_0.price,s1_0.provider,s1_0.sell_date,s1_0.site_product,s1_0.title
from search s1_0
order by s1_0.sell_date desc
limit 24,12;
- sell_date 필드를 기준으로 내림차순으로 정렬
- 현재 위의 쿼리는 24번째 데이터부터 12개의 데이터를 추출한다.
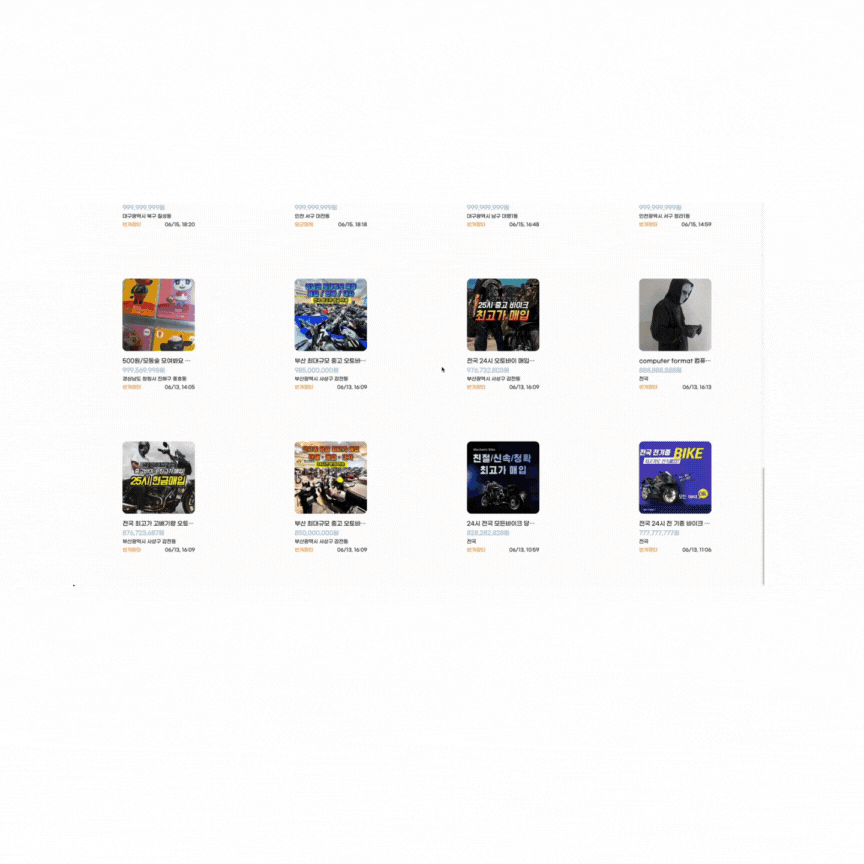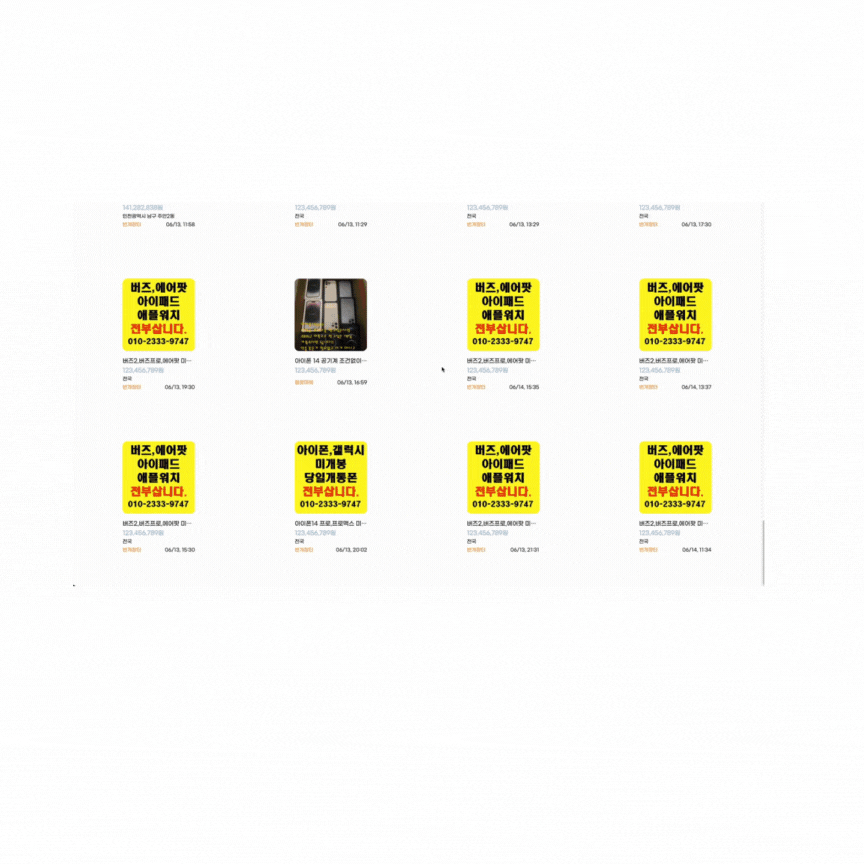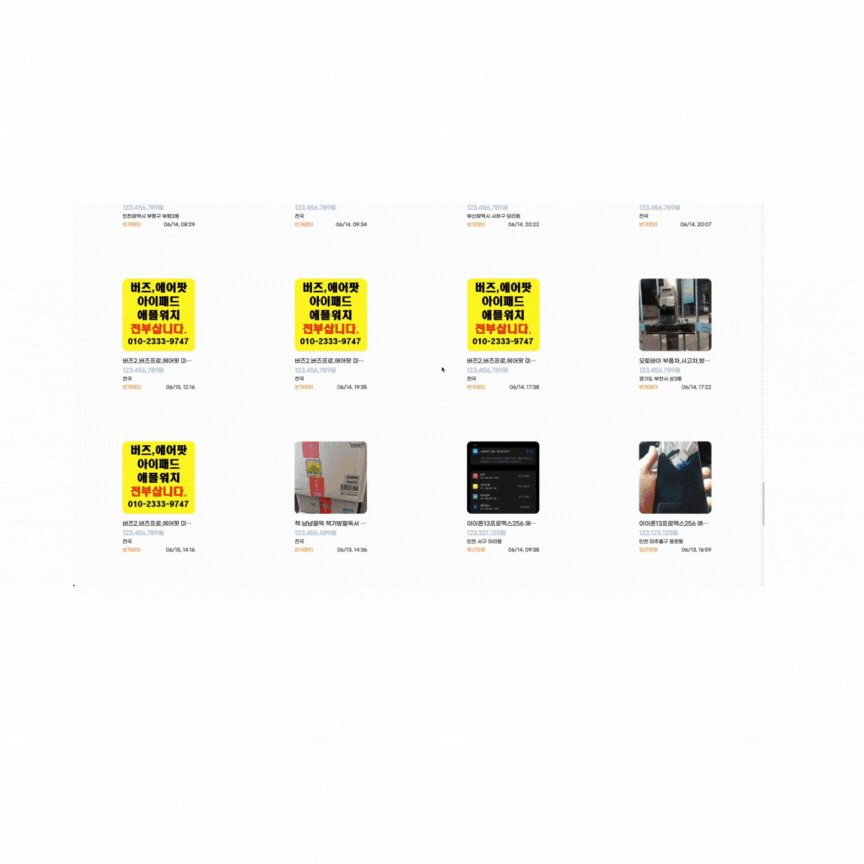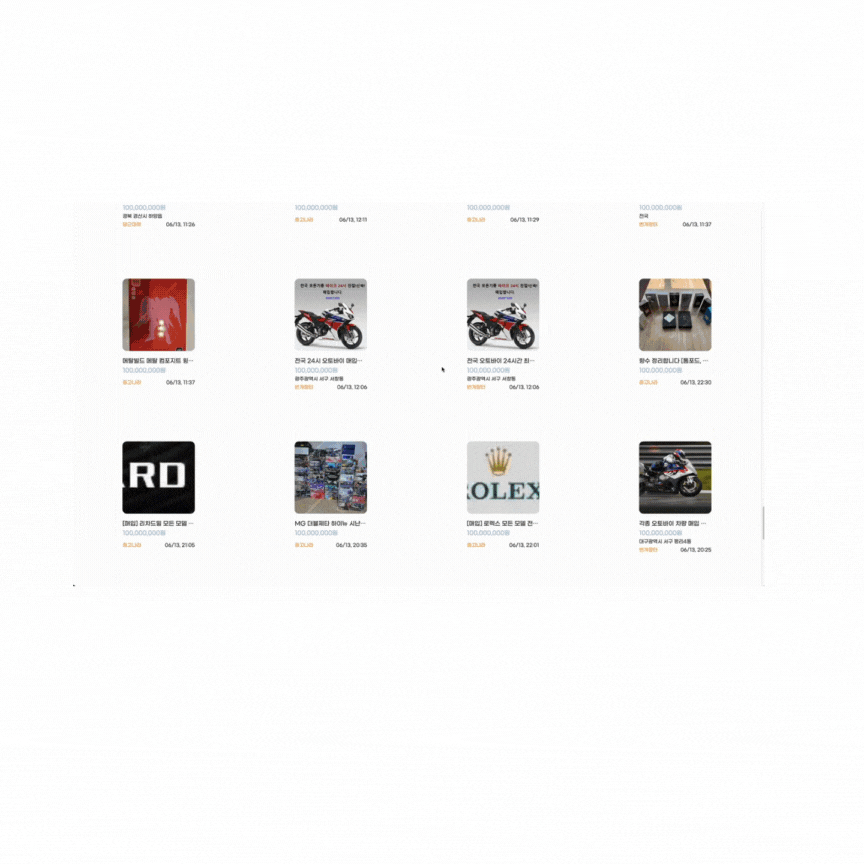
offset 방식은 이전까지의 데이터를 모두 스캔한 후 데이터를 뽑아오기 때문에 페이지가 뒤로갈수록 그만큼 스캔해야 할 이전의 데이터가 많아지며 처리 속도가 현저히 느려진다.
24번째 데이터를 시작점으로 12개를 뽑아오는 경우 (0.08초)


30만번째 데이터를 시작점으로 12개를 뽑아오는 경우 (1.92초)


이렇듯 offset 방식은 "몇번째 데이터부터 시작" 이란 offset 조건이 들어가기 때문에 인덱스가 적용되어 있어도 시작 데이터 이전까지 풀스캔을 해야 한다.
따라서, 몇번째 데이터이건 일관성있는 처리 속도를 보장하는 no offset 방식으로 변경했다.
no offset 적용 쿼리 로그
//JPQL
select search
from Search search
where search.sellDate < '2023-06-19T22:46:37.558+0900'
order by search.sellDate desc
//SQL
select s1_0.id,s1_0.area,s1_0.create_date,s1_0.image_link,s1_0.link,s1_0.modify_date,
s1_0.price,s1_0.provider,s1_0.sell_date,s1_0.site_product,s1_0.title
from search s1_0
where s1_0.sell_date<'2023-06-17 17:37:30.357912'
order by s1_0.sell_date desc
limit 12
- 몇번째 데이터를 시작점으로 정하는 것이 아닌, 이전 목록에서 마지막으로 뽑은 데이터의
sell_date보다 느린 날짜의 데이터를 뽑아서sell_date를 기준으로 내림차순으로 정렬한 후 12개의 데이터를 뽑아온다. sell_date에 인덱스를 걸어 놓았기 때문에 데이터베이스는sell_date보다 느린 날짜의 시작 데이터를 빠르게 추출할 수 있다.
no offset QueryDSL 적용
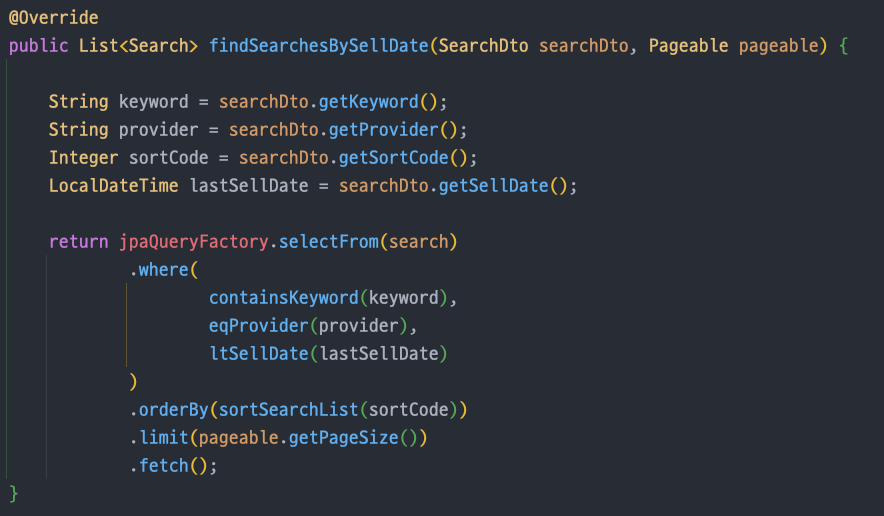
- 받아온
lastSellDate(마지막 상품의sellDate)보다 느린 날짜의 데이터들을 뽑아서 정렬하고pageable.getPageSize()만큼 추출한다.
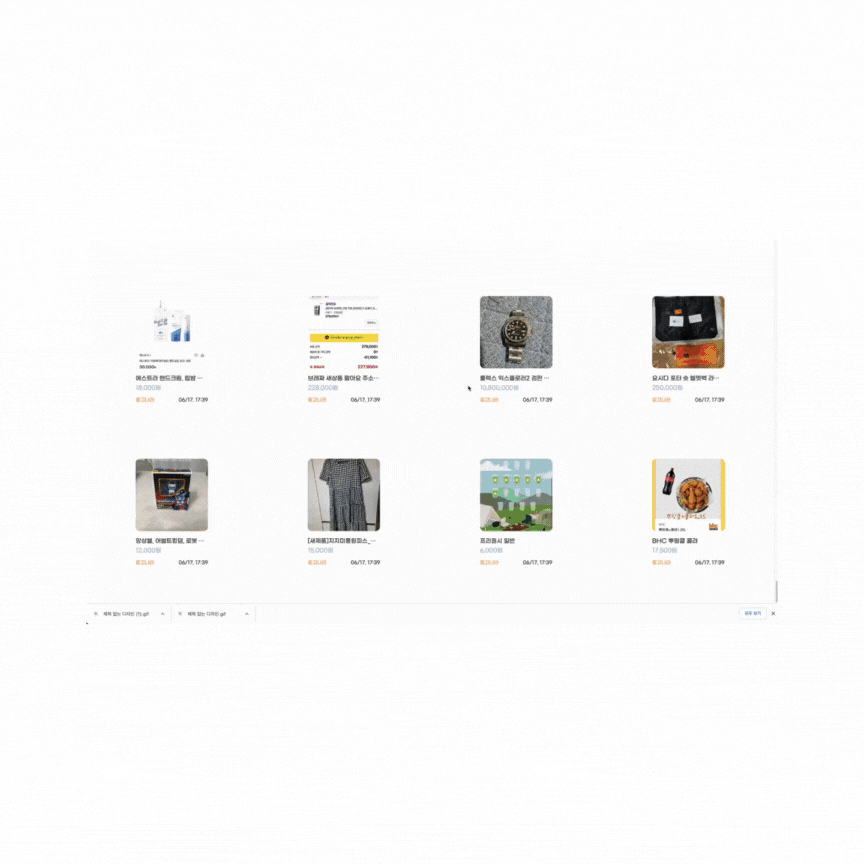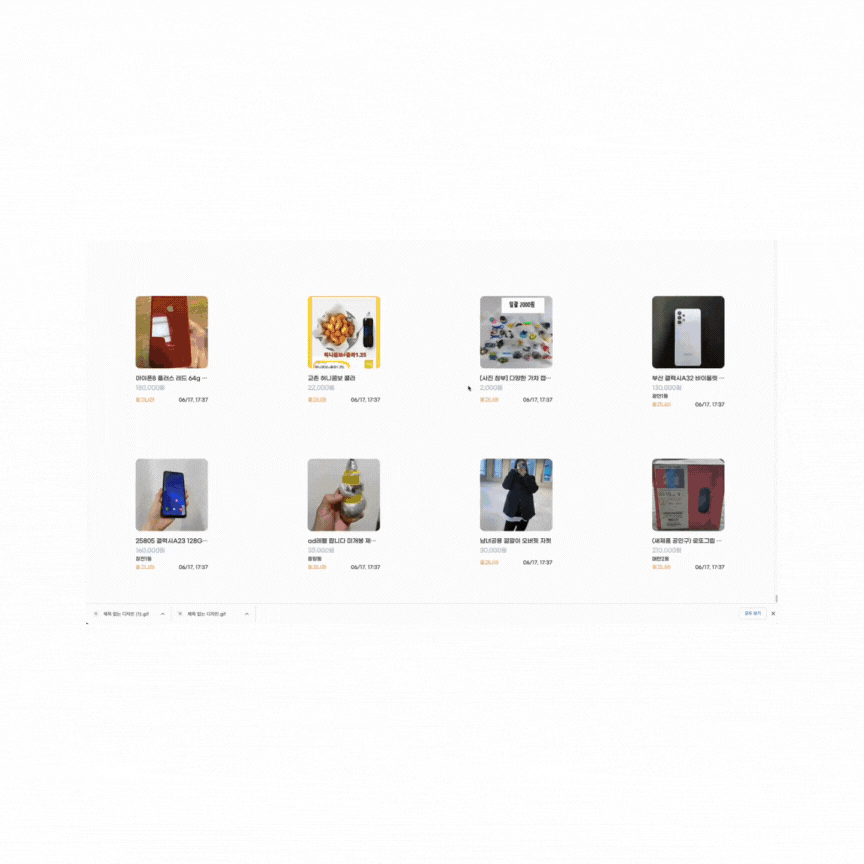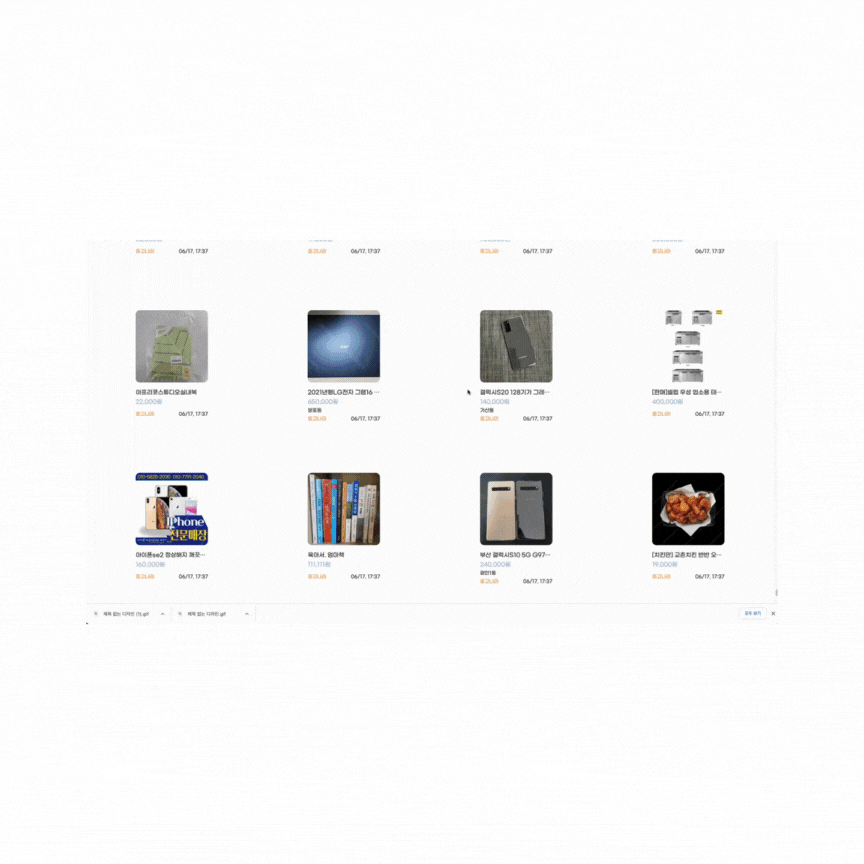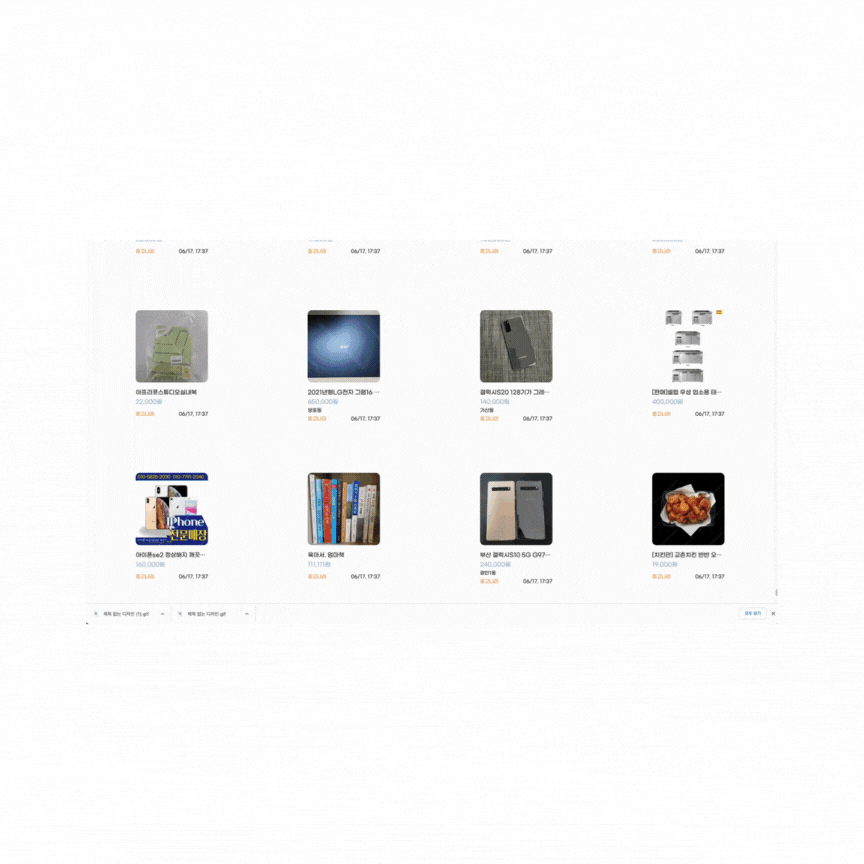
약 40만번 째 데이터를 뽑아오는 경우 (0.07초)


약 1000번 째 데이터를 뽑아오는 경우 (0.07초)


no offset 방식은 몇번째 데이터를 뽑아오건 일관성 있는 소요 시간을 보장한다.
offset 테스트
no offset 테스트

큰모래