Compile
- 전처리
- 컴파일
- 어셈블
- 링크
1. 전처리
- Preprocessor (=전처리기)로 컴파일 전에 코드를 적절한 상태로 준비하거나 처리하는 일
- 전처리 구문 =
#으로 시작하는 구문
하는 일
- 헤더 파일 불러오기
- 기호 상수 정의하여 필요한 내용 채워주기 등
종류
include
#include <stdio.h>Header Guard
- 한 번 불러온 파일은 두 번 불러오지 않는다
- 중복으로 인한 에러 방지
매크로 (=define)
- object like macro
#define 문자열 / 상수 // 단순화- function like macro
#define SUM(a, b) a + b - 하나의 Line만 사용
- 가독성을 위해 개행이 필요하면 `\` 사용
- `#`을 쓰면 해당 변수를 문자열로 처리
- `##`을 쓰면 문자열을 붙여 표현조건부 컴파일
#ifndef
만약 정의되어 있지 않으면 정의한다
#endif
#undef // 정의된 매크로를 해제
#ifdef // 정의되어 있으면
#ifndef // 정의되어 있지 않으면
#if // 정의된 값이 참이면
#else // if 에 걸리지 않았다면
#elif // 정의된 값이 '이것'이라면
#endif // if 끝!
#if 0
코드 disable
preprocessor 단계에서 제거됨
#endif2. 컴파일
- Compiler (=컴파일러)가 고수준 언어를 저수준 언어로 나타내는 일
- 소스(.c) 프로그램을 목적(object) 프로그램으로 변환하는 작업
- 컴파일 오류는 문법 오류로 소스 파일 수정 필요
3. 어셈블
- Assembler (=어셈블러)가 어셈블리어를 기계어로 바꿔주는 일
- 오브젝트 파일을 생성
4. 링크
- Linker (=링커)가 여러 오브젝트 파일을 하나로 합치거나 라이브러리와 합치는 일
- 목적 프로그램을 라이브러리와 연결하여 실행 프로그램(.exe)을 작성
포인터
개념
포인터 변수를 줄여서 포인터라고 함
메모리 주소를 보관하는 변수
변수 값과 주소
배열의 시작 = "메모리 영역"의 위치 (주소)
주소는 1Byte 단위를 사용하며 4 byte 를 사용하는 int 는 주소를 4칸 사용
배열과 포인터 관계
포인터가 배열을 가리킬 때
배열처럼 사용 가능
배열 != 포인터
포인터 변수의 이름: 주소를 저장하는 공간의 값
배열의 이름: 배열의 시작 메모리 영역의 주소
const 포인터
가리킨 곳의 값을 변경할 수 없음
문자열 초기화
char v[4] = “ABC”
배열을 하나 만들고 네 글자를 삽입하는 방식
const char *v = “ABC”
- 읽기 전용 메모리 공간에 “ABC”를 넣는다
- 지역 변수 v를 하나 만든다
- v가 첫 번째 칸을 가리키도록 한다
문자열 배열
// 초기화 방법 1
char vs[3][6] = {"ABCDE", "BTS", "KK"};
// 초기화 방법 2
// 읽기 전용 메모리에 문자열 만들기
const char *v = {"ABCDE", "BTS", "KK"};함수 포인터
커널 개발 시 “구조체 선택적 초기화” + “함수포인터” 사용
다음 두 가지를 맞춰야 사용 가능
1. return type
2. parameter type
return 없음 + parameter 없음
void abc() {
printf("ABC");
}
void def() {
printf("DEF");
}
int main() {
void (*p)(); // 함수 포인터 선언
p = &abc; // 가리킨다!
// p = abc; // 도 상관 없음
// 이제부터 *p 는 그냥 abc 함수이다
(*p)(); // abc 수행
p = &bbq; // 같은 return 타입, 매개변수 일치하는 함수
(*p)(); // def 수행
}return 있음 + parameter 있음
int sum(int a, int b) {
return a + b;
}
int sub(int a, int b) {
return a - b;
}
int main() {
int (*p)(int, int); // return type 고려
// parameter 고려
p = ∑
int ans = (*p)(10, 20);
printf("%d\n", ans); // 30
p = ⊂ // 같은 return 타입, 매개변수 일치하는 함수
ans = (*p)(10, 20);
printf("%d\n", ans); // -10
}함수 포인터 배열
void (*p)(); // 기본 함수 포인터
void (*p[5])(); // 함수 포인터 배열void abc() {
printf("ABC\n");
}
void def() {
printf("DEF\n");
}
int main() {
void (*p[4])() = {&abc, &def, &abc, &abc};
(*p[0])(); // abc 실행
(*p[1])(); // def 실행
(*p[2])(); // abc 실행
(*p[3])(); // abc 실행
}Volatile
컴파일러가 너무 똑똑해서 release 할 때 불필요한 절차를 생략하고 컴파일을 한다.
그럴 때 중간 값이 필요하다면, volatile로 컴파일러의 최적화를 방해한다.
다만, 너무 남발하면 오히려 코드 최적화를 할 수 없으므로 적재적소에 volatile 사용해야 한다.
int main() {
volatile int a = 10;
a = 20;
a = 30;
printf("%d", a);
}용도
임베디드에서 HW의 특정 주소 값을 이용해 제어하는 경우
device = 0xAABB;
while (device != 0xAABB) { }인터럽트 핸들러 사용할 때
uint8_t input_value[2] = {0x0, 0x0};
void interrupt port_read(void) {
input_value[0] = PORTA;
input_value[1] = PORTB;
}
int main() {
if (input_value[0] != input_value[1]) { }
}그 외
- 메모리 주소를 가진 OP 레지스터
- 인터럽트 핸들러가 값을 변경하는 전역 변수
- 등등 최적화에 의해 오류가 발생할 가능성이 있는 변수
비트 표기
표기 방법
- 2진법 : 0b
- 16진법 : 0x
| 2진수 | 10진수 | 16진수 |
|---|---|---|
| 0000 | 0 | 0 |
| 0001 | 1 | 1 |
| 0010 | 2 | 2 |
| 0011 | 3 | 3 |
| 0100 | 4 | 4 |
| 0101 | 5 | 5 |
| 0110 | 6 | 6 |
| 0111 | 7 | 7 |
| 1000 | 8 | 8 |
| 1001 | 9 | 9 |
| 1010 | 10 | A |
| 1011 | 11 | B |
| 1100 | 12 | C |
| 1101 | 13 | D |
| 1110 | 14 | E |
| 1111 | 15 | F |
비트 연산
| 연산자 | 설명 | 예시 |
|---|---|---|
& | - and - 값을 추출할 때 사용 - 값에 1을 적은 곳만 추출 | 1101 & 1110 = 1100 |
\| | - or - 2진수 덧셈 시 사용 - 둘 중 한 곳에 1이 있으면 추출 | 0111 | 1101 = 1101 |
<< | - Left Shift - 값을 왼쪽으로 밀어서 숫자 추가 - 제곱 계산 시 사용 | - 110 << 3 = 110000 - 1 << 3 = 2^3 |
>> | - Right Shift - 값을 오른쪽으로 밀어서 숫자 파괴 | 110111 >> 3 = 110 |
~ | - not - 비트 반전 | ~0xF0 = ~(1111 0000) = 0000 1111 |
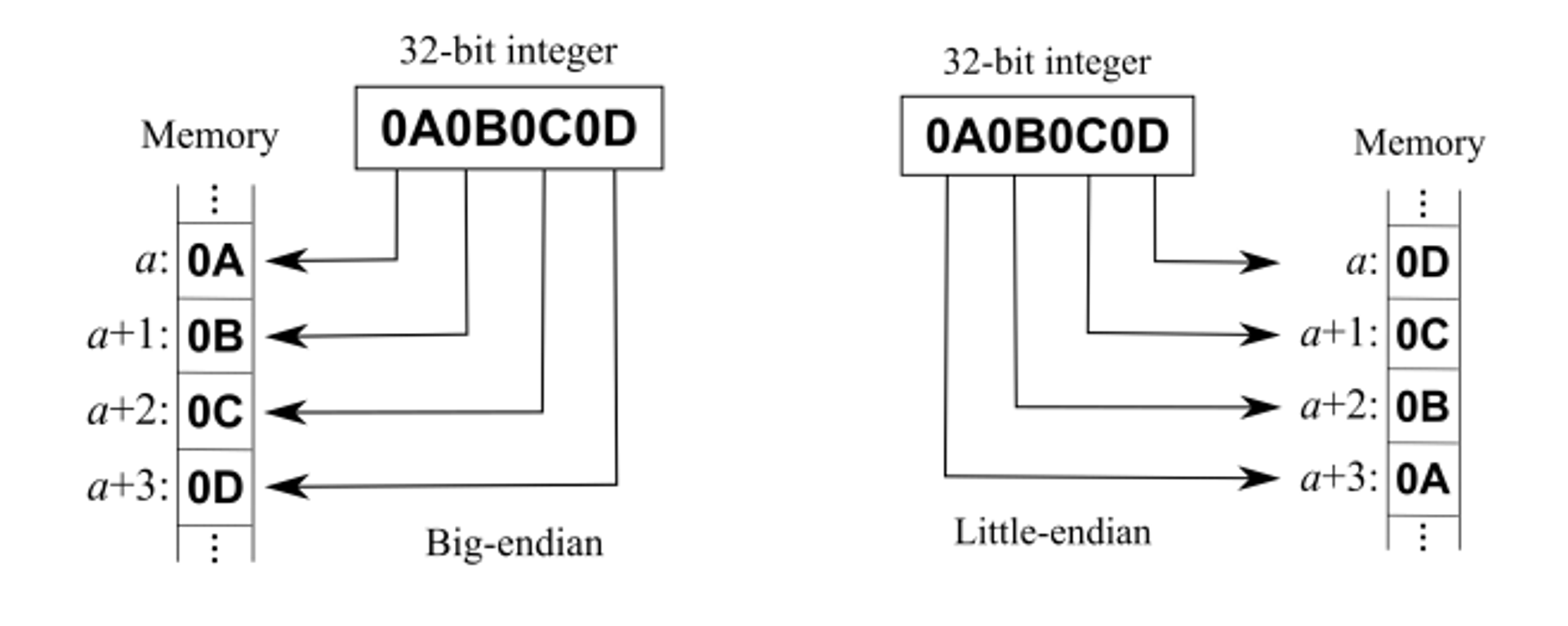
Endian
- CPU가 메모리에 값(바이트)을 저장할 때의 순서
- 바이트 단위로 어떤 순서로 기록할 것인가에 따라 두 가지 존재
| big endian | little endian |
|---|---|
| 메모리의 낮은 주소에 데이터의 MSB부터 저장 | 메모리의 낮은 주소에 데이터의 LSB부터 저장 |
| 사람이 읽기 편한 방식 | Embedded 방식 |
| 대소 비교, 디버깅 이점 | 캐스팅, 연산 이점 |
구조체와 공용체
구조체 (struct)
기본 타입들을 모아 새로운 타입을 만드는 문법
공용체 (union)
struct 와 문법은 비슷하나, 멤버끼리 값을 공유한다는 점에서 차이가 있음
쓰는 이유
바이트 단위의 파싱을 위해
하나의 멤버에 값을 넣으면, 나머지 멤버 변수는 각각의 표현법에 따라 그 값을 표현-저장
typedef union _ABC_ {
uint32_t a; // 0x1234abcd
uint8_t b[4]; // cd ab 34 12
uint16_t c[2]; // abcd 1234
} ACON;
int main() {
ACON data;
data.a = 0x1234ABCD;
}구조체와 공용체 활용
union UNI {
struct {
uint8_t a;
uint8_t b;
}d1;
struct {
uint8_t c;
uint8_t d;
}d2;
};
union UNI t = {0xAB, 0xCD};
// a := 0xab => 8비트 단위끼리 잘라서 받기 때문에 d1에 ab / cd 가 들어간다!
// b := 0xcd
// c := 0xab
// d := 0xcdunion UNI {
struct {
uint8_t a;
uint8_t b;
}d1;
uint16_t c;
};
union UNI t = {9, 10};
// a := 9
// b := A
// c := 0x0A09byte 단위 Data Parsing
// 보낼 데이터
uint8_t target[7] = {0xAB, 0x12, 0x13, 0xFA, 0xAA, 0xFF, 0xA0};
// 받을 영역
union _Data_ {
uint8_t receiveData[7];
struct {
uint8_t head;
uint8_t body[5];
uint8_t tail;
}msg;
} dm;
memcpy(&dm, target, 7);
printf("Head = %0X\\n", dm.msg.head);
printf("Body = ");
for (int i = 0; i < 5; i++) {
printf("%02X", dm.msg.body[i]);
}
printf("\\n");
printf("Tail = %02X\\n", dm.msg.tail);Padding
struct Node {
int a;
char b;
};int 4 byte, char 1 byte 이지만 sizeof(Node)는 8 byte 를 출력한다.
CPU 내부 성능을 올리기 위해 Padding 이라는 빈 공간을 두기 때문이다.
- HW 구조상 CPU는 메모리 값을 4 byte (32 bit) 단위로 읽을 수 있다.
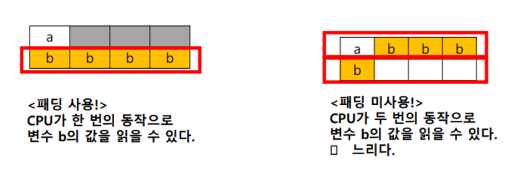
- CPU는 4 Byte 단위로 읽는다
- CPU가 메모리에서 변수 값들을 읽으려고 한다
- 4 Byte 단위로 읽다 보니, 내용이 잘려서 두 번 읽는 경우가 발생한다
- 그래서 4 Byte 단위로 정렬을 하기 위해 적절한 빈 공간을 둔다
- 이를 Padding 이라 한다
Padding 없애기
Padding이 붙은 만큼 메모리의 위치가 달라지기 때문에, 이를 제거해야 원활한 파싱이 가능해진다.
// Padding API
// pragma pack()
// 데이터버스 동작 단위 설정
# pragma pack(1) // 데이터버스를 1 바이트 단위로 동작하도록 설정비트 필드
특정 bit만 사용하는 변수
0번 bit 부터 순차적으로 값을 넣는다
- 비트 지칭 = [큰 bit 번호 : 작은 bit 번호]
struct Node {
uint8_t a : 2; // uint8_t 중에서 2비트만 사용 [1:0]
uint8_t b : 4; // uint8_t 중에서 4비트만 사용 [5:2]
uint8_t c : 1; // uint8_t 중에서 1비트만 사용 [6:6]
};메모리 구조
memory mapped I/O
= 총 4GB 메모리 address 공간에서 일부 사용(I/O 포함)
= CPU에서 I/O에 액세스 할 때, 하나의 메모리 공간에 I/O에 대한 메모리 주소를 구분하지 않고 한 공간에서 쓰는 것
Type
음수 표기 방법
2의 보수
- 컴퓨터가 음수를 저장하기 위해 사용하는 방법 중 하나
- 모든 사칙연산을 가산기(add)로 처리하기 위해 보수를 사용
- bit에 따라 값이 달라짐 (8bit, 16bit…)
- ex
- 7bit 111000의 2의 보수
- 000111 + 1 = 001000
- 4 bit 기준 7의 2의 보수?
- 0111 → (반전) 1000 → (보수) 1001
- 7bit 111000의 2의 보수
unsigned 로 변환 시
- char 변수에 저장된 -7을 unsigned char 변수로 복사하는 경우 2진수 값이 그대로 옮겨짐
- 최상위 비트가 의미하는 바가 다르기 때문
- char 값의 저장 범위 =
-128 ~ 127 - char 최대 저장 범위보다 큰 수가 저장되면,
Overflow - char 최소 저장 범위보다 작은 수가 저장되면,
Underflow
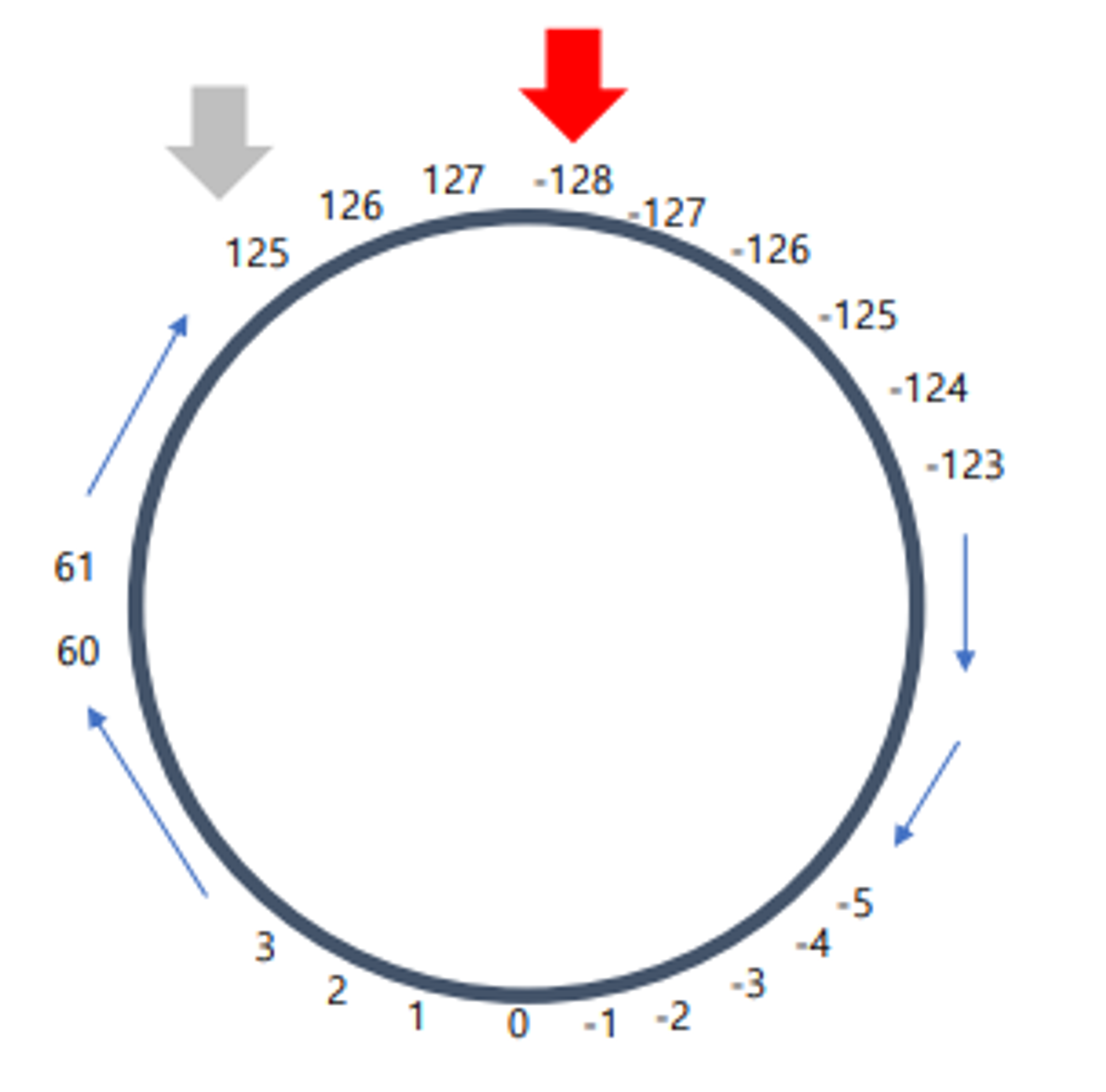
underflow 발생 시
- 최솟값인 -128에서 3을 빼면? (Underflow)
- 원형으로 수를 그려두고 세 칸 이동
overflow 발생 시
- 50에 3을 곱하면? (Overflow)
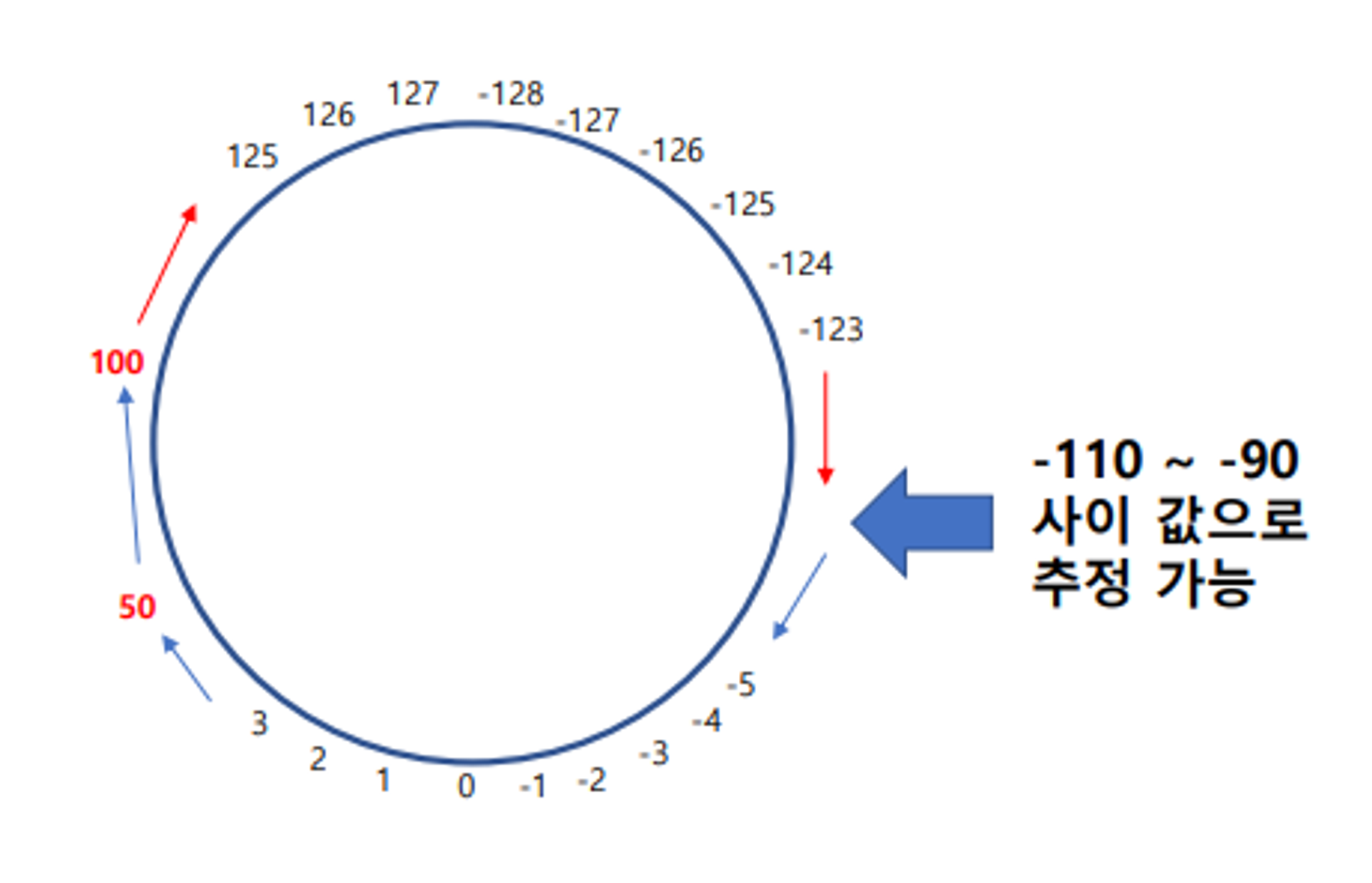
⇒ under / overflow 로 값이 깨지는 것이 아니다
- underflow 시, 다시 덧셈하면 숫자 복구 가능
- overflow 시, 다시 뺄셈하면 숫자 복구 가능
부동 소수점
floating point
- 실수를 저장할 때, 아주 정확한 값을 저장하지 않고
근사치를 저장 - 32 bit, 64 bit 변수 하나에 더 정밀도 높은 실수를 저장할 수 있음
- 프로그래밍 언어에서는
IEEE 754방식을 사용
고정 길이 변수
종류
stdint.h 헤더 include 후 사용 가능
| type | fixed width integer |
|---|---|
| char | int8_t |
| short | int16_t |
| int | int32_t |
| long long | int64_t |
| unsigned char | uint8_t |
| unsigned short | uint16_t |
| unsigned int | uint32_t |
| unsigned long long | uint64_t |
사용 이유
- 시스템마다 동일한 사이즈의 변수 사용을 위함
- unsigned 키워드가 너무 길고, 가독성이 떨어짐
