들어가기 전
- HAR(Human Activity Recognition)
- IMU 센서를 활용해서 사람의 행동을 인식하는 실험을 진행(19~48세)
- 폰에 있는 가속도/자이로 센서 사용(50Hz 주파수)
- 실험은 데이터를 수동으로 라벨링하기 위해 비디오로 기록됨
- 중력 및 신체 운동 성분을 갖는 센서 가속 신호는 버터 워스 저역 통과 필터를 사용하여 신체 가속 및 중력으로 분리
- 센서신호 → 특징추출 → 모델학습 → 행동추론
1. 결정나무
import pandas as pd
feauture_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
feauture_name = feauture_name_df.iloc[:, 1].values.tolist()
# X 데이터만
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
X_train.columns = feauture_name
X_test.columns = feauture_name
# y 데이터만
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])
X_train.shape, X_test.shape, y_train.shape, y_test.shape # ((7352, 561), (2947, 561), (7352, 1), (2947, 1))
# 결정나무
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy_score(y_test, pred) # 0.8096369189005769
# max_depth를 다양하게 하기 위해 GridSearchCV 이용
from sklearn.model_selection import GridSearchCV
parmas = {'max_depth':[6, 8, 10, 12, 16, 20, 24]}
grid_cv = GridSearchCV(dt_clf, param_grid=parmas, scoring='accuracy', cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)
grid_cv.best_score_ # 0.8543335321892183
grid_cv.best_params_ # {'max_depth': 8}
cv_result_df = pd.DataFrame(grid_cv.cv_results_) # max_depth별로 표로 성능을 정리
cv_result_df[['param_max_depth', 'mean_test_score', 'mean_train_score']] # 간격이 넓은 것 주의
# 베스트 모델 예측
best_df_clf = grid_cv.best_estimator_
pred1 = best_df_clf.predict(X_test)
accuracy_score(y_test, pred1) # 0.87343060739735322. 랜덤 포레스트
n_jobs: cpu코어 개수, -1(코어 모두 사용)
# 랜덤포레스트
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')
paramas = {'max_depth':[6,8,10],
'n_estimators':[50, 100, 200], # 나무 그루수
'min_samples_leaf': [8,12], # 끝에 나뭇잎에 오는 데이터 수
'min_samples_split':[8,12]} # 분할시킬 때 남는 데이터 수?
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1) # n_jobs cpu코어 개수
grid_cv = GridSearchCV(rf_clf, param_grid=paramas, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
rf_clf_best = grid_cv.best_estimator_ #test 데이터에 적용
rf_clf_best.fit(X_train, y_train)
pred1 = rf_clf_best.predict(X_test)
accuracy_score(y_test, pred1) # 0.9205972175093315중요 특성 확인
best_cols_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_cols_values, index=X_train.columns)
top20_cols = best_cols.sort_values(ascending=False)[:20]
top20_cols # 각 특성들의 중요도가 개별적으로 높지 않다
import seaborn as sns #주요 특성 관찰
plt.figure(figsize=(8,8))
sns.barplot(x=top20_cols, y=top20_cols.index)
plt.show()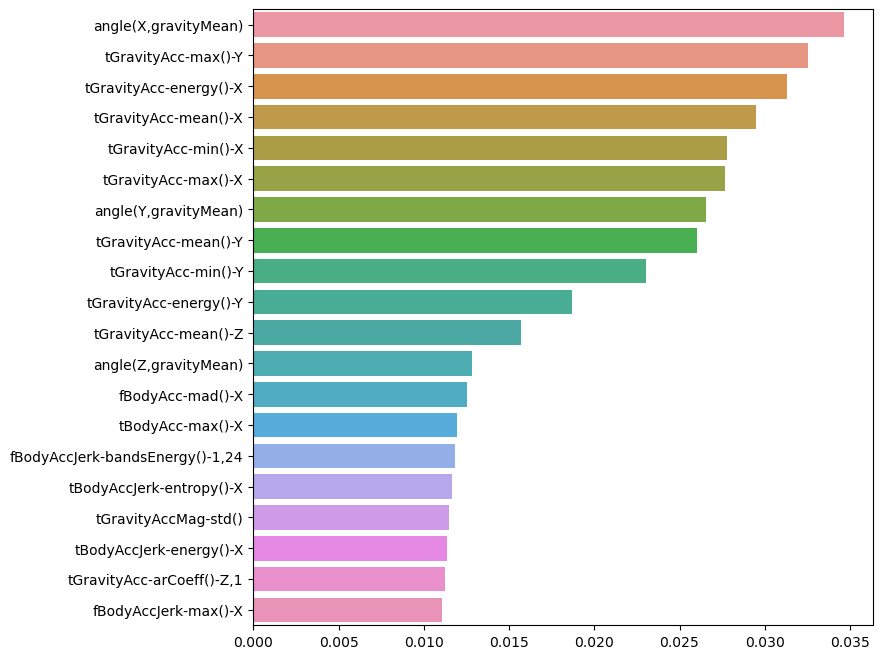
20개 특성만 가지고 다시 성능 확인
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train.values.reshape(-1,))
pred1_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred1_re) # 비록 acc는 포기하더라도 561개의 특성보다 20개의 특성만 보면 연산속도가 빠르다. 
데이터 사이언스 / just do it