머신러닝
1.Decision Tree
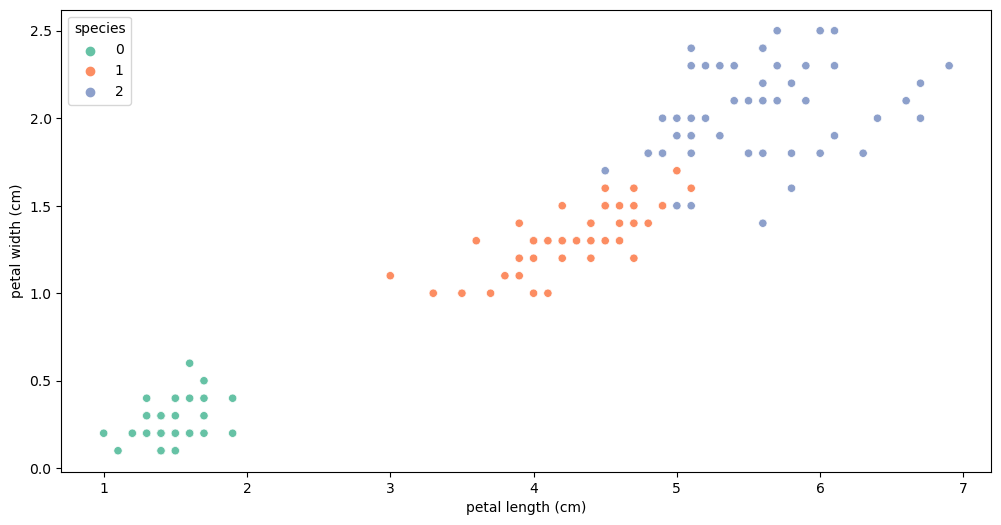
정의: 명시적인 프로그램에 의해서가 아니라, 주어진 데이터를 통해 규칙을 찾는 것장점: 특성을 파악하기 좋다.예시) iris 3종으로 나누기(setosa, versicolor, virginica)petal length > 2.5 기준: setosa vs versicol
2.Decision Tree (타이타닉 실습)

Reference1) 제로베이스 데이터스쿨 강의자료
3.preprocessing 전처리
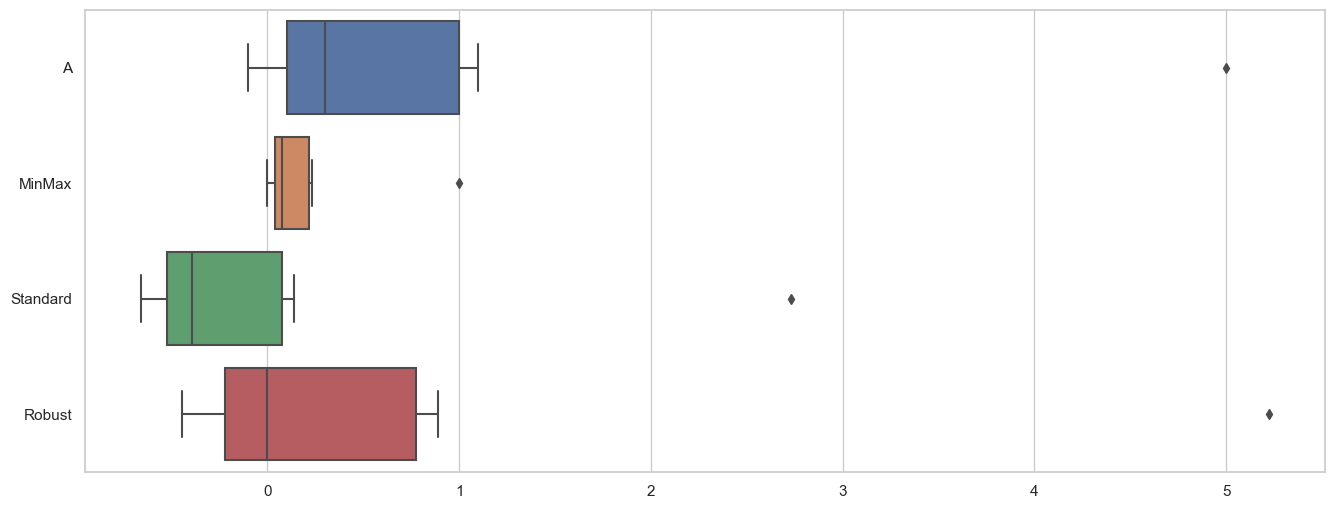
대상이 되는 문자로 된 데이터를 숫자 \* 카테고리컬한 데이터로 변환fit() → transform() = fit_transform()inverse_transform(): 역변환기본값 0 ~ 1 (min:0, max:1)outlier(이상치)에 영향을 받는다.$$x'=
4.Decision Tree(와인 데이터 실습)-split, scale, pipeline
Reference1) 데이터스쿨 강의자료
5.Decision Tree(와인 데이터 실습)-교차검증, GridSearchCV
과적합 감지나에게 주어진 데이터에 적용한 모델의 성능을 정확히 표현하기 위해서도 유용검증 validation이 끝난 후 test용 데이터로 최종 평가KFold는 index를 반환한다예시: 와인 맛 분류 모델 정확도 신뢰할만 한가?모델의 성능을 확보하기 위해 조절하는 설
6.모델 평가
실제 값과의 에러치를 가지고 계산평가 항목은 많다.분류모델은 그 결과를 속할 비율(확률)을 반환한다.비율에서 threshold를 0.5라고 하고 0, 1로 결과를 반영했다.전체 데이터 중 맞게 예측한 비율$$Accuracy = \\frac{TP + TN}{TP + TN
7.OLS
정답이 있는 데이터 학습종류: 분류 Classification, 회귀 Regression정답 레이블이 없는 데이터 학습종류: 군집, 차원 축소학습데이터셋 → 학습 알고리즘 → h(Hypothesis 가설 = 모델)어떤 feature를 기준으로, 연속된 값을 예측하는 문
8.Cost Function
선형 회귀: $h\_\\theta(x) = \\theta_0 + \\theta_1x$Cost function(error) 최소화 → 최적의 직선$$J(\\theta0, \\theta_1) = \\frac{1}{2m}\\sum^m{i=1}(h\_\\theta(x^{(i
9.LinearRegression(보스턴 데이터)

load_boston이 이제 지원이 안돼서 이 방식으로 진행해야 함!저소득층 인구가 낮을 수록, 방의 개수가 많을 수록 집 값이 높아진다?RMSE(Root Mean Squared Error)성능 나빠는 것으로 보아 빼지 않는 것이 옳은가? 이것을 결정하는 역할이 중요R
10.Logistic Regression

분류 문제는 0 또는 1로 예측해야 하나 Linear Regression을 그대로 적용하면 예측값 $h\_{\\theta}(x)$는 0보다 작거나 1보다 큰 값을 가질 수 있다.$h{\\theta}(x)$가 항상 0 ~ 1을 가지는 모델$$g(z) = \\frac{1}
11.Logistic Regression(와인 데이터)
Reference1) 제로베이스 데이터 스쿨 강의자료
12.Logistic Regression(PIMA 데이터)
PIMA 인디언 당뇨병 예측 상관관계 및 Outcome과 다른 특성과의 관계 확인 결측치 처리 null은 아니지만 0인값이 존재한다. 논리적 이상치 존재. 시간의 경우 연속된 값으로 앞의 값으로 대체하겠지만 여기서는 평균값으로 대체 → 다양한 방식과 검증이 존재 데
13.정밀도와 재현율의 트레이드오프
모델에게 큰 의미가 없어 정밀도를 강제로 조정하지는 않는다.weighted avg: 0.58\*(477/1300) + 0.84(823/1300) 클래스별 분포를 반영threshold 바꿔 보기 - BinarizerReference1) 제로베이스 데이터스쿨 강의자료
14.Ensemble 기법
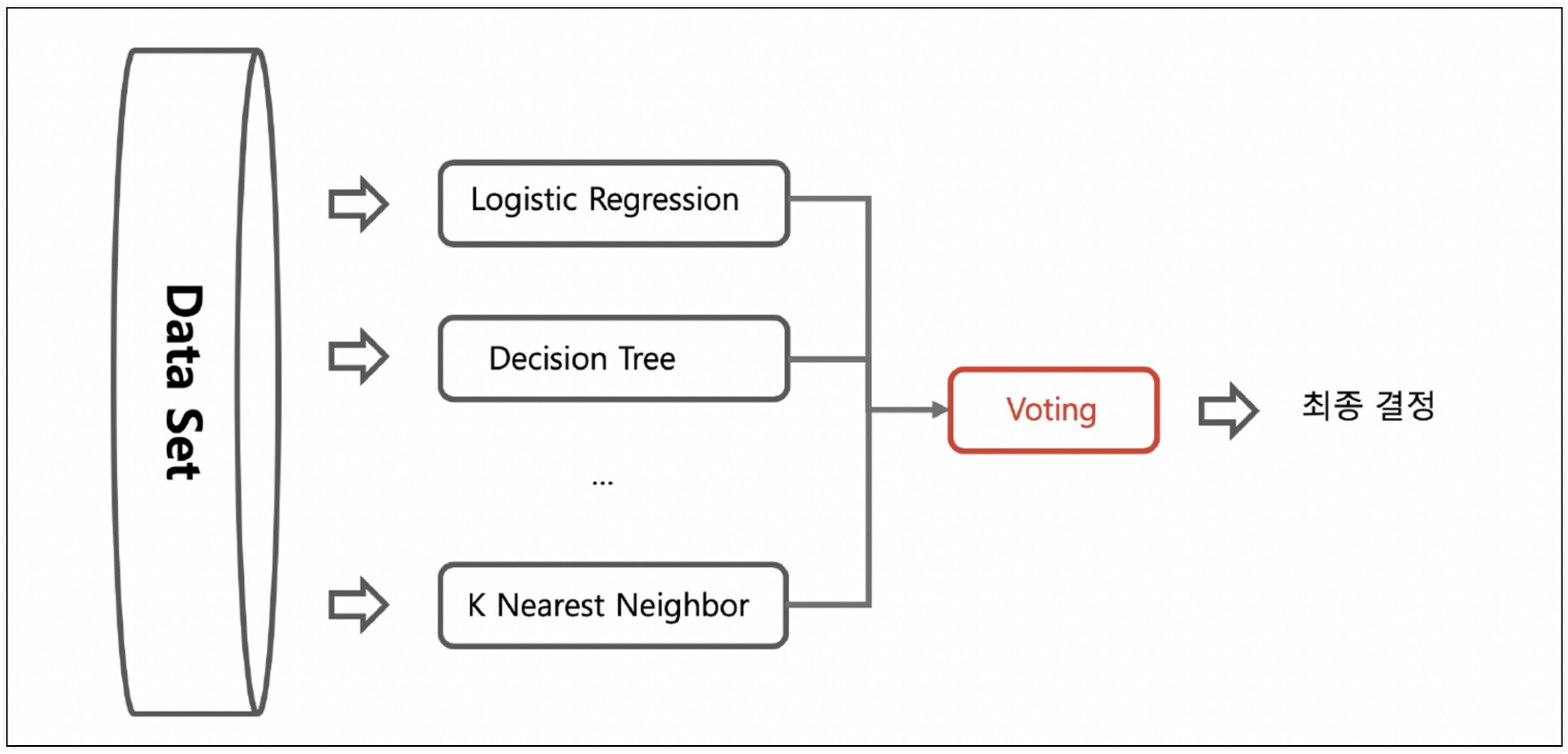
Ensemble: 여러 개의 분류기(약한 분류기)를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법이유:머신러닝이 세부적으로 학습을 할 수록 과적합(Overfitting) 현상이 발생하는데 이를 해결세부적으로 학습하지 않으면 예측 성능이 떨어지는 과소적합
15.Ensemble Random forest(HAR 데이터)
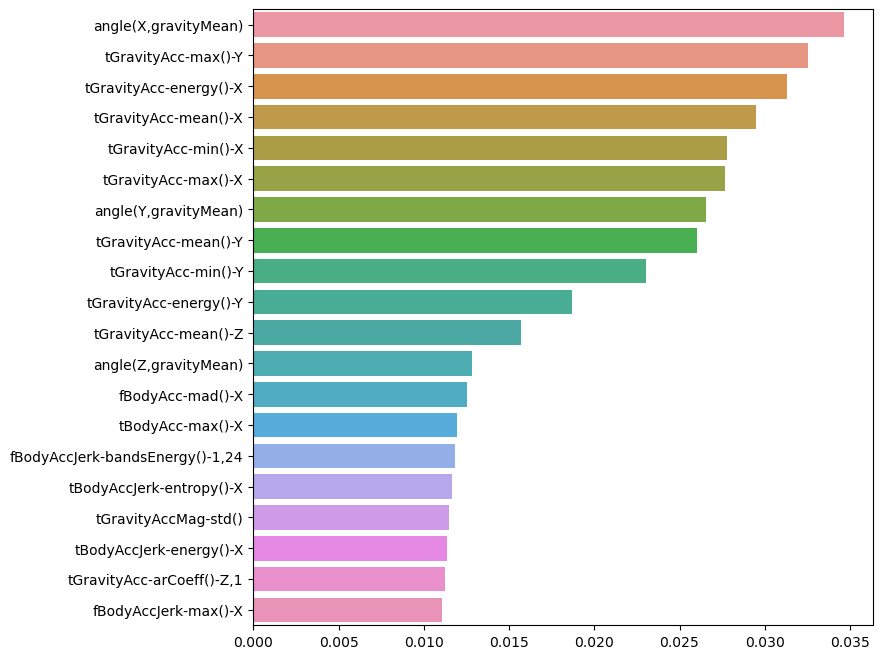
IMU 센서를 활용해서 사람의 행동을 인식하는 실험을 진행(19~48세)폰에 있는 가속도/자이로 센서 사용(50Hz 주파수)실험은 데이터를 수동으로 라벨링하기 위해 비디오로 기록됨중력 및 신체 운동 성분을 갖는 센서 가속 신호는 버터 워스 저역 통과 필터를 사용하여 신
16.Ensemble 비교(와인데이터)
이 상태에서 cross validation 을 한다면 X_train 만 대상이 된다절댓값으로 비교해야 한다.(alcohol, density 등 관계가 높아 보인다.)RandomForest가 유리해 보이기는 하다.
17.Ensemble GBM(HAR 데이터)
부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해서 오류를 개선해가는 방식GBM은 가중치를 업데이트할 때 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이계산 시간이
18.Ensemble XGBoost
XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나GBM 기반의 알고리즘인데, GBM의 느린 속도를 다양한 규제를 통해 해결병렬 학습이 가능하도록 설계됨XGBoost는 반복 수행 시마다 내부적으로 학습데이터와 검증데이터를 교차검증을 수행교차검증
19.Ensemble LightGBM
이번 강의에서 가장 힘들었던 점은 LightGBM 설치였습니다. 그래서 해결했던 방법을 공유하려고 합니다!보통 설치 방법 pip install lightgbm or conda install lightgbm or brew install lightgbm하지만 제 컴퓨터에서
20.k Nearest Neighber
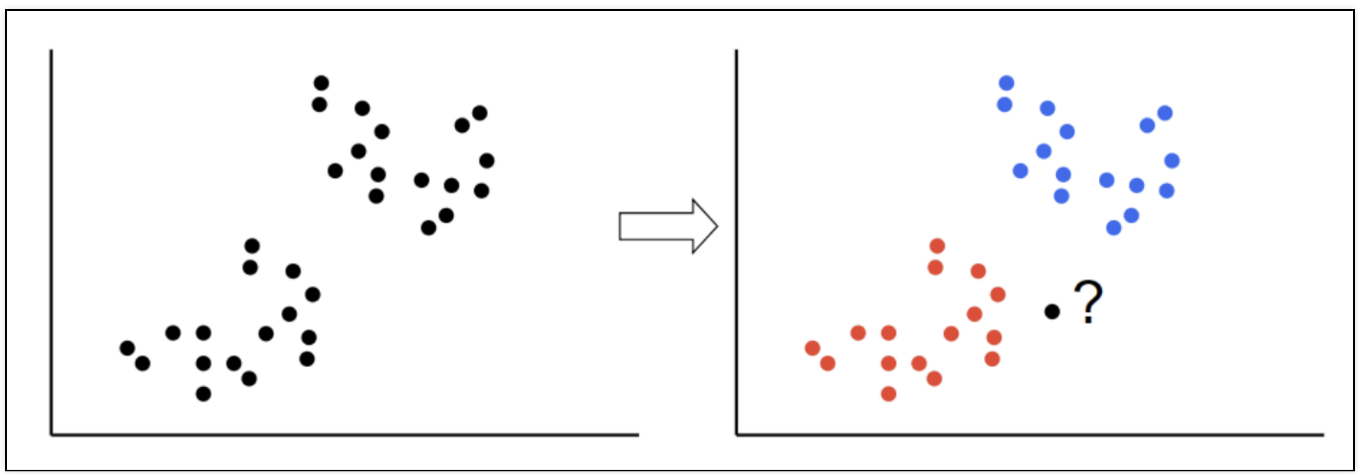
새로운 데이터가 있을 때 , 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제k 는 몇 번째 가까운 데이터까지 볼 것인가를 정하는 수치k값에 따라 결과값이 바뀔 수 있다.단위에 따라 바뀔 수도 있다. → 표준화 필요장단점:실시간 예측을 위한 학습이 필요치 않
21.Oversampling(신용카드 부정사용 검출)
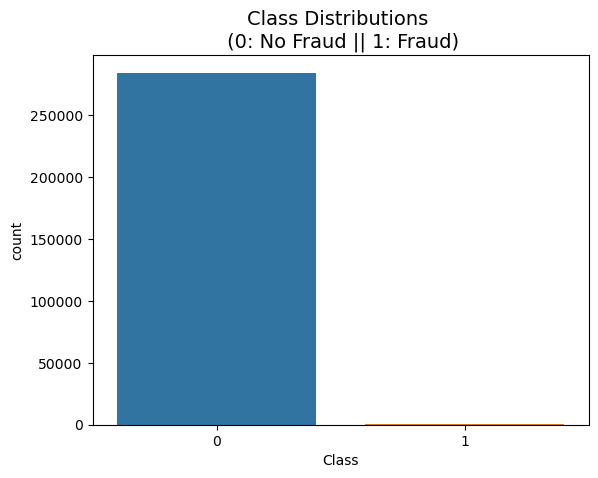
Kaggle: https://www.kaggle.com/MLG-ULB/CREDITCARDFRAUD신용카드 사기 검출 분류 실습용 데이터'class' 컬럼 → 사기 유무 의미'class' 컬럼의 불균형 극심 → 약 0.172%(사기 Fraud)'Amount':
22.자연어 처리(형태소 분석)
import는 \_\_init\_\_.py를 참고함많이 나오는 said 단어는 stopword 처리WordCloud 모듈은 자체적으로 단어를 추출해서 빈도수를 조사하고 정규화하는 기능을 가지고 있다.naive bayes classifier, 나이브 베이즈 분류기는 지도
23.자연어처리(워드클라우드)
많이 나오는 said 단어는 stopword 처리WordCloud 모듈은 자체적으로 단어를 추출해서 빈도수를 조사하고 정규화하는 기능을 가지고 있다.Rerference1) 제로베이스 데이터스쿨 강의자료
24.자연어처리(나이브베이즈)
naive bayes classifier, 나이브 베이즈 분류기는 지도학습
25.자연어처리(문장 유사도)
CountVectorizer: 문장을 벡터로 변환하는 함수거리를 구하는 것이므로 지도할 내용이 없다벡터로 만들기, 만들어진 벡터 사이의 거리를 계산하는 것이 중요한 문서에서 많이 등장한 단어에 가중치를 주어서 출력Rerference1) 제로베이스 데이터스쿨 강의자료
26.PCA 기초
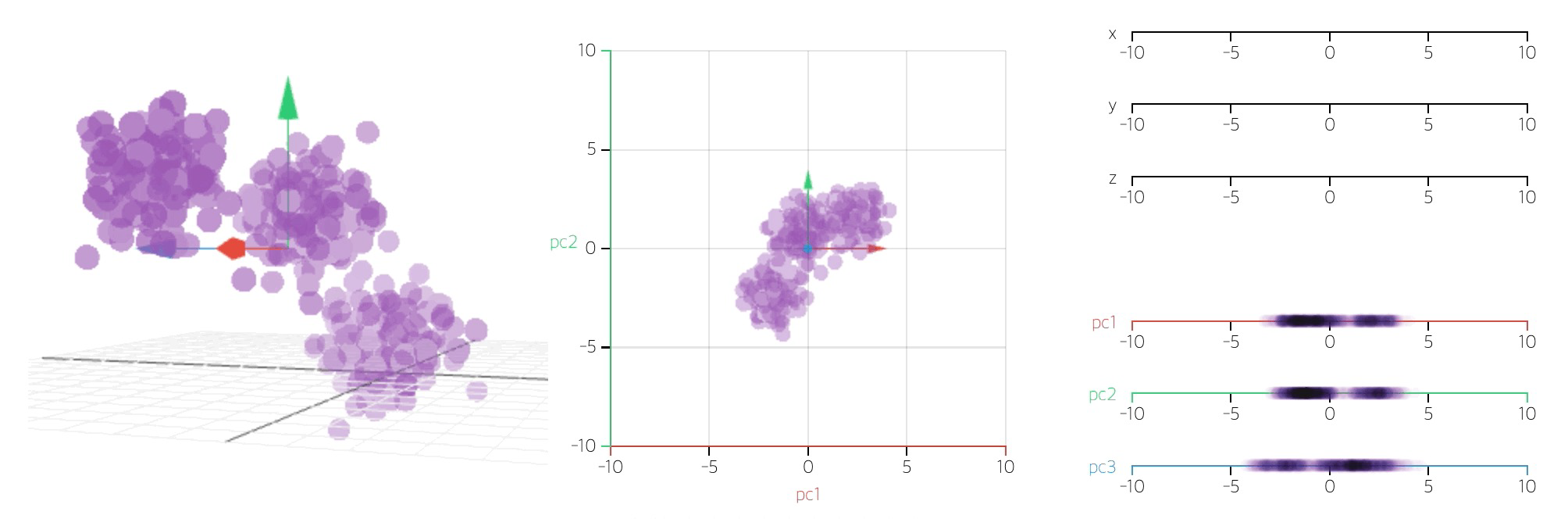
데이터 집합 내에 존재하는 각 데이터의 차이를 가장 잘 나타내주는 요소를 찾아내는 방법통계 데이터 분석(주성분 찾기), 데이터 압축(차원감소), 노이즈 제거 등 다양한 분야에서 사용주성분분석(Principal Component Analysis): 차원축소(dimensi
27.PCA(Olivetti 데이터)

특정 샘플만 선택(20번째 사람의 10개 사진)10장의 사진을 3장으로 표현face_p1만 표현Reference1) 제로베이스 데이터스쿨 강의자료
28.PCA(HAR 데이터)
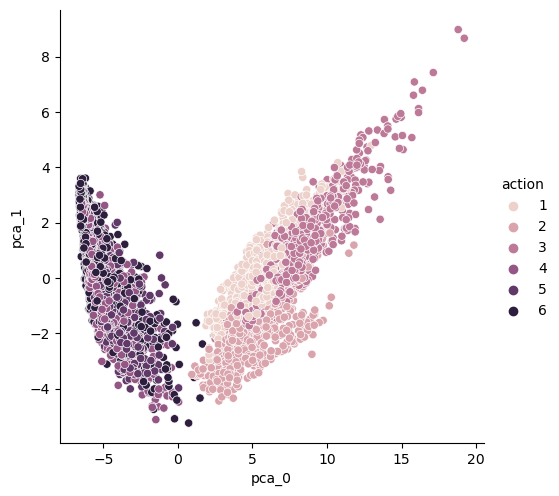
500개 특성을 두 개로 줄인 결과3개 sum of variance_ratio: 0.7158893015785952 → 10개 sum of variance_ratio: 0.8050386904374958(상승한다)주의: 여기서 561개 특성이 그대로인 X_test를 pca
29.PCA & kNN(MNIST 데이터)
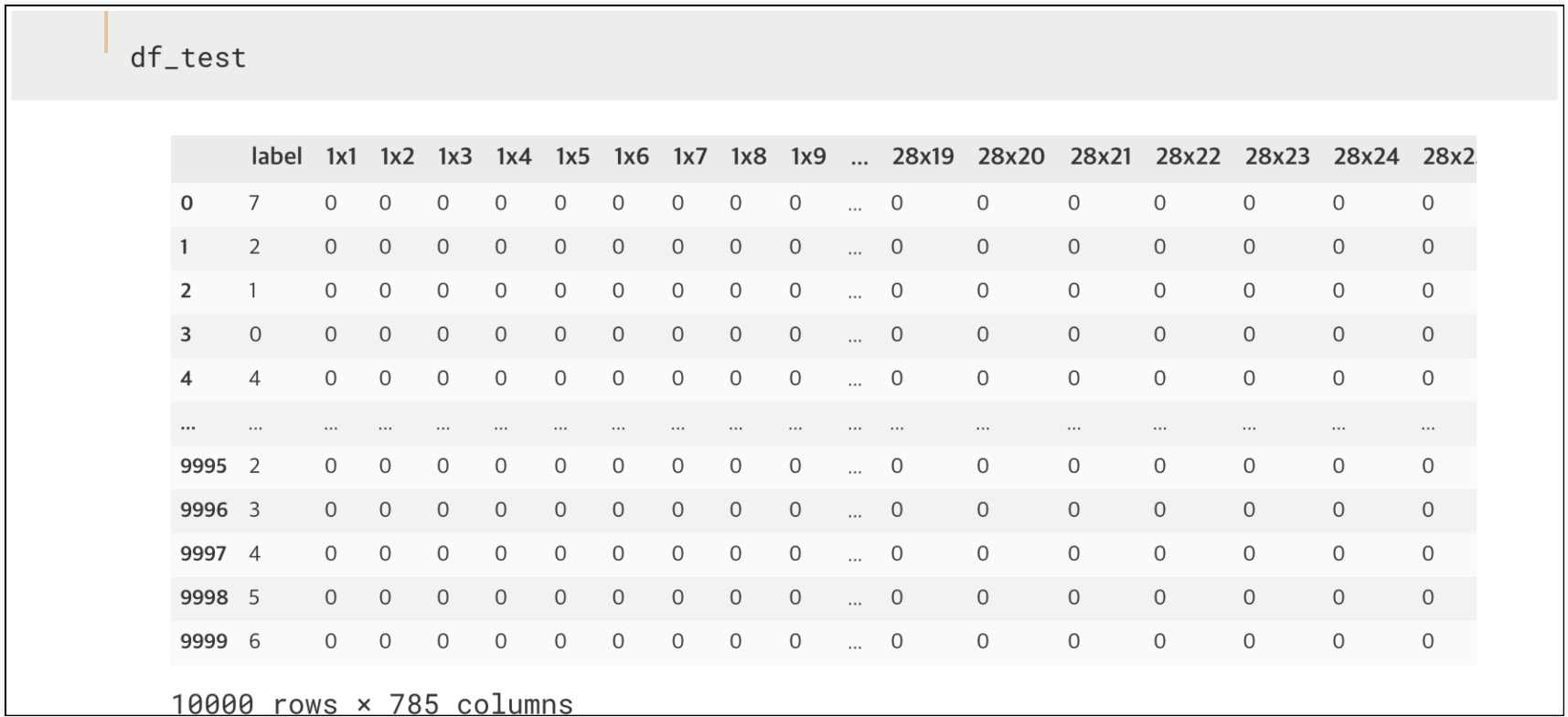
28 \* 28 픽셀의 0~9 사이의 숫자 이미지와 레이블로 구성된 세트60000개의 훈련용 세트와 10000개의 실험용 세트로 구성kaggle 데이터 활용: https://www.kaggle.com/oddrationale/mnist-in-csv대체적으로 비슷
30.PCA & kNN(Titanic 데이터)
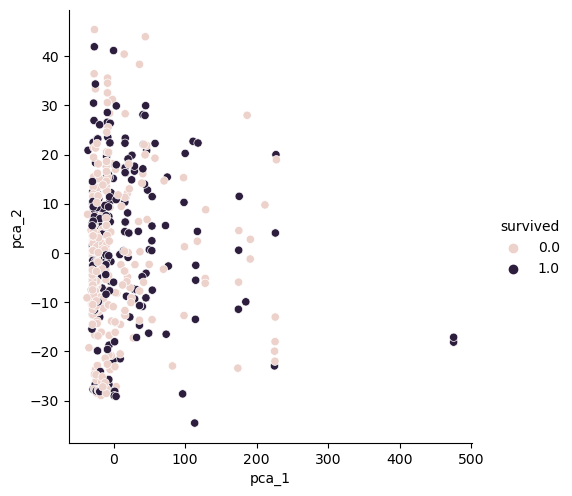
1) 이름 분리해서 title2) title로 귀족과 평민 등급을 구별3) gender, grade 컬럼 생성 → 머신러닝을 위해 sex, title 숫자로 표현4) 결측치 제거2개 축으로 변환구분 안됨3개 축으로 변환
31.네이버 API을 이용한 책 가격 회귀
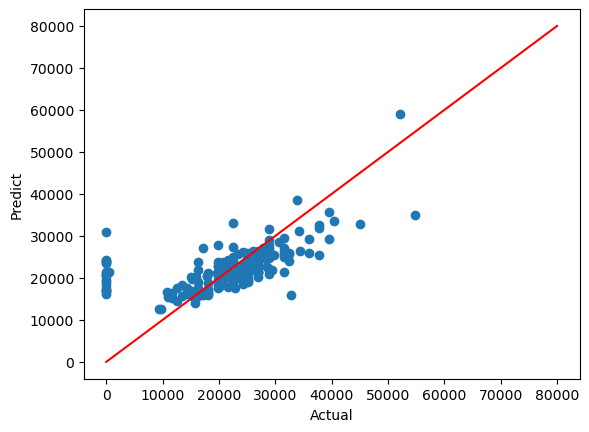
seaborn.regplot → 쪽수와 가격과의 상관관계 확인함seaborn.countplot → 출판사 편중도 확인Reference1) 제로베이스 데이터스쿨 강의자료
32.Clustering
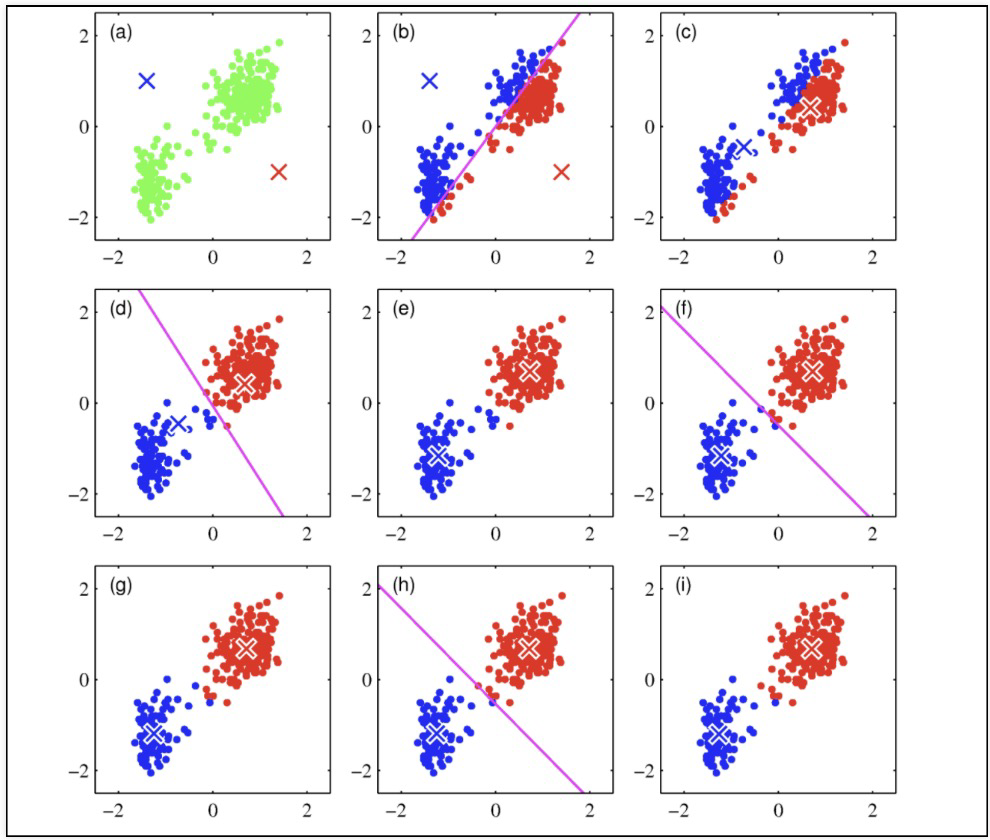
Clustering(군집) : 비슷한 샘플을 모음Outier detection(이상치 탐지) : 정상 데이터가 어떻게 보이는지 학습, 비정상 샘플을 감지밀도 추정 : 데이터셋의 확률 밀도 함수 Probability Density Function PDF를 추정. 이상치
33.KMeans(iris 데이터)
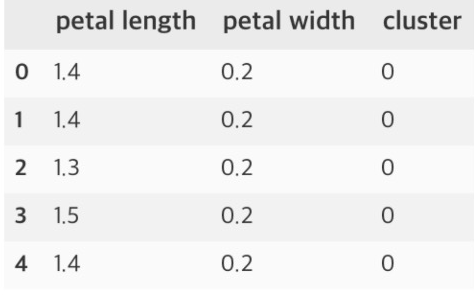
특성 두 개만 이용Reference1) 제로베이스 데이터스쿨 강의자료
34.KMeans(make_blobs 데이터)
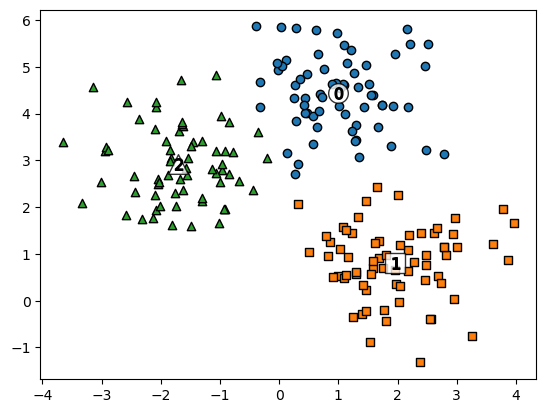
Reference1) 제로베이스 데이터스쿨 강의자료2) https://hleecaster.com/k-means-clustering-concept/
35.군집 평가, yellowbrick
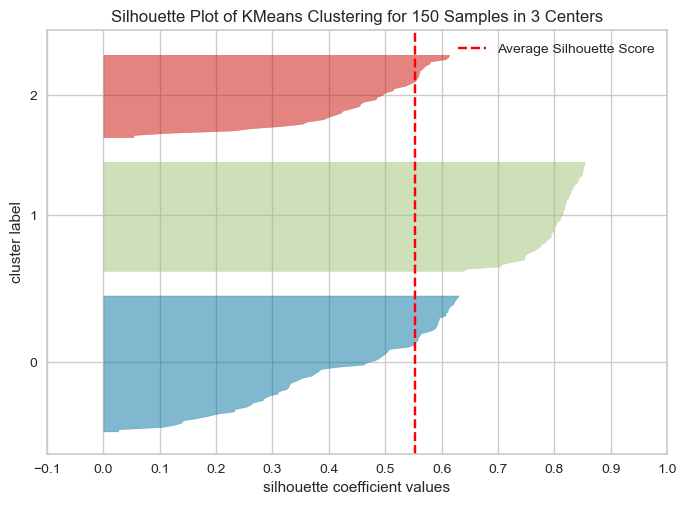
분류기는 평가 기준(정답)을 가지고 있지만, 군집은 그렇지 않다.군집 결과를 평가하기 위해 실루엣 분석을 많이 활용한다.실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 나타냄다른 군집과는 거리가 떨어져 있고, 동일 군집간의 데이터는 서로 가깝게 잘
36.군집(이미지 색상 분할)

이미지 분할 image segmentation은 이미지를 여러 개로 분할하는 것시맨틱 분할 semantic segmentation은 동일 종류의 물체에 속한 픽셀을 같은 세그먼트로 할당시맨틱 분할에서 최고의 성능을 내려면 CNN(Convolutional Neural N
37.추천시스템
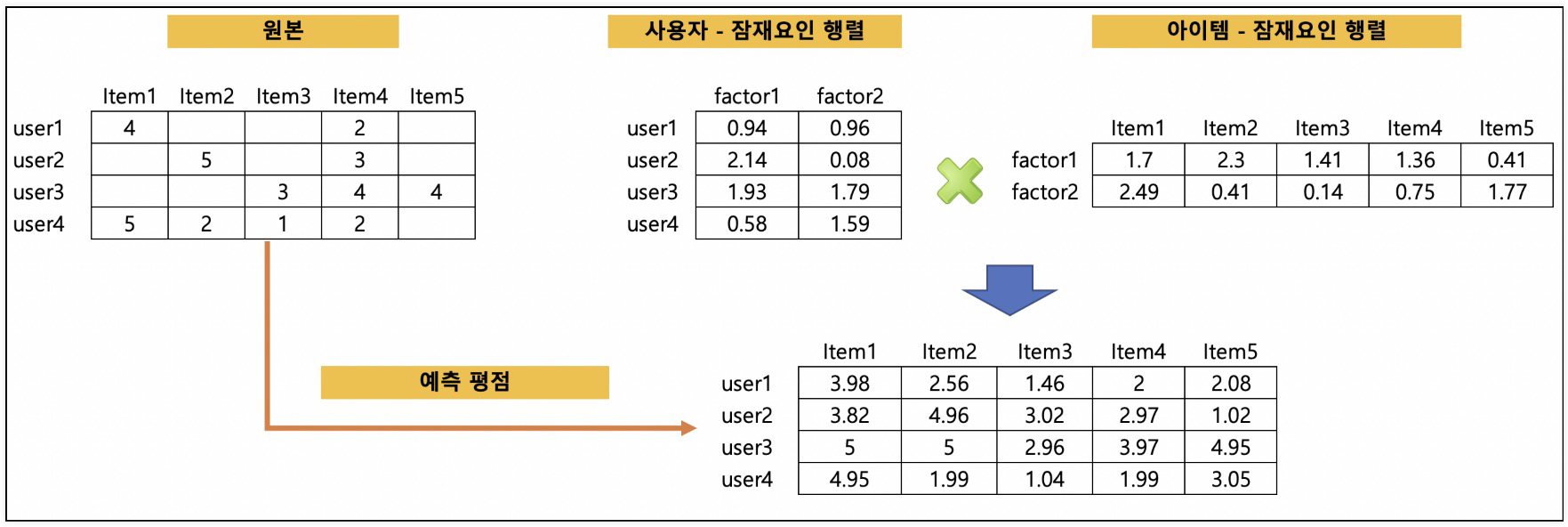
사용자가 특정한 아이템을 선호하는 경우, 그 아이템과 비슷한 아이템을 추천하는 방식축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가사용자기반 : 당신과 비슷한 고객들이 다음 상품도 구매했음아이템기반 : 이 상품을 선택한 다른 고객들은
38.아이템 기반 최근접 이웃 협업 필터링
캐글: https://grouplens.org/datasets/movielens/latest/영화의 평점을 매긴 사용자와 영화 평점 행렬 등의 데이터small 데이터 사용movie.csv: movieId, title, genrerating.csv: usrId,
39.책 추천 실습
캐글: https://www.kaggle.com/zygmunt/goodbooks-10ktag_id를 기준으로 book_tags와 tags merge1) Tfidf1) 코사인 유사도2) 책 제목으로 인덱스 구하기3) 유사도 값 호출4) 유사도 결과를 인덱스를 가
40.콘텐츠 기반 필터링 실습
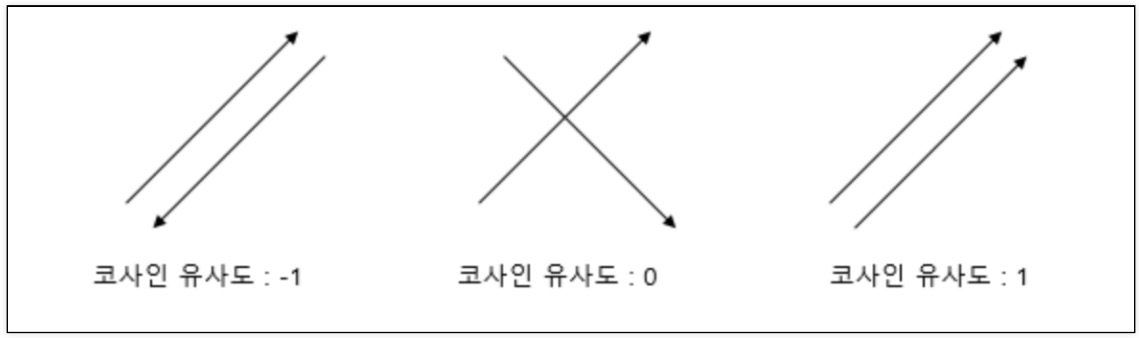
TMDB5000 영화 데이터 세트캐글: https://www.kaggle.com/tmdb/tmdb-movie-metadata문장의 유사도 측정을 하는 방법 중 하나인 코사인 유사도 측정을 수행confusion_matrix와 비슷하게 해석평점과 평점을 매긴 횟수