1. 데이터 정리
- 특성 두 개만 이용
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
cols = [each[:-5] for each in iris.feature_names] # cm 자르기
iris_df = pd.DataFrame(data=iris.data, columns=cols)
feature = iris_df[['petal length', 'petal width']] # 두 개의 특성2. 군집화
n_clusters: 군집화 할 개수, 즉 군집 중심점의 개수init: 초기 군집 중심점의 좌표를 설정하는 방식을 결정max_iter: 최대 반복 횟수, 모든 데이터의 중심점 이동이 없으면 종료model.labels_: 군집화라서 지도학습의 라벨과 다르다model.cluster_centers_: 군집 중심값
model = KMeans(n_clusters=3)
model.fit(feature)
# 데이터 정리
predict = pd.DataFrame(model.predict(feature), columns=['cluster'])
feature = pd.concat([feature, predict], axis=1)
feature.head()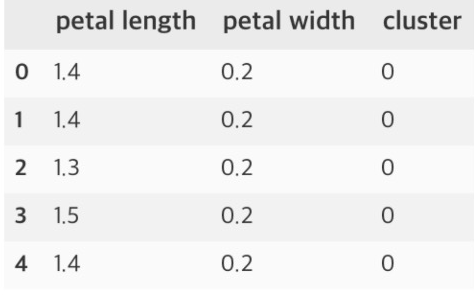
3. 그래프
centers = pd.DataFrame(model.cluster_centers_, columns=['petal length', 'petal width'])
center_x = centers['petal length']
center_y = centers['petal width']
plt.figure(figsize=(12, 8))
plt.scatter(feature['petal length'], feature['petal width'], c=feature['cluster'], alpha=0.5)
plt.scatter(center_x, center_y, s=50, marker='D', c='r')
plt.show()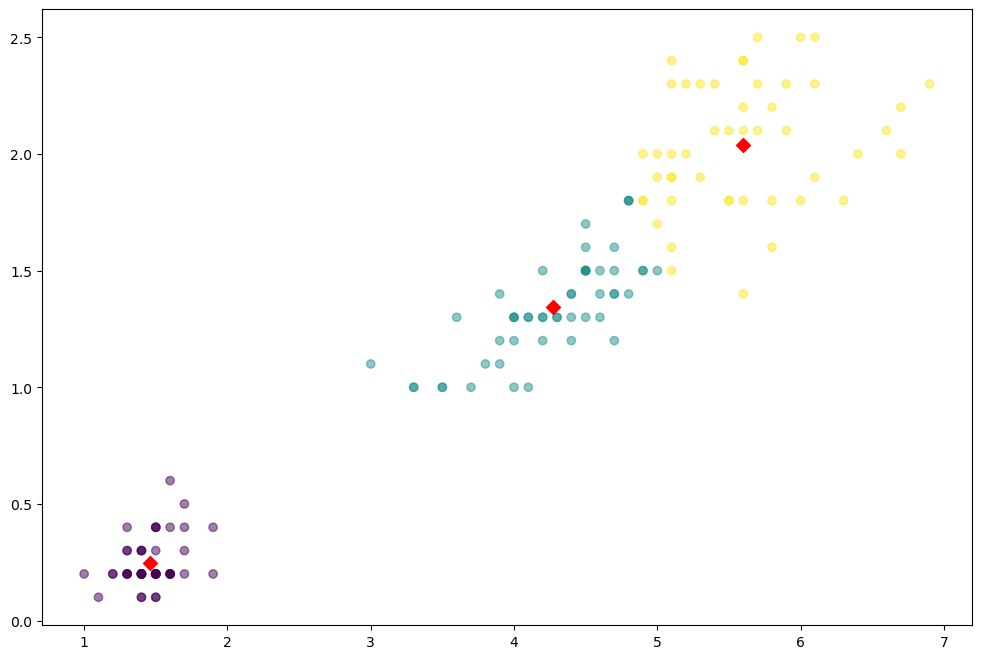
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it