1. PCA란?
- 데이터 집합 내에 존재하는 각 데이터의 차이를 가장 잘 나타내주는 요소를 찾아내는 방법
- 통계 데이터 분석(주성분 찾기), 데이터 압축(차원감소), 노이즈 제거 등 다양한 분야에서 사용
- 주성분분석(Principal Component Analysis): 차원축소(dimensionality reduction)와 변수추출(feature extraction) 기법으로 널리 쓰이고 있는
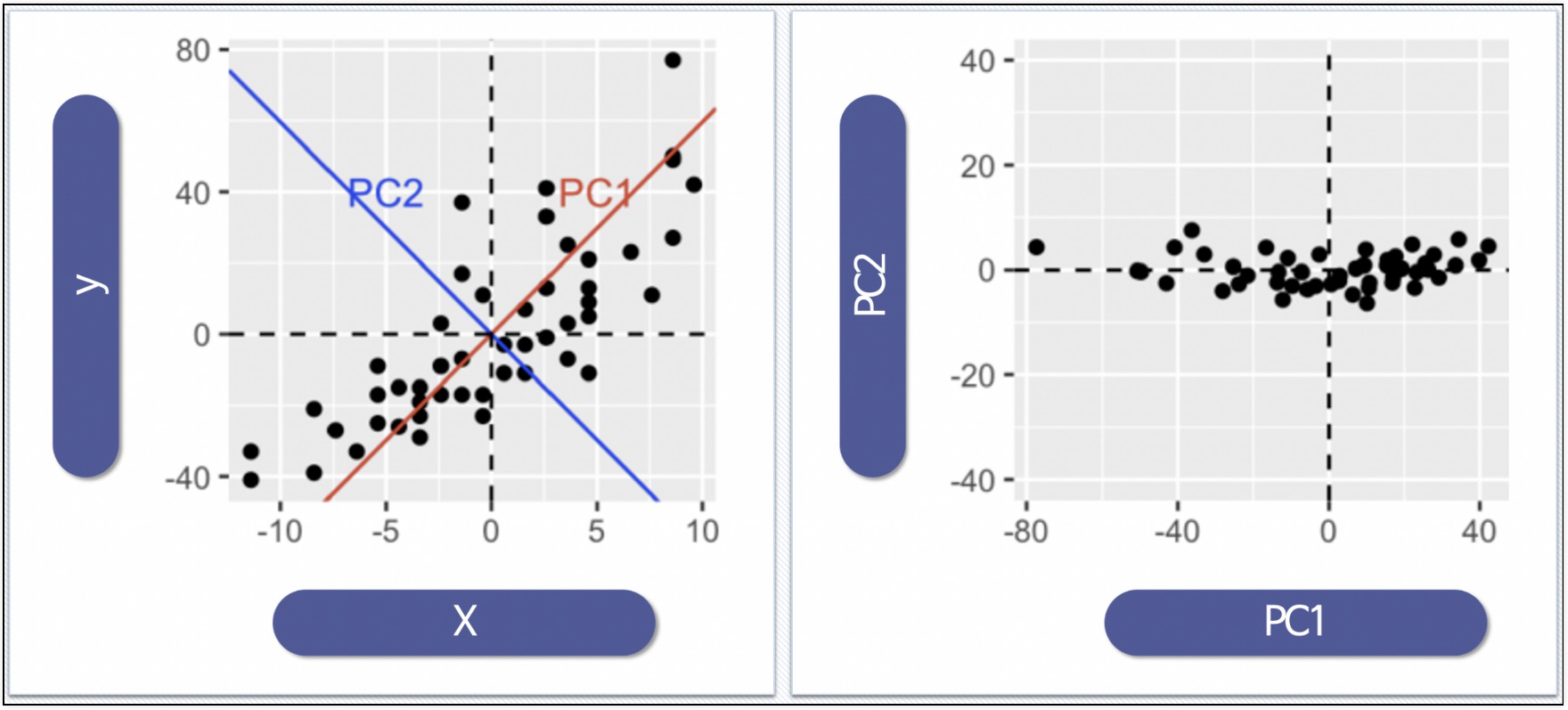
- PCA: 데이터의 분산(variance)을 최대한 보존하면서 서로 직교하는 새 기저(축)를 찾아, 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법
- 변수추출(Feature Extraction): 기존 변수를 조합해 새로운 변수를 만드는 기법 (변수선택(Feature Selection)과 구분할 것)
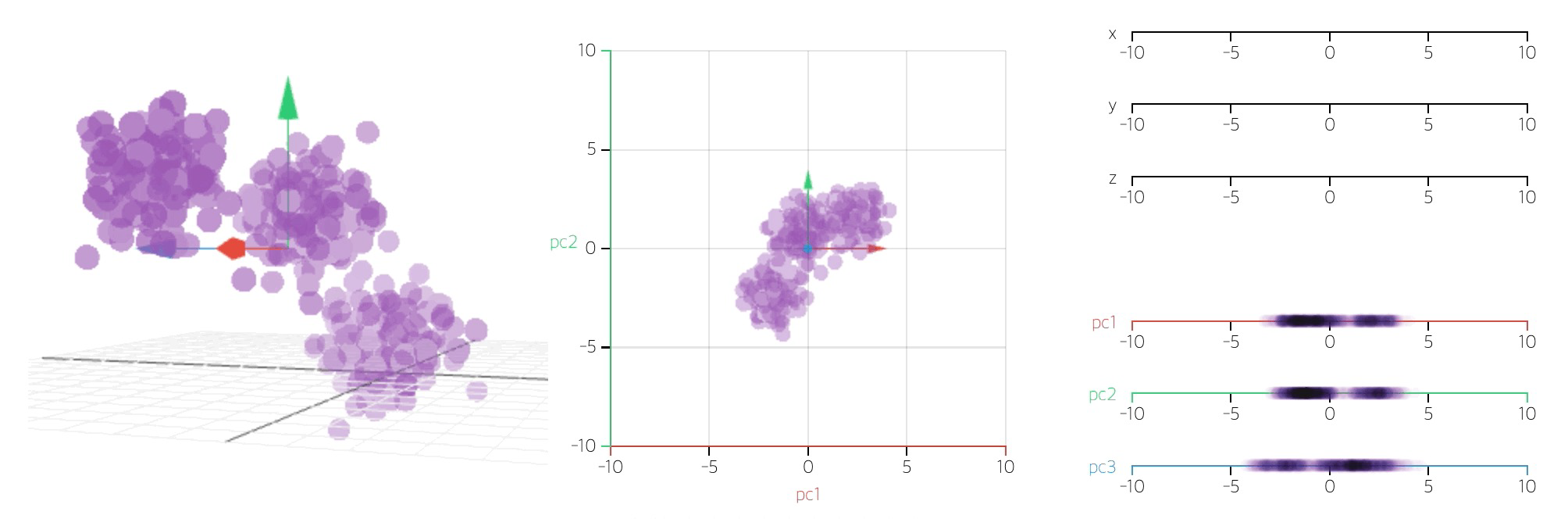
- 데이터의 주성분을 찾은 다음 주축을 변경하는 것도 가능
2. iris PCA
- 특성 4개를 한 번에 확인하기는 어렵다
특성 2개
1) scale
2) pca(n_components=2) : 주성분이 2개
3) 결과 데이터 프레임화 & 그래프
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_pd['species'] = iris.target
# scale
from sklearn.preprocessing import StandardScaler
iris_ss = StandardScaler().fit_transform(iris.data)
iris_ss[:3]
# pca 결과를 return하는 함수
from sklearn.decomposition import PCA
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca
iris_pca, pca = get_pca_data(iris_ss, 2)
# pca 결과를 pandas로 정리하는 함수
def get_pd_from_pca(pca_data, cols=['pca_components_1', 'pca_components_2']):
return pd.DataFrame(pca_data, columns=cols)
iris_pd_pca = get_pd_from_pca(iris_pca)
iris_pd_pca['species'] = iris.target
# 그래프
sns.pairplot(iris_pd_pca, hue='species', height=5,
x_vars=['pca_components_1'], y_vars=['pca_components_2'])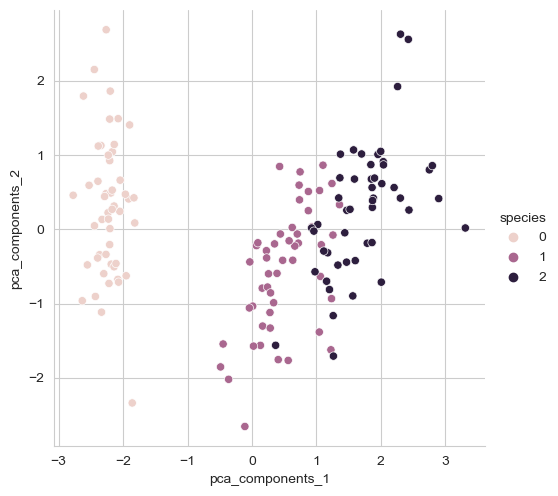
특성 4개 & 2개 randomforest 비교
- 성능은 떨어지나 짧아지는 시간도 고려해야 한다
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
def rf_scores(X, y, cv=5):
rf = RandomForestClassifier(random_state=13, n_estimators=100)
scores_rf = cross_val_score(rf, X, y, scoring='accuracy', cv=cv)
print('Score: ', np.mean(scores_rf))
# 4개
rf_scores(iris_ss, iris.target) # Score: 0.96
# 2개
pca_X = iris_pd_pca[['pca_components_1', 'pca_components_2']]
rf_scores(pca_X, iris.target) # Score: 0.90666666666666663. wine PCA
explainedvariance_ratio
- 각각의 주성분 벡터가 이루는 축에 투영(projection)한 결과의 분산의 비율
def print_variance_ratio_(pca):
print('variance_ratio: ', pca.explained_variance_ratio_)
print('sum of variance_ratio: ', np.sum(pca.explained_variance_ratio_))특성 2개 wine
1) 와인 색상 분류 (red/white)
2) StandardScale
3) 주성분 2개
→ PCA.fit() : 주성분 찾기
→ PCA.trasform() : 새로운 주성분으로 데이터 변환
→ PCA.inverse_trasform() : 원본값으로 복원
4) randomforest
5) pairplot
# wine
wine = pd.read_csv(wine_url, sep=',', index_col=0)
wine_y = wine['color']
wine_X = wine.drop(['color'], axis=1)
wine_ss = StandardScaler().fit_transform(wine_X)
pca_wine, pca = get_pca_data(wine_ss, n_components=2)
print_variance_ratio_(pca)
'''
variance_ratio: [0.25346226 0.22082117]
sum of variance_ratio: 0.47428342743236196
'''
pca_wine_pd = get_pd_from_pca(pca_wine)
pca_wine_pd['color'] = wine_y.values
sns.pairplot(pca_wine_pd, hue='color', height=5,
x_vars=['pca_components_1'], y_vars=['pca_components_2']);
# standardscale 모델 성능
rf_scores(wine_ss, wine_y) # Score: 0.9935352638124
# standardscale 모델 성능
pca_X = pca_wine_pd[['pca_components_1', 'pca_components_2']]
rf_scores(pca_X, wine_y) # Score: 0.981067803635933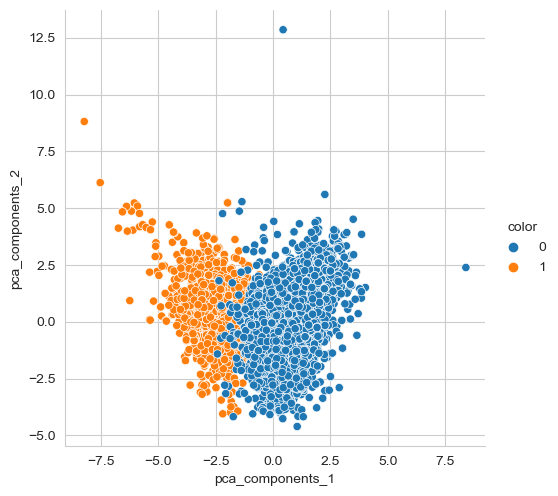
plotly.express(scatter_3d)으로 특성 3개 표현하기
pca_wine, pca = get_pca_data(wine_ss, n_components=3)
print_variance_ratio_(pca)
cols = ['pca_1', 'pca_2', 'pca_3']
pca_wine_pd = get_pd_from_pca(pca_wine, cols=cols)
pca_X = pca_wine_pd[cols]
rf_scores(pca_X, wine_y) # 주 성분 3개로 표현해달라고 했더니, 98% 이상을 표현
'''
variance_ratio: [0.25346226 0.22082117 0.13679223]
sum of variance_ratio: 0.6110756621838707
Score: 0.9832236631728548
'''
pca_wine_plot = pca_X
pca_wine_plot['color'] = wine_y.values
import plotly.express as px
fig = px.scatter_3d(pca_wine_plot, x='pca_1', y='pca_2', z='pca_3',
color='color', symbol='color', opacity=0.4)
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()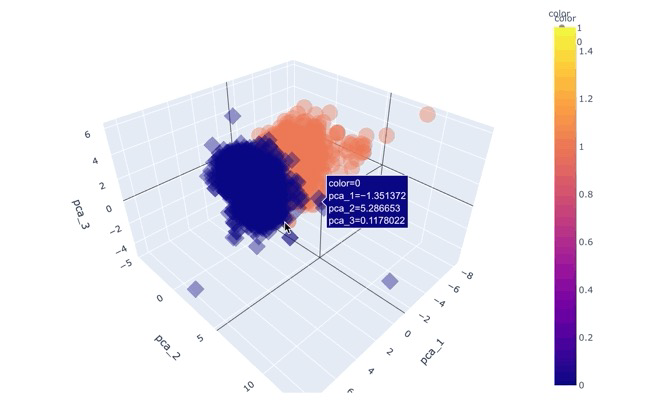
Reference
1) 제로베이스 데이터스쿨 강의자료
2) 차원축소-PCA, 주성분분석

데이터 사이언스 / just do it