1. pytorch 기초
1) pytorch 알아보기
import torch
x = 3.5
y = x*x + 2
print(x, y)
# 토치 표현
x = torch.tensor(3.5)
print(x)
# 자동으로 기울기를 계산하기 위한 준비 requires_grad-gradient
x = torch.tensor(3.5, requires_grad=True)
print(x)
y = (x-1) * (x-2) * (x-3)
print(y)
# x = 3.5 지점 기울기를 계산
y.backward()
x.grad # 기울기
'''
3.5 14.25
tensor(3.5000)
tensor(3.5000, requires_grad=True)
tensor(1.8750, grad_fn=<MulBackward0>)
tensor(5.7500)
'''2) Chain rule
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(1.0, requires_grad=True)
x = 2*a + 3*b
y = 5*a*a + 3*b*b*b
z = 2*x + 3*y
# dz/da
# work out gradients
z.backward()
# what is gradient at a = 2.0
a.grad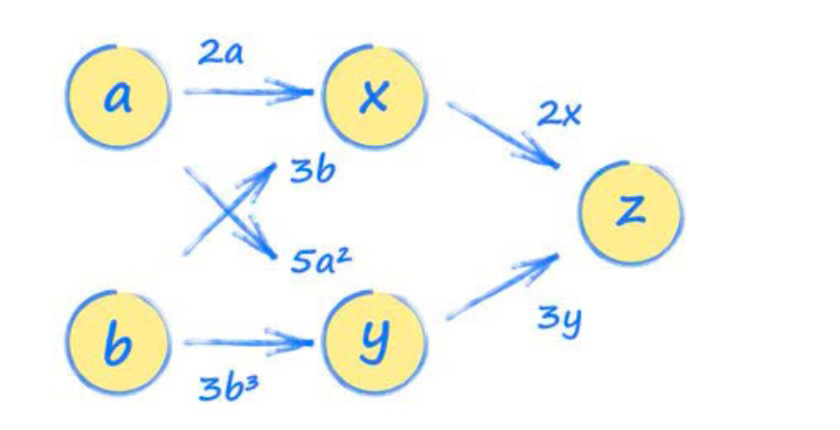
2. 보스턴 집값 회귀
데이터 읽기
load_boston으로는 이제 안되므로 url로 불러와야 오고 정리해야 한다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
boston = pd.DataFrame(data, columns=['CRIM','ZN','INDUS','CHAS', 'NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT'])
boston['TARGET'] = target
boston.head()데이터 분리
# 모듈 import
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 학습에 필요한 특성을 선택
cols = ['TARGET', 'INDUS', 'RM', 'LSTAT', 'NOX', 'DIS']
data = torch.from_numpy(boston[cols].values).float()
data # 생긴 모양은 numpy이지만 tensor이다
# 특성과 라벨로 분리
y = data[:, :1]
x = data[:, 1:]
print(x.shape, y.shape) # torch.Size([506, 5]) torch.Size([506, 1])모델 수립
torch.nn.Linear(in_features: int, out_features: int, bias: bool = True, device: Any | None = None, dtype: Any | None = None)in_features- size of each input sampleout_features- size of each output samplebias- False: an additive bias 를 학습 x, 기본 True
# 하이퍼파라미터
n_epochs = 2000
learning_rate = 1e-3 # learning_rate 띄어쓰기하면 인식 안됨!
print_interval = 100
# model
model = nn.Linear(x.size(-1), y.size(-1))
optimizer = optim.SGD(model.parameters(), lr=learning_rate)학습
optimizer.zero_grad(): tensor의 gradient가 연산될 때, gradient값이 축적되는걸 막아주기 위해서
for i in range(n_epochs):
y_hat = model(x)
loss = F.mse_loss(y_hat, y) # loss 계산
optimizer.zero_grad()
loss.backward()
optimizer.step() # 한 스텝 진행
if (i+1) % print_interval == 0: # 1print_interval마다 print
print('Epoch %d: loss=%.4e ' % (i + 1, loss))학습 결과 정리
df = pd.DataFrame(torch.cat([y, y_hat], dim=1).detach_().numpy(), columns=['y', 'y_hat'])
sns.pairplot(df, height=5)
plt.show()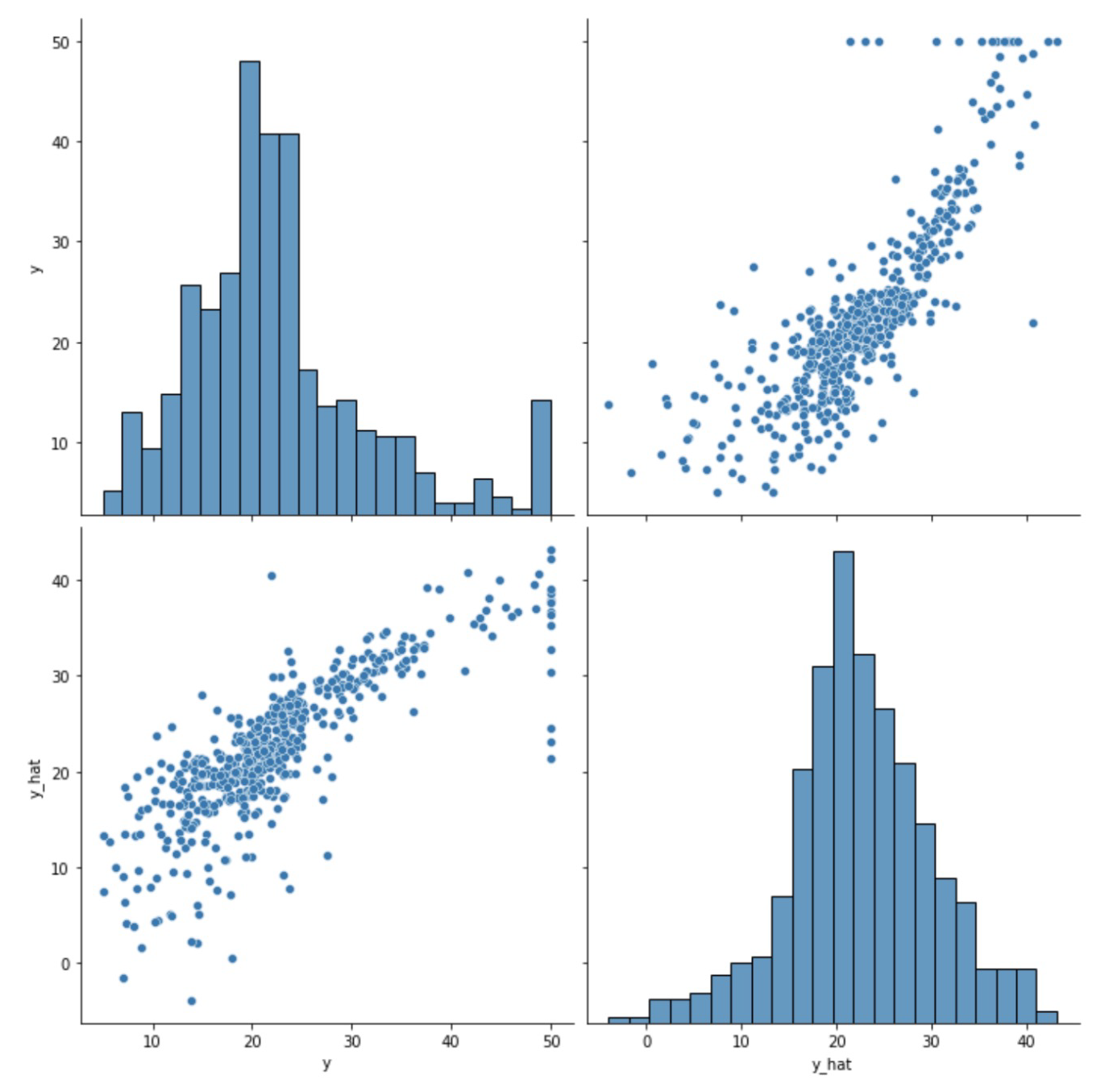
3. Breast cancer
데이터 읽기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['class'] = cancer.target관심있는 컬럼 관찰
cols = ['mean radius', 'mean texture', 'mean smoothness', 'mean compactness', 'mean concave points',
'worst radius', 'worst texture', 'worst smoothness', 'worst compactness', 'worst concave points', 'class']
for c in cols[:-1]:
sns.histplot(df, x=c, hue=cols[-1], bins=50, stat='probability')
plt.show()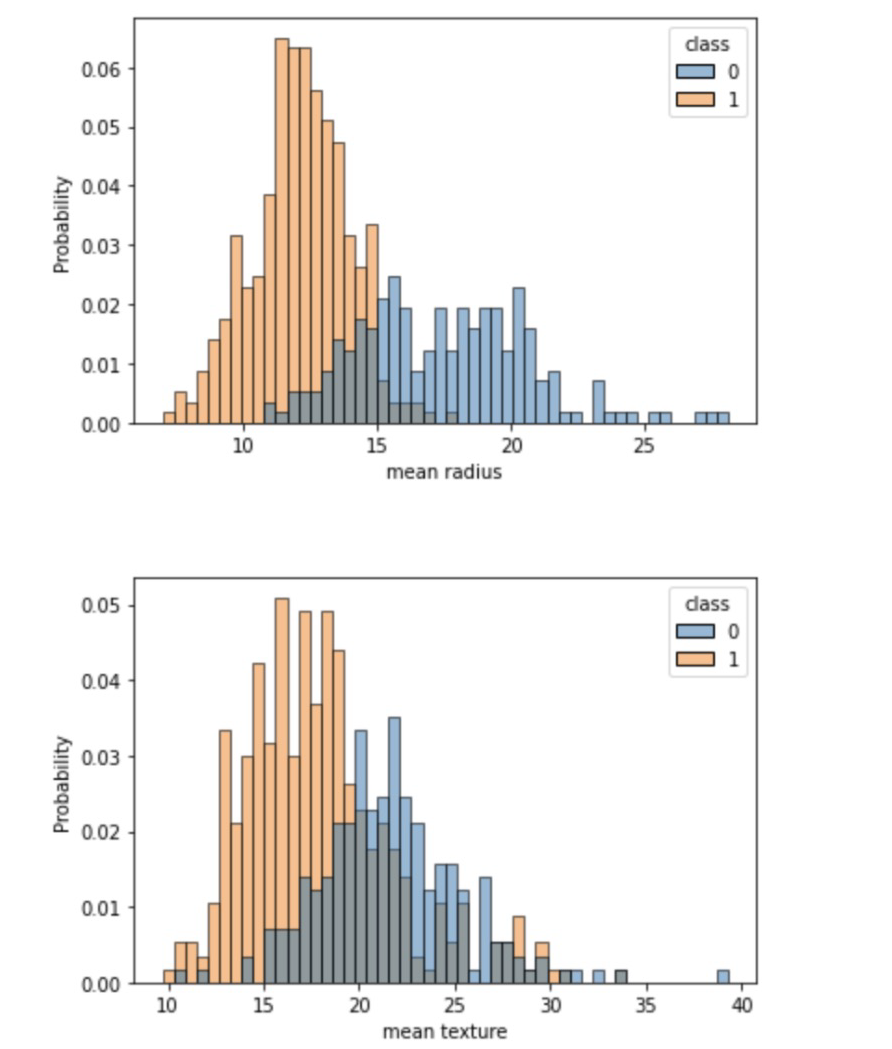
데이터 분리
# 모듈 import
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
data = torch.from_numpy(df[cols].values).float()
# 라벨과 특성으로 나누기
x = data[:, :-1]
y = data[:, -1:]모델 수립
# 하이퍼파라미터
n_epochs = 200000
learning_rate = 1e-2
print_interval = 10000
class MyModel(nn.Module):
def __init__(self, input_dim, output_dim):
self.input_dim = input_dim
self.output_dim = output_dim
super().__init__() # 모듈 속성 상속
self.linear = nn.Linear(input_dim, output_dim) # 이진분류
self.act = nn.Sigmoid()
def forward(self, x):
# |x| = (batch_size, input_dim)
y = self.act(self.linear(x))
# |y| = (batch_size, output_dim)
return y모델, Loss, optim 선언
model = MyModel(input_dim=x.size(-1), output_dim=y.size(-1))
crit = nn.BCELoss() # MSELoss 대신 BCELoss 정의
optimizer = optim.SGD(model.parameters(), lr=learning_rate)학습
for i in range(n_epochs):
y_hat = model(x)
loss = crit(y_hat, y) # loss 계산
optimizer.zero_grad() # tensor의 gradient가 연산될 때, gradient값이 축적되는걸 막아주기 위해서
loss.backward()
optimizer.step() # 한 스텝 진행
if (i+1) % print_interval == 0: # 1print_interval마다 print
print('Epoch %d: loss=%.4e ' % (i + 1, loss))acc계산
correct_cnt = (y==(y_hat > 0.5)).sum()
total_cnt = float(y.size(0))
print('Accuracy: %.4f' % (correct_cnt / total_cnt))예측값 분포 확인
df = pd.DataFrame(torch.cat([y, y_hat], dim=1).detach_().numpy(), columns=['y', 'y_hat'])
sns.histplot(df, x='y_hat', hue='y', bins=50, stat='probability')
plt.show()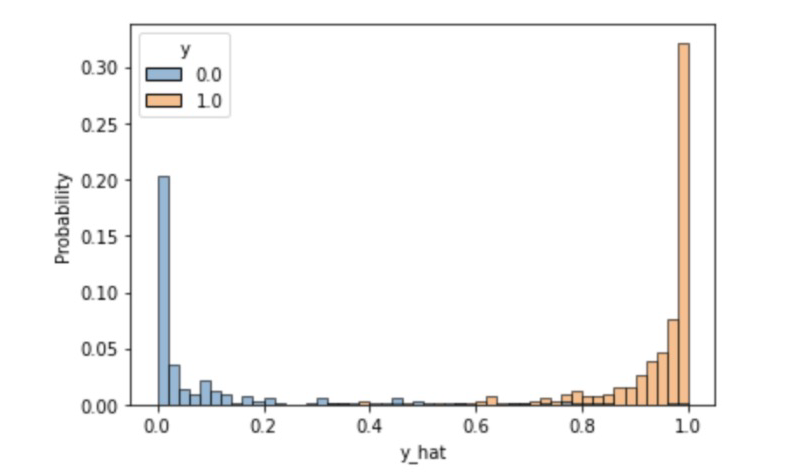
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it