1. label_encoder
- 대상이 되는 문자로 된 데이터를 숫자 * 카테고리컬한 데이터로 변환
- fit() → transform() = fit_transform()
- inverse_transform(): 역변환
import pandas as pd
df = pd.DataFrame({
'A':['a', 'b', 'c', 'a', 'b'],
'B':[1,2,3,1,0]
})
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])
le.transform(['a','b']) # array([0, 1])
le.inverse_transform([1,2,2,2]) # array(['b', 'c', 'c', 'c'], dtype=object)
# fit-transform 한 번에 진행
le.fit_transform(df['A'])2. Scale
min-max scaling
- 기본값 0 ~ 1 (min:0, max:1)
- outlier(이상치)에 영향을 받는다.
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
# fit
mms.fit(df)
# transform
df_mms = mms.transform(df)
# 역변환
mms.inverse_transform(df_mms)
# 한 번에
mms.fit_transform(df)Standart Scaler
- 표준 정규 분포
- 기본값 0 ~ 1 (평균:0, 표준편차:1)
- outlier(이상치)에 영향을 받는다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)
df_ss = ss.transform(df)
ss.inverse_transform(df_ss)
ss.fit_transform(df)Robust Scaler
- 기본값 0 ~ 1 (중간값:0, Q3 사분위값:1)
- outlier(이상치)에 영향 최소화
from sklearn.preprocessing import RobustScaler
rs = RobustScaler()
df_rs = rs.fit_transform(df)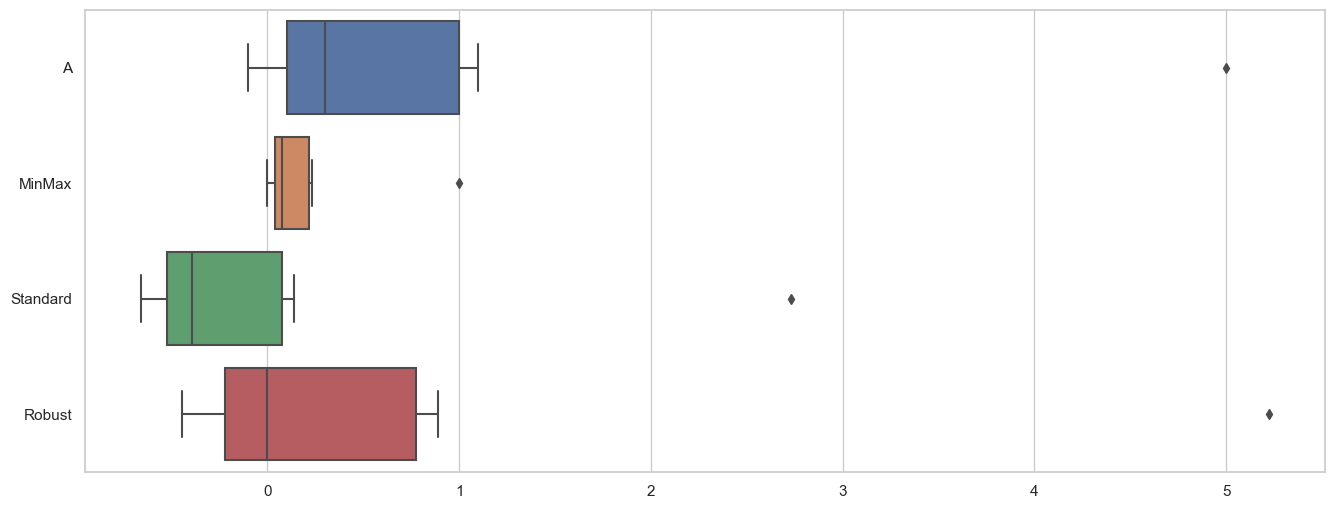
Reference
1) 데이터스쿨 강의자료

데이터 사이언스 / just do it