데이터
- 캐글: https://grouplens.org/datasets/movielens/latest/
- 영화의 평점을 매긴 사용자와 영화 평점 행렬 등의 데이터
- small 데이터 사용
- movie.csv: movieId, title, genre
- rating.csv: usrId, movieId, rating, timestamp
실습
1) 데이터 읽기
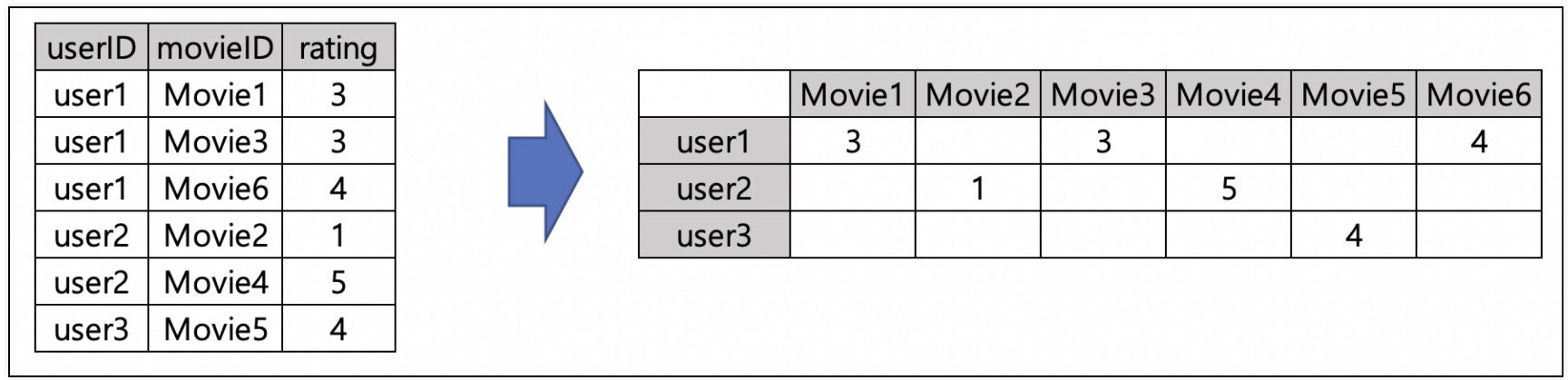
2) 사진과 같이 userId & movieId matrix 만들기 위해 pivot_table
3) ratings와 movie를 movieID 기준으로 결합
4) pivot_table을 이용해서 userId & title matrix 만들기
5) nan은 0으로 변환
6) 유사도 측정을 위해 행렬의 transpose()
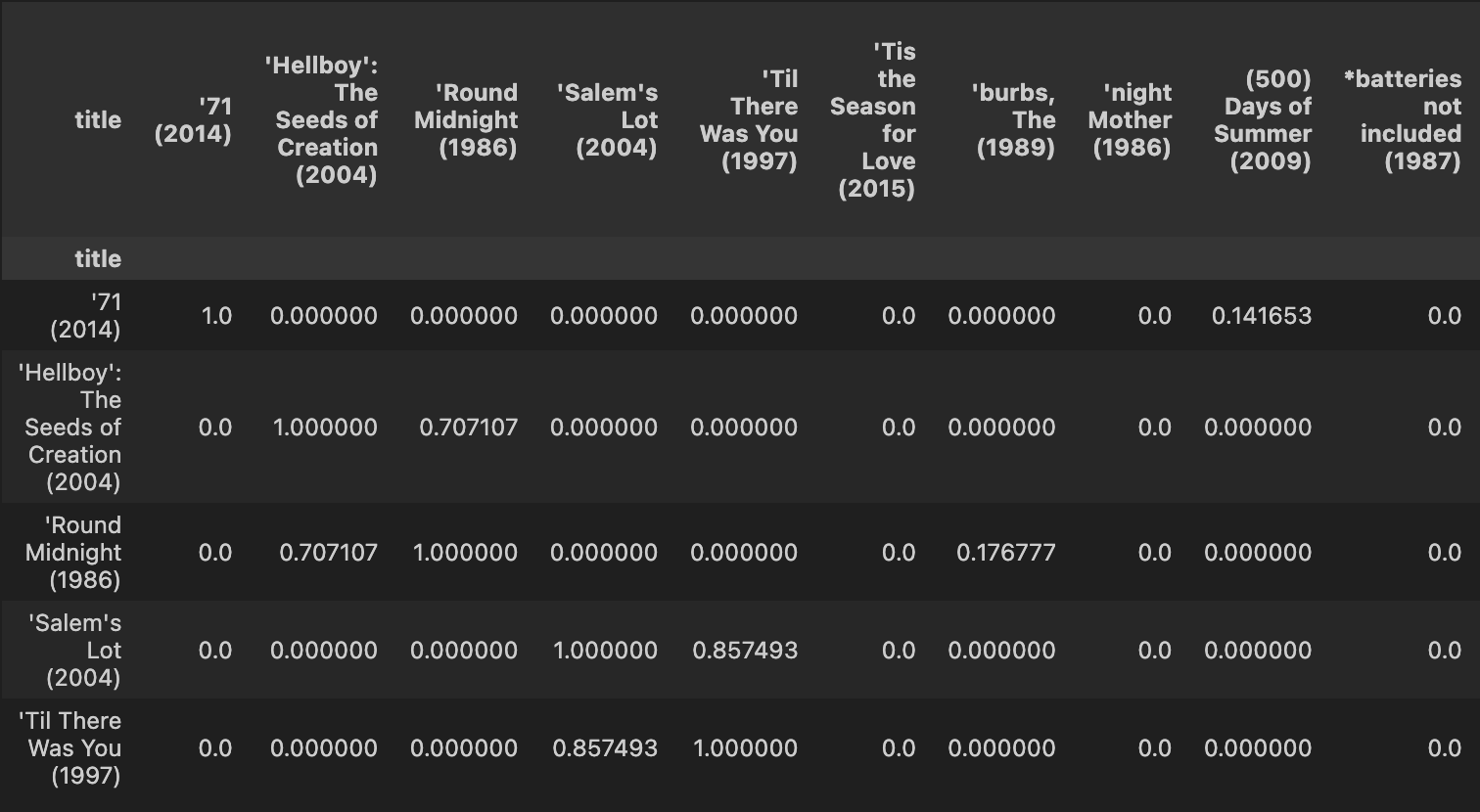
7) cosine_similarity로 유사도 측정
import pandas as pd
import numpy as np
# 1
movies = pd.read_csv('./data/small/movies.csv')
ratings = pd.read_csv('./data/small/ratings.csv')
ratings = ratings[['userId', 'movieId', 'rating']]
# 2
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
# 3
rating_movies = pd.merge(ratings, movies, on='movieId')
# 4
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
# 5
ratings_matrix = ratings_matrix.fillna(0)
# 6
ratings_matrix_T = ratings_matrix.transpose()
# 7
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns, columns=ratings_matrix.columns)
# 대부
item_sim_df['Godfather, The (1972)'].sort_values(ascending=False)[:6]
# 인셉션
item_sim_df['Inception (2010)'].sort_values(ascending=False)[:6]
'''
title
Godfather, The (1972) 1.000000
Godfather: Part II, The (1974) 0.821773
Goodfellas (1990) 0.664841
One Flew Over the Cuckoo's Nest (1975) 0.620536
Star Wars: Episode IV - A New Hope (1977) 0.595317
Fargo (1996) 0.588614
Name: Godfather, The (1972), dtype: float64
-----------------------------------------------------
title
Inception (2010) 1.000000
Dark Knight, The (2008) 0.727263
Inglourious Basterds (2009) 0.646103
Shutter Island (2010) 0.617736
Dark Knight Rises, The (2012) 0.617504
Fight Club (1999) 0.615417
Name: Inception (2010), dtype: float64
'''Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it