BeautifulSoup
1) BeautifulSoup 설치
- BeautifulSoup: HTML 및 XML 파일에서 데이터를 추출하기 위한 Python 라이브러리
- 터미널에서 아래 명령어들 중 하나 입력
- conda install -c anaconda beautifulsoup4
- pip install beautifulsoup4
2) BeautifulSoup Basic
- parser: 인터프리터나 컴파일러의 구성 요소 가운데 하나로, 입력 토큰에 내재된 자료 구조를 빌드하고 문법을 검사를 한다.
- prettify(): 들여쓰기
- python 예약어 class, id, def, list, str, int, tuple 겹치지 않게 하는 것이 좋다. 예시) class_
- 원하는 객체 찾기: find, find_all, select_one, select
- 객체 텍스트 추출: text, string, get_text()
- get_text(separator, strip, types) attrs: dictionary 형태로 속성들을 반환태그['속성']: 속성 값 추출
from bs4 import BeautifulSoup
page = open("../data/03. test_first.html", "r").read()
#print(page) -> 자동 들여쓰기됨
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify()) #들여쓰기 prettify
# head tag
soup.head
'''
결과
<head>
<title>
Very Simple HTML Code by me
</title>
</head>
'''
# body tag
soup.body
# soup.p
soup.find("p")
# class_
soup.find("p", class_="inner-text")
soup.find("p", {"class":"outer-text first-item"}).text.strip()
#다중 조건
soup.find("p", {"class":"inner-text first-item", "id":"first"})
# find_all()
soup.find_all("p")
# 특정 태그 확인
soup.find_all(class_="outer-text")
# 텍스트 추출
print(soup.find_all("p")[0].text)
print(soup.find_all("p")[1].string)
print(soup.find_all("p")[1].get_text())
'''
결과
ZeroBase
PinkWink
None
Happy Data Science
Python
'''
# a 태그에서 href 속성값에 있는 값 추출
links = soup.find_all("a")
links[0].get("href"), links[1]["href"]
for each in links:
href = each.get("href")
text = each.get_text()
print(text + "->" + href)예제 1: 네이버 금융
1) 예제 1-1
- urllib.request 모듈: 복잡한 세계에서 URL(대부분 HTTP)을 여는 데 도움이 되는 함수와 클래스를 정의(basic과 다이제스트 인증, 리디렉션, 쿠키 등)
- response.status: http 상태 코드, 2xx 성공
from urllib.request import urlopen
from bs4 import BeautifulSoup
# 보통 자주 사용하는 변수 이름: response, res
url = "https://finance.naver.com/marketindex/"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
'''
Output exceeds the size limit. Open the full output data in a text editor<script language="javascript" src="/template/head_js.naver?referer=info.finance.naver.com&menu=marketindex&submenu=market">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230502113716/js/info/jindo.min.ns.1.5.3.euckr.js" type="text/javascript">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230502113716/js/jindo.1.5.3.element-text-patch.js" type="text/javascript">
</script>
<div id="container" style="padding-bottom:0px;">
...
</script>
'''
# tag, class 찾기
(soup.find_all("span", {"class":"value"})[0].text,
soup.find_all("span", {"class":"value"})[0].string,
soup.find_all("span", {"class":"value"})[0].get_text())2) 예제 1-2
- !pip install reqests
- requests: 데이터를 보낼 때 딕셔너리 형태로 보낸다, 없는 페이지를 요청해도 에러를 띄우지 않는다
- urllib.request: 데이터를 보낼 때 인코딩하여 바이너리 형태로 보낸다, 없는 페이지를 요청하면 에러를 띄운다
- object of type 'response' has no len() 오류: response.text(아래 코드 참고)
- find, find_all(하나, 여러개)
- select, select_one(여러개, 하나)
- id → '#아이디 이름' or id="아이디 이름"
- class → '.클래스 이름'
- 바로 하위 → '> 하위 태그'
- find vs select → 이름, 속성, 속성값을 특정하여 태그를 찾기 vs CSS selector로 tag 객체를 찾아 반환
# find
soup.find('p', class_='first')
# select_one
soup.select_one('p.first')
---------------------------------------------------------
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
# object of type 'response' has no len() 오류
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify())
exchangeList = soup.select("#exchangeList > li")
exchangeList
# 4개 데이터 수집
import pandas as pd
exchange_datas = []
baseurl = "http://finance.naver.com"
for item in exchangeList:
data = {
"title":item.select_one(".h_lst").text,
"exchange":item.select_one(".value").text,
"change":item.select_one(".change").text,
"updown":item.select_one(".head_info > .blind").text,
"link": baseurl + exchangeList[0].select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx", encoding="utf-8")예제 2: 위키백과 문서 정보 가져오기
- urllib.request에 Request객체 존재
- 한글이 섞인 주소 가져오는 방법:
1) 구글 decode
2) 문자열 format으로 변환 - urllib.parse.quote: 글자를 url로 인코딩(자세한 내용은 7번 reference 참고)
- replace(): 문자열 치환
#"https://ko.wikipedia.org/wiki/여명의_눈동자"
# 문자열 format형으로 변환
import urllib
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
html = "https://ko.wikipedia.org/wiki/{search_wrod}"
# 글자를 url로 인코딩
req = Request(html.format(search_wrod=urllib.parse.quote("여명의_눈동자")))
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())
n = 0
for each in soup.find_all("ul"):
print("=>" + str(n) + "-------------------")
print(each.get_text())
n += 1
soup.find_all("ul")[32].text.strip().replace("\xa0", "").replace("\n", " ")예제 3: 시카고 맛집 데이터 분석
- chicago magazine the 50 best sandwiches
- 최종 목표: 총 51개 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴 가격
- 가게주소
1) 메인 페이지
- response 문제시 User-Agent 확인(개발자 도구 → network)
- User-Agent request header: 서버 및 network peers가 응용 프로그램, 운영체제, 벤더 또는 요청하는 user agent의 버전을 식별할 수 있는 특성 문자열
- 403 forbidden로 서버가 요청을 거부할 경우 user_agent로 해결
- user_agent 모듈: 랜덤하게 headers를 생성
- urljoin(): url를 결합시켜 전체(절대)url를 구성
- re 모듈(10번 reference 참고)
- split(): 문자열 나누기, 결과 리스트
- search(): 문자열 전체를 검색하여 정규식과 일치하는지 조사
- group(): match 객체의 메서드로 매치된 문자열을 리턴
# User-Agent 기본적인 방법
# req = Request(url, headers={"User-Agent": "Chrome"})
# response = urlopen(req)
# response
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
from user_agent import generate_user_agent
url_base = "https://www.chicagomag.com/"
url_sub ="november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
user_agent = generate_user_agent(navigator='chrome')
req = Request(url, headers={"User-Agent": user_agent})
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
import re
from urllib.parse import urljoin
url_base = "https://www.chicagomag.com/"
# 필요한 내용을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add= []
list_soup = soup.find_all("div", "sammy")
for item in list_soup:
#랭크
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").text
#메뉴
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
#가게이름
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
#상대주소 -> urljoin
url_add.append(urljoin(url_base, item.find("a")["href"]))
import pandas as pd
data = {
"Rank": rank,
"Menu": main_menu,
"Cafe": cafe_name,
"URL": url_add
}
df = pd.DataFrame(data)
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.to_csv("../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8")결과

2) 하위 페이지
- import에서 from 구문으로 넘어가는 것이 일반적
- tqdm(): 반복문 동작 중인지 확인하게 해줌
- tqdm 설치: 터미널에 'conda install -c conda-forge tqdm' 명령
import pandas as pd
from urllib.request import urlopen, Request
from user_agent import generate_user_agent
from bs4 import BeautifulSoup
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
import re
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
# 원하는 페이지에 접속
req = Request(row["URL"], headers={"user-agent":user_agent})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
# 원하는 정보 추출
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
# regular expression
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
df.to_csv("../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="utf-8")
pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)결과
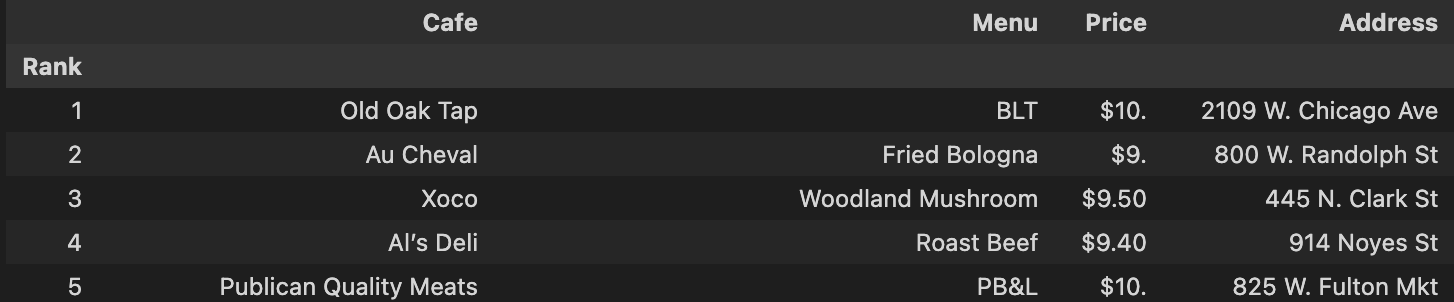
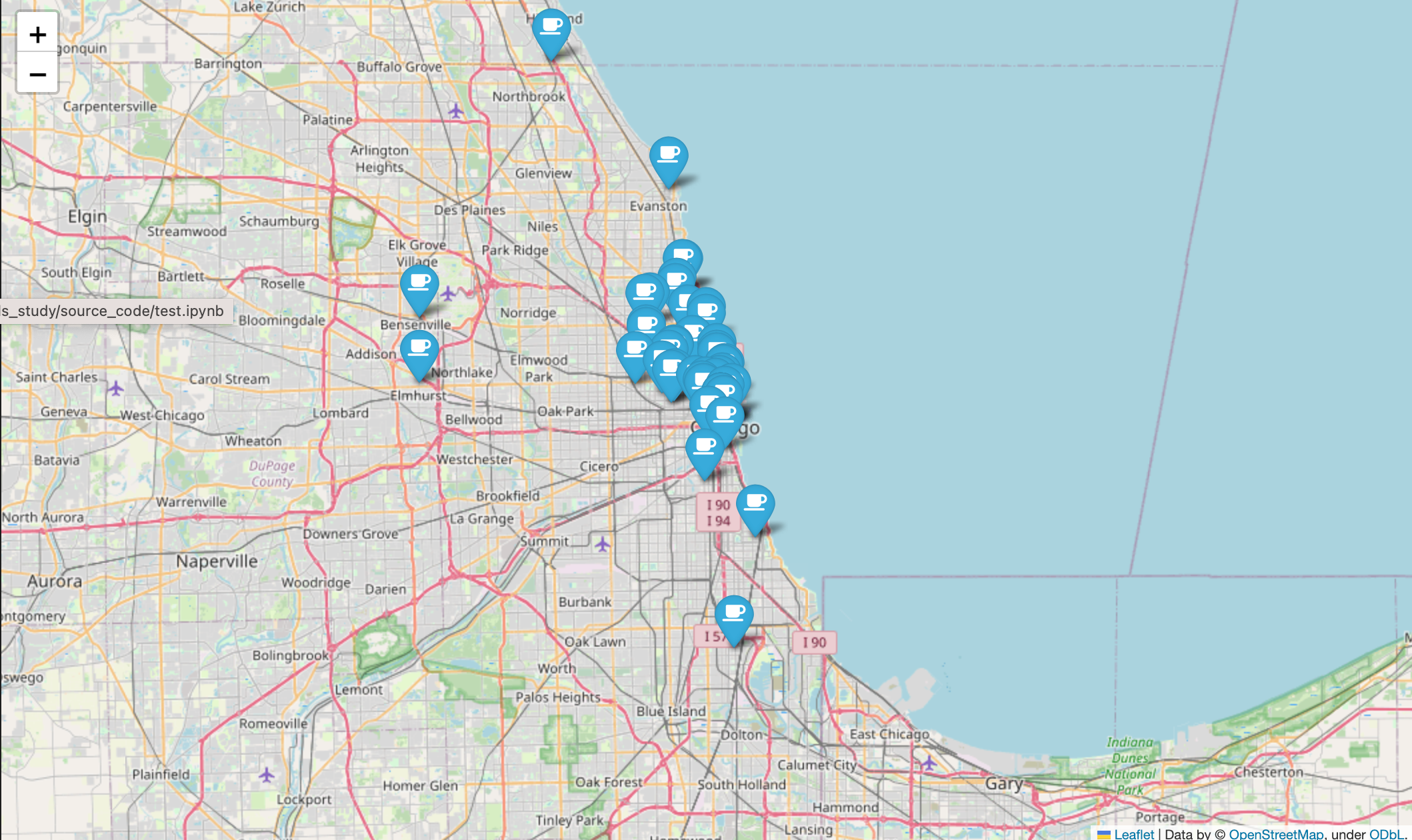
3) 시카고 맛집 데이터 지도 시각화
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm
df = pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
gmaps_key="key값"
gmaps=googlemaps.Client(key=gmaps_key)
lat=[]
lng=[]
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
gamps_output = gmaps.geocode(target_name)
location_output = gamps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)
df["lat"] = lat
df["lng"] = lng
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start = 11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
prefix="fa"
)
).add_to(mapping)
mapping결과
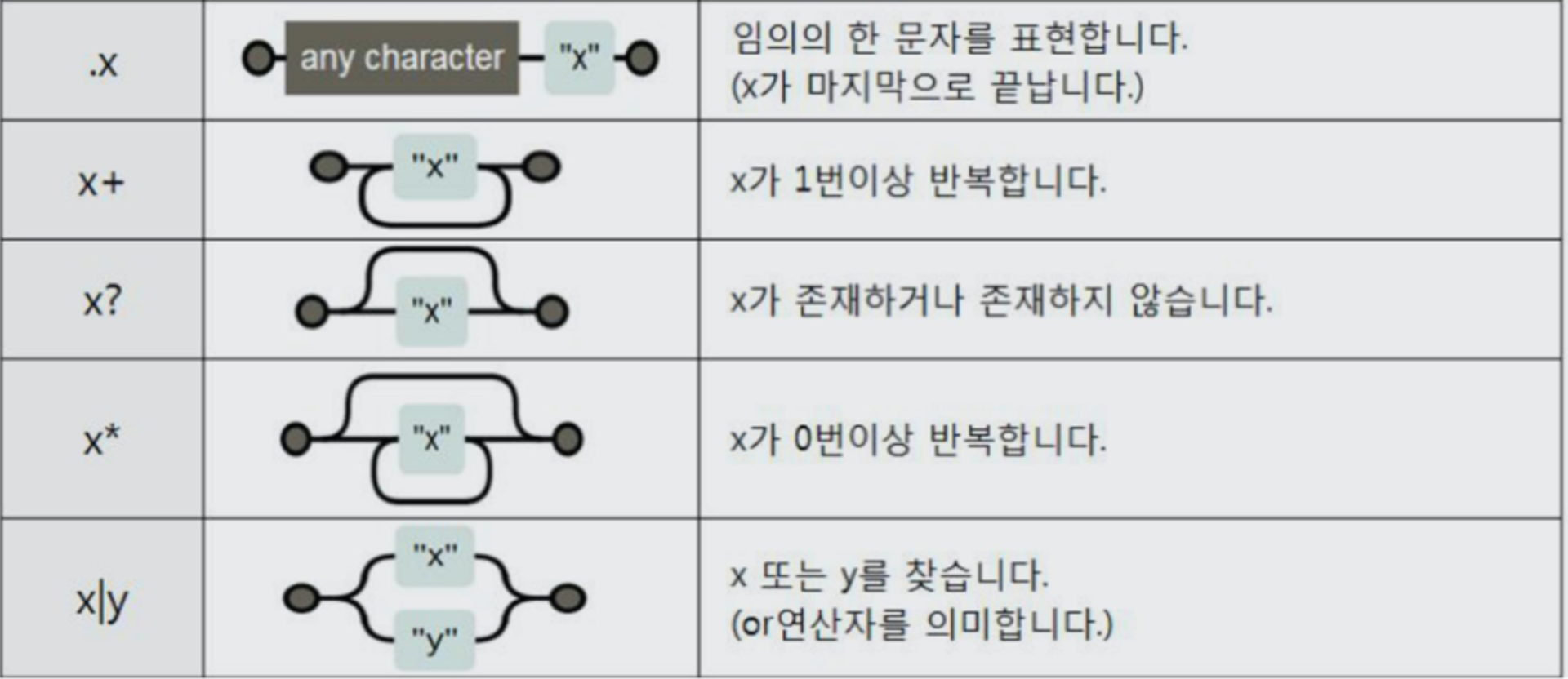
regular expression 기초
파서 차이점

Referecne
1) BeautifulSoup 홈페이지: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
2) 구문 분석 위키백과: https://ko.wikipedia.org/wiki/%EA%B5%AC%EB%AC%B8_%EB%B6%84%EC%84%9D
3) python urllib.request 문서: https://docs.python.org/ko/3/library/urllib.request.html
4) HTTP 상태 코드: https://ko.wikipedia.org/wiki/HTTP_%EC%83%81%ED%83%9C_%EC%BD%94%EB%93%9C
5) requests vs urllib.request : https://moondol-ai.tistory.com/238
6) object of type 'response' has no len() 오류: https://stackoverflow.com/questions/36709165/typeerror-object-of-type-response-has-no-len
7) urllib.parse(quote, urljoin함수): https://docs.python.org/ko/3/library/urllib.parse.html
8) find, select 차이점: https://desarraigado.tistory.com/14
9) User-agent 설명: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent
10) user-agent 모듈: https://domdom.tistory.com/329
10) 정규 표현식, re 모듈: https://wikidocs.net/4308#_1
11) regular expression: https://ko.wikipedia.org/w/index.php?title=%EC%A0%95%EA%B7%9C_%ED%91%9C%ED%98%84%EC%8B%9D&ref=nextree.co.kr
12) Pandas Dataframe의 다양한 iteration 방법 비교: https://inmoonlight.github.io/2021/02/04/Pandas-Dataframe-iterations/
13) 파이썬 나도코딩 웹크롤링 요약: https://hyunwk.github.io/python/2021/10/26/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%82%98%EB%8F%84%EC%BD%94%EB%94%A9-%EC%9B%B9%ED%81%AC%EB%A1%A4%EB%A7%81-%EC%9A%94%EC%95%BD.html
14) 제로베이스 데이터스쿨 강의자료
