시작하기 전
- 데이터 스쿨 강의에서는 네이버 영화 차트를 분석했으나, 23년 3월 31일 이후 중단되어 강의와 다른 url를 선택했다.
- 벅스를 선택한 이유: url에 날짜가 나와 시각화에 편리해서
1. 벅스 일간 차트 분석
https://music.bugs.co.kr/chart/track/day/total?chartdate=20230501- 웹 페이지 주소에는 많은 정보가 담겨있다.
- 원하는 정보를 얻기 위해서 변화시켜줘야 하는 주소의 규칙을 찾을 수 있다.
- 여기에서는 날짜 정보를 변경해주면 해당 페이지에 접근이 가능하다.
- list comprehension
→ for문을 사용하지만 변수를 크게 사용하지 않을 때 n 대신 '_' 가능 - pandas date_range, strftime
- 크롤링시 너무 빠르면 컴퓨터로 인식해서 차단
→ import time, time.sleep() 함수 사용 - astype(아래 정리 참고)
1) DataFrame 생성
import pandas as pd
from urllib.request import urlopen
from bs4 import BeautifulSoup
# 자동화 코드
date = pd.date_range("2023.01.01", periods=50, freq="D")
import time
from tqdm import tqdm
music_name = []
music_ranking = []
music_date = []
for today in tqdm(date):
url = "https://music.bugs.co.kr/chart/track/day/total?chartdate={date}"
response = urlopen(url.format(date=today.strftime("%Y%m%d")))
soup = BeautifulSoup(response, "html.parser")
# Top100으로 정해져있지만 혹시 모를 경우를 위해
end = len(soup.find_all("p", "title"))
#for 사용하지만 변수 크게 사용하지 않을 때 n대신 '_' 가능
music_date.extend([today for _ in range(0, end)])
music_name.extend([soup.select("p.title")[n].a.text for n in range(0, end)])
music_ranking.extend(soup.find_all("div", "ranking")[n].strong.string for n in range(0, end))
#크롤링시 너무 빠르면 컴퓨터로 인식해서 차단
time.sleep(0.5)
music = pd.DataFrame({
"date":music_date,
"name":music_name,
"ranking":music_ranking
})
# object -> astype(float)
music.info()
music["ranking"] = music["ranking"].astype(float)
# save
music.to_csv("../data/03. bugs_musci_data.csv", sep=",", encoding="utf-8")2) DataFrame 시각화
- 선 그래프 x축 날짜, y축 랭킹 → 날짜에 따른 랭킹 변화를 선그래프로 표현(시계열)
- matplotlib 한글 설정 → 모듈화
- query(), 축 뒤집기, plt.tick_params() → 아래 정리 참고
import pandas as pd
import numpy as np
music = pd.read_csv("../data/03. bugs_musci_data.csv", index_col=0)
music_pivot = pd.pivot_table(data=music, index="date", columns="name", values="ranking")
music_pivot.to_excel("../data/03. music_pivot.xlsx")
# matplotlib 한글 설정 -> 모듈화
import platform
import seaborn as sns
from matplotlib import font_manager, rc
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family="Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family=font_name)
else:
print("Unknown system sorry")
target_col = ["ANTIFRAGILE", "After LIKE", "All I Want for Christmas Is You", "파이팅 해야지 (Feat. 이영지)", "취중고백"]
plt.figure(figsize=(20, 10))
plt.title("날짜별 랭킹")
plt.xlabel("날짜")
plt.ylabel("랭킹")
plt.gca().invert_yaxis()
plt.xticks(rotation="vertical")
#x축 선 추가
plt.tick_params(bottom="off", labelbottom="off")
plt.plot(music_pivot[target_col])
plt.legend(target_col, loc="best")
plt.grid(True)
plt.show()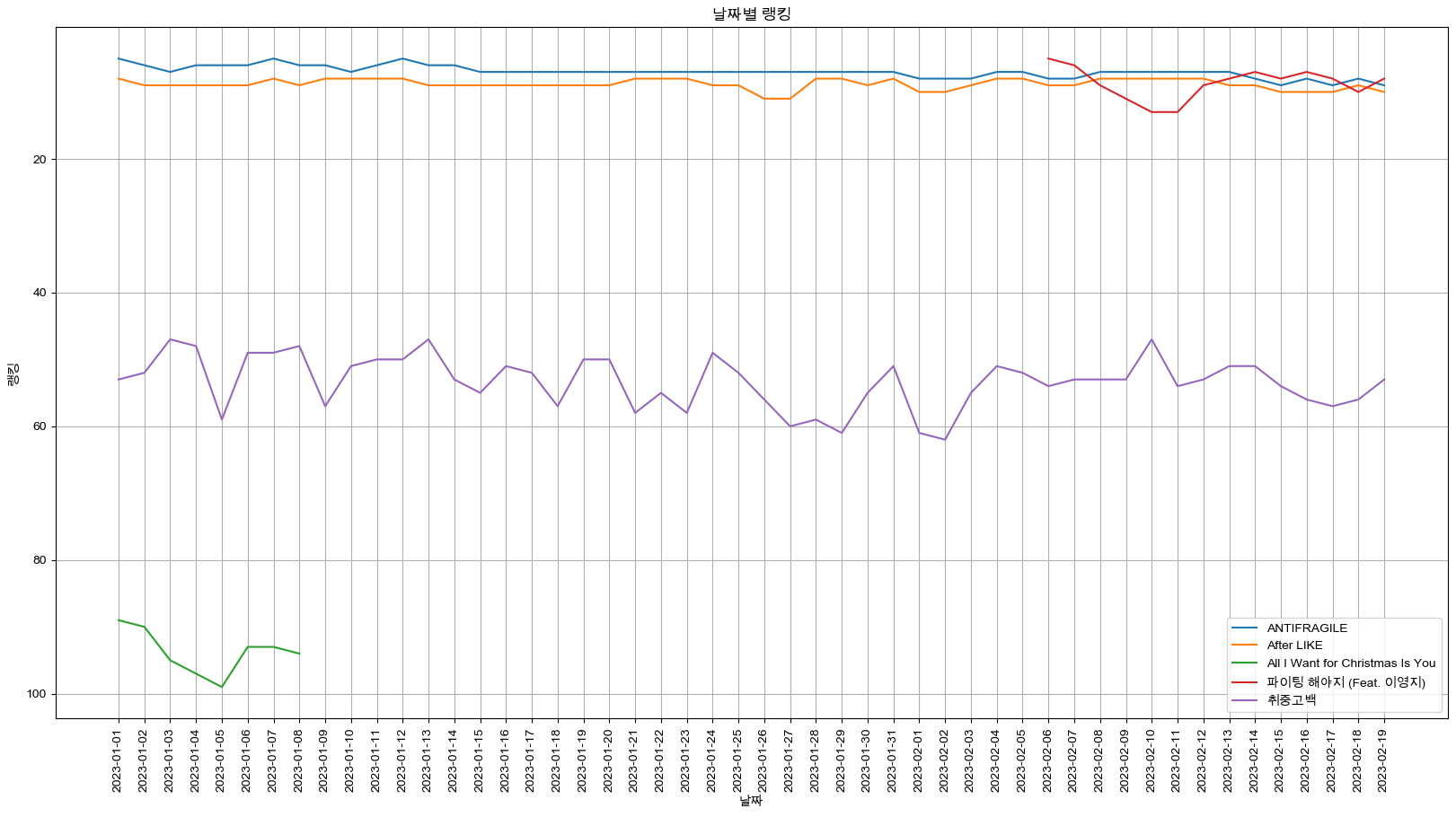
3) 관련 함수 정리
- DataFrame형 변환:
df.astype(dtype, copy=True, errors='raies')
dtype : 변경할 type
copy : 사본을 생성할지 여부
errors : {'raies', 'ignore'}, 변경불가시 오류를 발생시킬 여부
- 축 반전:
plt.gca().invert_xaxis()
plt.gca().invert_yaxis()
# plt.xlim([xmin, xmax])
plt.xlim(max(x),min(x))
#plt.ylim([ymin, ymax])
plt.ylim(max(y),min(y))
# plt.axis([min(x),max(x),min(y),max(y)])
plt.axis([max(x),min(x),max(y),min(y)])- df.query(): pandas 조건 검색하기
ex) tmp = music.query("name == ['ANTIFRAGILE']")

- 그래프 틱 설정: 자세한 parameter는 아래 홈페이지 참조
https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.tick_params.html
plt.tick_params(bottom="off", labelbottom="off")
plt.tick_params(axis='both', direction='in', length=3, pad=6, labelsize=14)Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://blog-of-gon.tistory.com/341

데이터 사이언스 / just do it