
YOLO
You Only Look Once의 약자로 Object Detection을 위한 딥러닝 모델이다. YOLO 모델은 이미지를 한 번만 보고 객체 탐지를 하기에 이미지에 대한 빠른 학습이 가능하다.
기존의 검출 모델은 분류기를 재정의해 검출기로 사용하고 있다. 대표적인 모델로는 R-CNN이 존재한다. 하지만 R-CNN은 속도가 느리고 비용 부담이 크기에 단점들이 많이 존재한다. 이런 문제 개선을 위해 YOLO 알고리즘은 이미지 내 객체 검출을 하나의 회귀 문제로 보고 절차를 개선하였다.

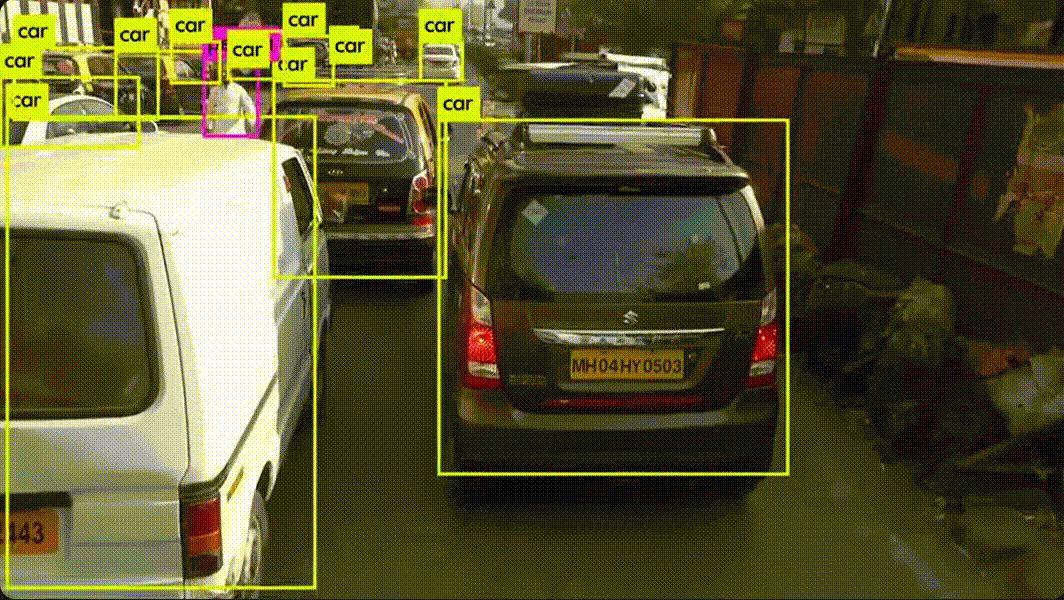
Figure 1의 하나의 convolution network가 여러 bounding box와 클래스 확률을 동시에 계산한다.
- 이미지를 한번에 전체적으로 바라보고 물체의 위치와 클래스를 예측
- 이미지 전체를 그리드로 나누고 각 그리드 셀이 객체의 위치 정보를 예측
- CNN 종류 중 하나
!git clone https://github.com/THU-MIG/yolov10
%cd yolov10
!pip install -r requirements.txt이때 다음과 같은 명령어로 모델을 불러올 수 있다.
Roboflow
roboflow는 객체 탐지, 분류, 세그멘테이션 등을 위한 데이터셋을 준비, 관리, 학습, 배포하는 플랫폼이다.
- 이미지 업로드, 객체 박스 직접 지정 및 업로드 가능
- 자동 애노테이션
- 다양한 포맷으로 데이터셋 다운 가능
- 학습 가능 (학습 후 결과는 유료 결제 필요)
kaggle이나 공공데이터 포털에서 가져온 데이터셋을 roboflow를 통해 annotation 파일을 업로드 한다.
그 후, roboflow 내에서 bounding box를 편집하고 클래스 이름을 수정하거나, 데이터 Augmentation 설정도 가능하다.
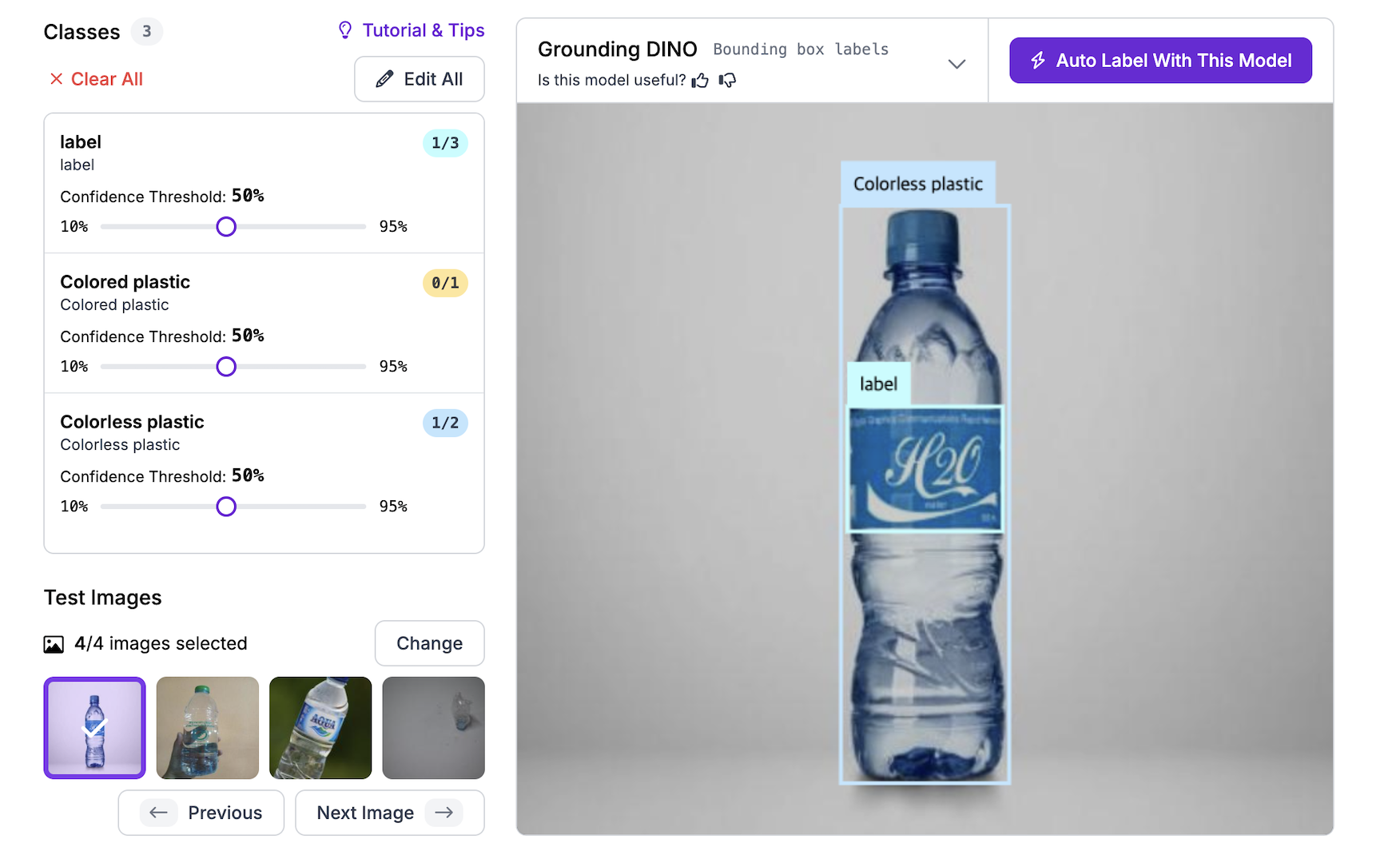
위의 화면과 같이 모델이 예측한 클래스 별로 필터링 하거나 신뢰도를 조정할 수도 있다.
-
신뢰도를 낮게하면 희미한 객체도 잡을 수 있지만 오탐이 많아짐
-
신뢰도를 높게하면 희미하지 않은 객체도 잡히지 않을 수 있음
완료된 데이터들은 왼쪽에 Dataset 메뉴에서 확인할 수 있으며, 데이터 전처리 및 데이터 증강이 가능하다.
그리고 완료되면 원하는 버전으로 데이터셋을 다운받을 수 있다.
