
플라스틱 관련 이미지를 뽑아오려는데 필요한 데이터들만 원하는 class로 변경하여 가져오고 싶었다.
하지만 그렇게되면 YOLO로 돌릴때 필요한 LABEL 데이터들을 일일히 수정해줘야해서 어떻게 해야하나 고민하던 찰나에 간단하게 원하는 데이터들만 뽑아온 뒤에 해당 파일들의 train, valid, test 폴더밑에 존재하는 labels 폴더 안의 .txt 파일들에 있는 id들을 원하는 id로 바꿔준 뒤 각 train, valid, test 폴더들을 합쳐주었다.
데이터 가져오기
먼저 roboflow universe에서 원하는 프로젝트를 받아서 내가 필요한 데이터들만 뽑아온다. 나의 경우에는 PLASTIC, CAN, PAPER 데이터만 필요했기에 클래스 명이 다른것들은 수정하고 필요없는 데이터들은 삭제한 후에 데이터를 다운받아줬다.
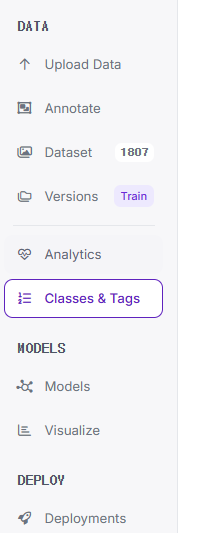
왼쪽 메뉴 바에서 Classes & Tags 메뉴를 눌러주면 클래스 명을 수정 및 삭제할 수 있다.

이런 식으로 원하는 클래스 이름으로 바꿔주고 필요없는 데이터들은 왼쪽에 Dataset을 눌러 삭제해준다.
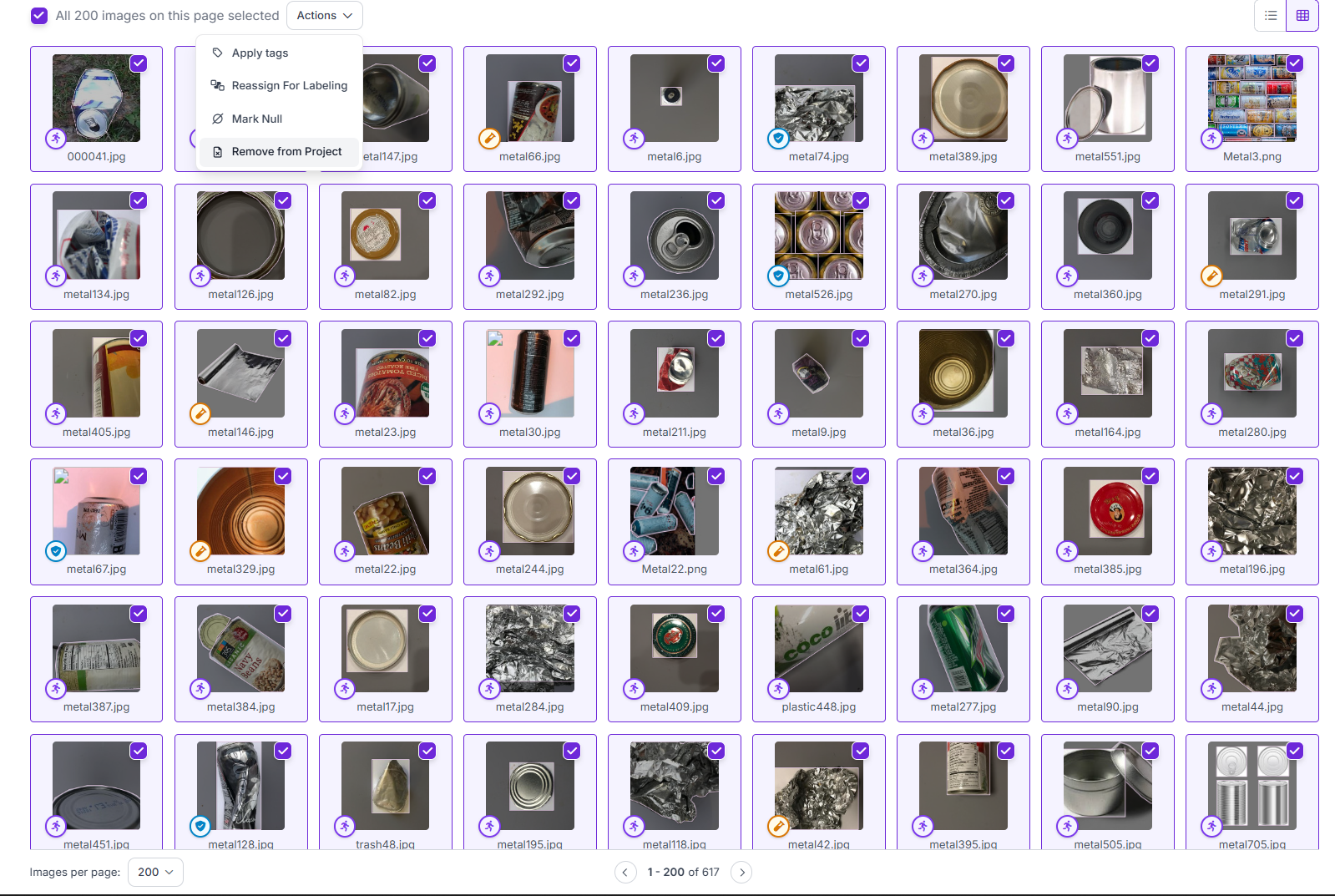
처음엔 전체 삭제가 되는 줄 모르고 하나하나 지우다가 왼쪽 하단의 드롭박스를 통해 최대 200장까지 한 번에 지울 수 있다는 사실을 알게되어 쉽게 데이터를 삭제할 수 있었다.
상황에 따라 필요한만큼 데이터를 전처리해준 뒤에 데이터를 원하는 형식으로 다운받아줬다.
데이터셋을 다운받고 난 뒤 labels 폴더에 들어가면
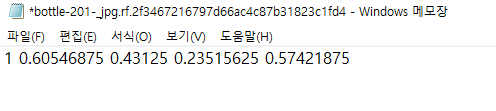
이런 식으로 적혀있는데 맨 앞에 1이라고 적힌 것이 class_id인 것이다. 나는 각각 플라스틱 데이터를 1번으로 바꾸고, 캔 데이터를 5번, 종이 데이터를 4번으로 바꿔줘야 했다.
class_id 변경
나는 colab으로 돌렸기에 jupyter notebook의 코드와 조금 다를 수 있다.
1. zip 압축 풀기
import zipfile
with zipfile.ZipFile("폴더명.zip", 'r') as zip_ref:
zip_ref.extractall("")2. 구글 드라이브와 연동
from google.colab import drive
drive.mount('/content/drive')3. id 변경 코드
import os
def change_class_id_in_file(file_path, from_id=0, to_id=2):
with open(file_path, 'r') as f:
lines = f.readlines()
new_lines = []
for line in lines:
tokens = line.strip().split()
if tokens[0] == str(from_id):
tokens[0] = str(to_id)
new_lines.append(' '.join(tokens) + '\n')
with open(file_path, 'w') as f:
f.writelines(new_lines)
def change_class_id_in_folder(label_dir, from_id=0, to_id=2):
for fname in os.listdir(label_dir):
if fname.endswith(".txt"):
file_path = os.path.join(label_dir, fname)
change_class_id_in_file(file_path, from_id, to_id)4. 원하는 id로 변경
# Colab 작업 디렉토리 내 데이터셋 경로
dataset_base_path = "/content/폴더명"
# 각 split 처리
for split in ["train", "valid", "test"]:
labels_path = os.path.join(dataset_base_path, split, "labels")
change_class_id_in_folder(labels_path, from_id="기존id", to_id="바꿀id")5. 변경된 파일 zip 파일로 압축
import shutil
shutil.make_archive("/content/저장할폴더이름", 'zip', "/content/기존폴더명")
6. 구글 드라이브에 저장
drive_dest = "/content/drive/MyDrive/폴더명.zip"
shutil.move("/content/폴더명.zip", drive_dest)
print(f"업로드 완료: {drive_dest}")7. 드라이브에 저장된 코드 불러오기
!cp /content/drive/MyDrive/폴더명.zip ..