얼굴 인식
주어진 이미지 내에 얼굴이 존재하는지의 여부를 판단하고 얼굴이 존재한다면 그 크기, 위치를 반환한다.
얼굴의 경우 화장 방법, 각도, 빛 등 다양한 이유 때문에 얼굴 인식이 어렵다. 이를 intra-class variations 이라고 한다.
얼굴 인식 절차
1. Face Detection
이미지 내에서 사각형을 찾아 얼굴만 검출한다.
2. Face Alignment
- 단순 크기 정렬
- 얼굴 영역 피팅 후 크기 정렬
- 두 눈 검출후 이미지 내 두 눈의 위치를 동일하도록 정렬
- 얼굴 내 주요 랜드마크를 검출 후 동일한 임의의 모양으로 변환
3. Feature Extraction
- 얼굴 전체 영역에 동일한 알고리즘 적용해 벡터 생성
- 얼굴을 격자로 나눠 각 격자마다 벡터를 생성해 이어붙이는 방법
- 얼굴의 주요 파트별로 벡터를 생성해 이어붙이는 방법
- 얼굴의 주요 랜드마크 검출 후 지역별로 벡터를 생성해 이어붙이는 방법
4. Feature Matching
머신러닝으로 학습가능하며 query image에서 뽑은 feature vector 중 가장 가까운 거리 벡터(유사도 높음)를 찾는다.
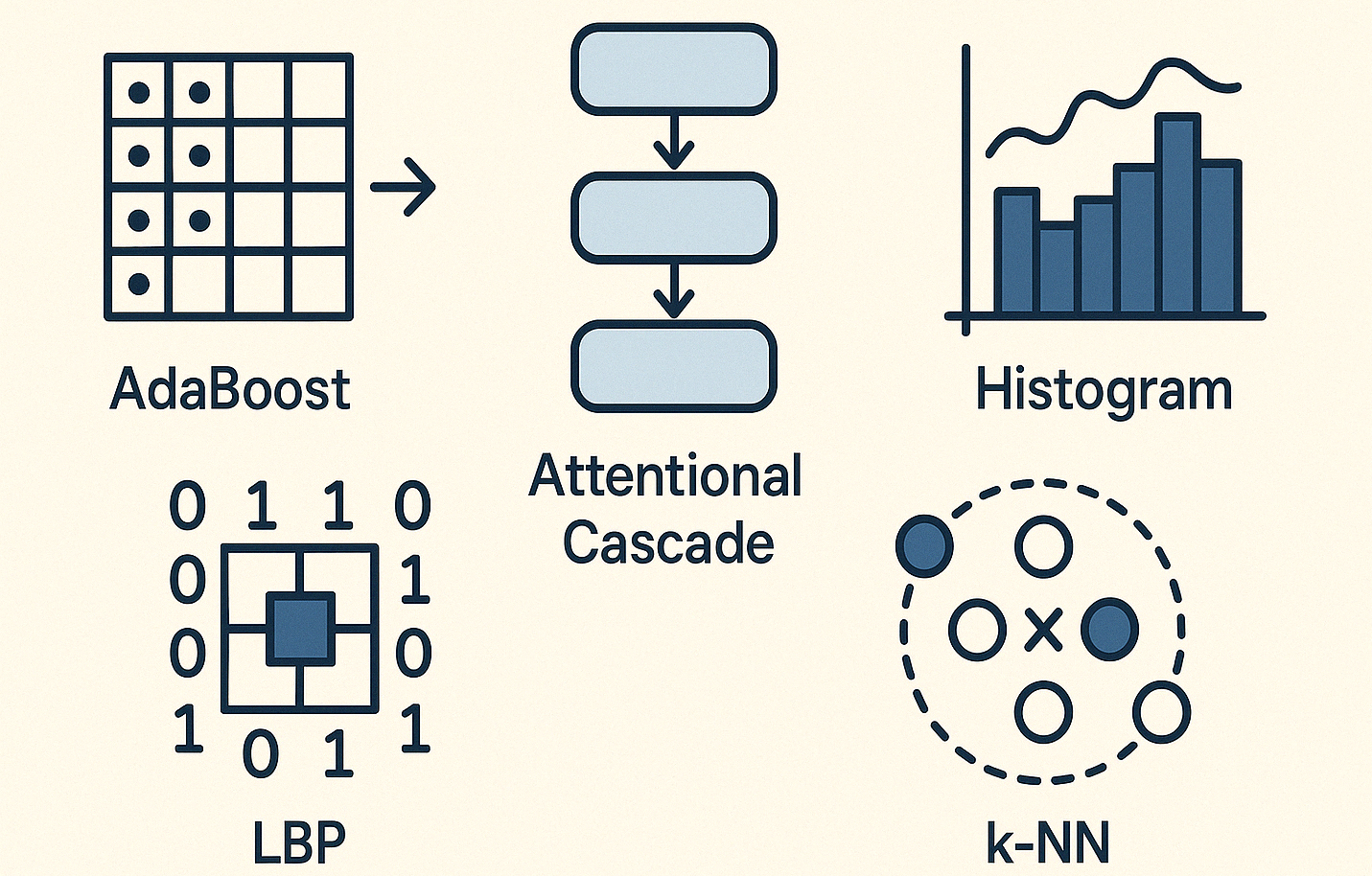
Ada Boost
AdaBoost는 가중치를 두고 이미지 내에 중요한 특징만을 추출한다.
단순한 약한 분류기들을을 가중치를 두고 선형 결합해 하나의 강한 분류기를 만든 것이다.
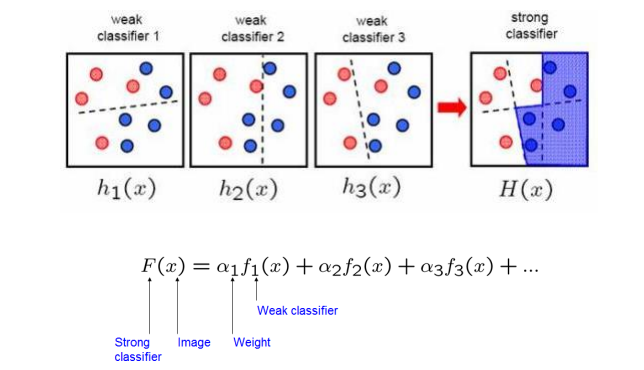
Attentional Cascade
이로 인해 얼굴 검출기의 성능은 좋아졌지만 속도는 빠르지 않았다. 그리고 오탐율도 꽤나 높았다.
그래서 여러 stage로 구성된 계단식 구조인 Attentional Cascade 기법이 등장했다.
각 stage는 약한 분류기로, 얼굴일 가능성이 낮은 이미지는 초기 단계에서 빠르게 제거한다.
최종적으로 모든 단계를 통과한 경우에만 얼굴로 판단하게 되는 것이다.
Multi Scale Detection
얼굴은 다양한 크기로 존재하기에 단일 크기의 검출기 만으로는 어려움
- 이미지 resize + 다양한 크기의 검출기 사용
- 전체 이미지에 대해 sliding window 사용 + 각 이미지에 CascadeClassifier 적용
분류 문제
주어진 이미지가 우리는 누구인지 식별할 수 있어야 한다.
하지만 앞서 말했듯이 얼굴 이미지는 Intra-class Variation으로 인해 인식이 어렵다. 우리는 feature vector를 이용해야 한다.
feature vector는 주어진 이미지 내에 주요 특징들을 추출해 수치화 한 것으로 이 값들은 feature space 상에 나타나게 되고, 이 공간 내에서 벡터 간 거리를 이용해 유사도를 비교하게 된다.
즉, Probe와 가장 가까운 Gallery 벡터를 찾으면 된다. 이 과정은 기계학습을 통해 쉽게 진행할 수 있다.
Probe: 입력받은 얼굴 이미지Gallery: 쉽게 말하면 이미지의 정답
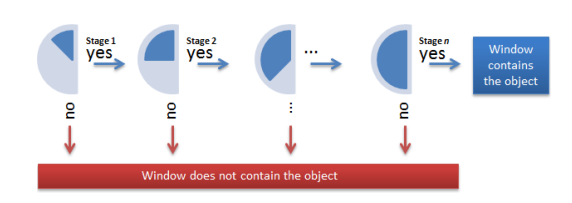
히스토그램 표현법
픽셀 값들의 분포를 계산해 하나의 벡터를 생성하는 표현법이다.
기하학적 차이로 인해 발생하는 오류를 제거해주지만 그와 동시에 기하학적 특징이 완전히 소실된다. 그 이유는 히스토그램 표현법은 픽셀의 밝기 분포만 고려하고 그 픽셀이 어디에 위치하는지는 고려하지 않기 때문이다.
calcHist(), getGrayHistImage() 함수 등을 이용한다.
K-Nearest Neighbors Classifier
주어진 Feature Vector를 Feature Space 상에서 가장 가까운 거리 벡터 클래스로 분류하는 단순한 분류기를 말한다.
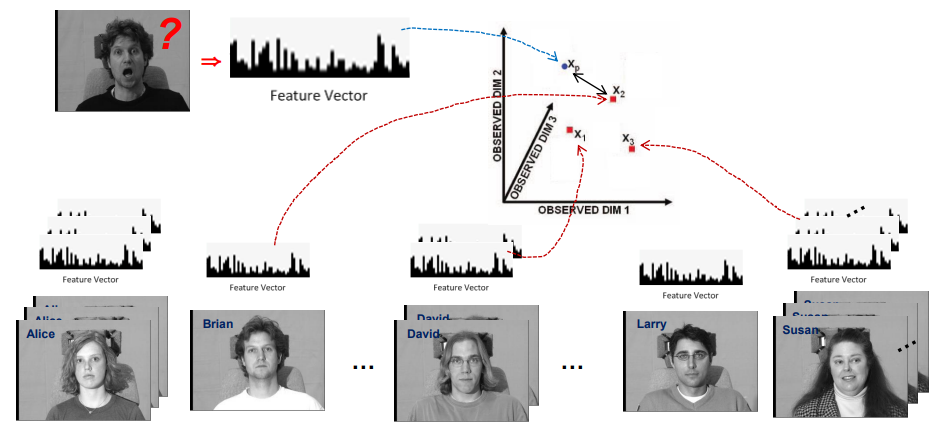
우리는 거리 유사도를 이용해 해당 클래스로 분류한다.
- 입력된 이미지를 Feature vector로 변환
- 학습된 Feature Vector를 각 이미지들의 Feature Vector 와 비교
- 가장 작은거리 또는 가장 큰 유사도를 가진 이미지 선택해 최종 예측 클래스로 결정
Local Binary Pattern
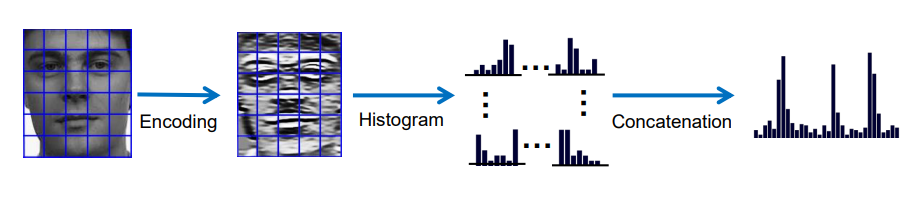
이미지를 격자로 나누어 각 격자마다 벡터를 생성해 히스토그램을 따로 구한다.
한 벡터 당 256차원을 갖는다고 하면 최종 차원은 256*number of cells가 된다.
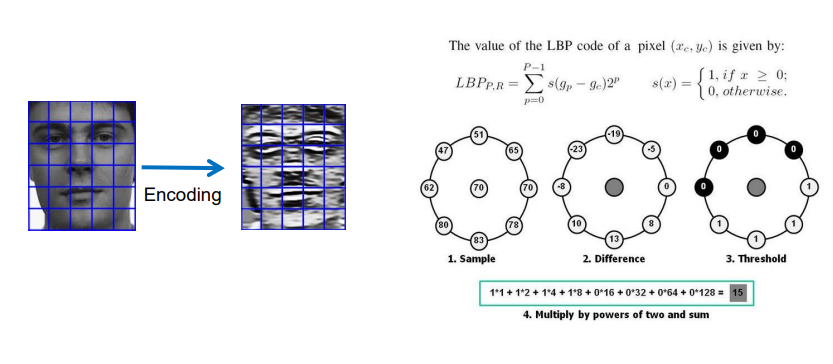
다음과 같이 이미지를 인코딩한 뒤, 센터 픽셀을 정해 해당 픽셀과의 비교값을 이용해 LBP Feature Map을 생성해준다.
- Sampling: 중심 픽셀 주변의 픽셀 값을 원형으로 추출
- Difference: 중심 픽셀 값과 주변 픽셀 값의 차이 구함
- Threshold: 차이값이 0이상이면 1, 0보다 작으면 0으로 반환
- Binary -> Decimal: 결과로 얻은 0,1 비트를 나열한 뒤 가중치를 곱해서 10진수로 변환
이렇게 구한 값들을 모아서 히스토그램을 만들어 보여주거나 분류기에 연결해 사용되기도 한다.
