들어가며
이전 글에서 이어집니다.
explain
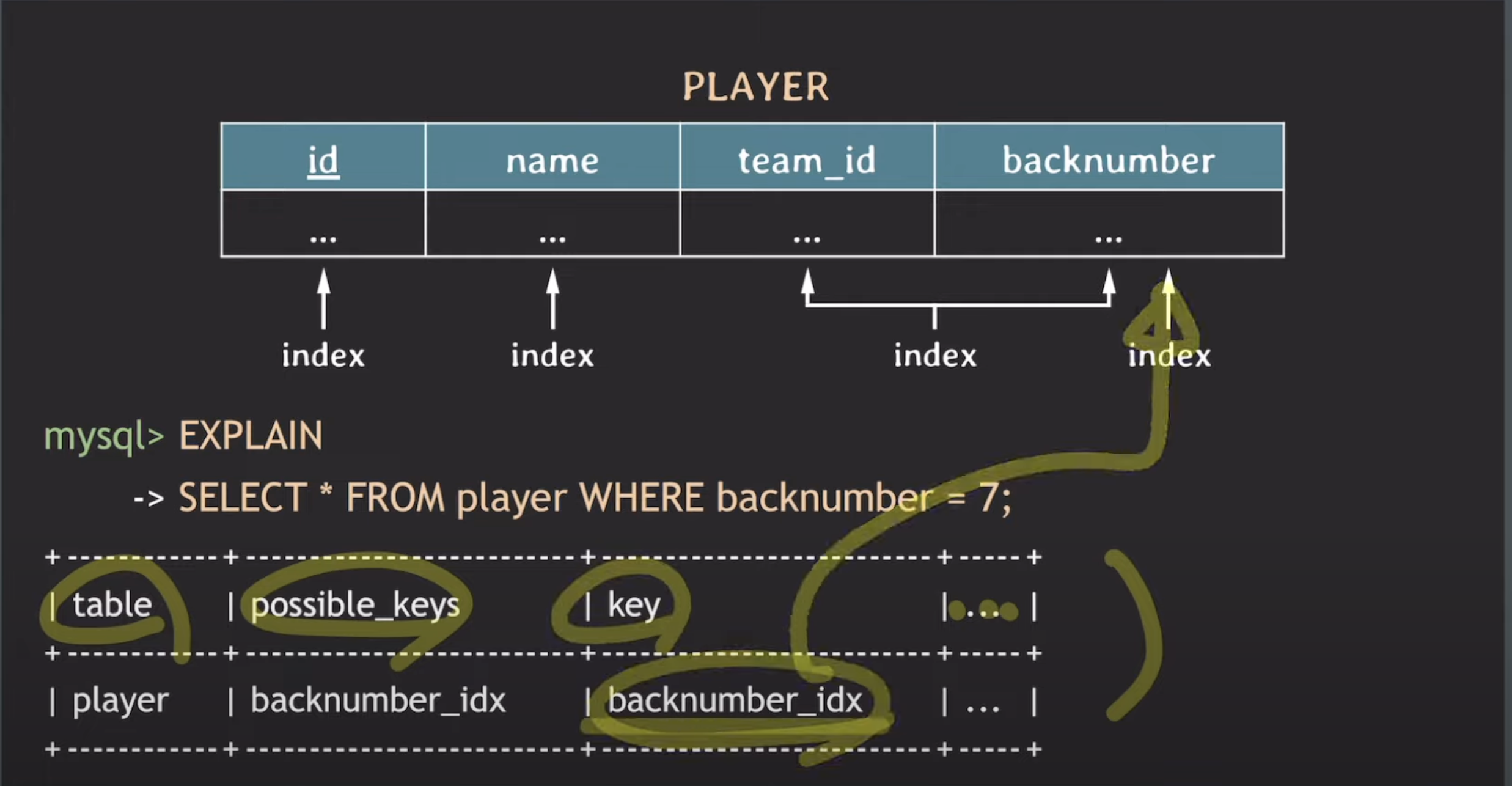
쿼리가 어떤 인덱스를 사용하는 지 확인합니다.
possible_keys: 사용 가능한 인덱스의 목록을 보여줍니다.
key: 실제로 사용한 인덱스를 나타냅니다.
USE INDEX
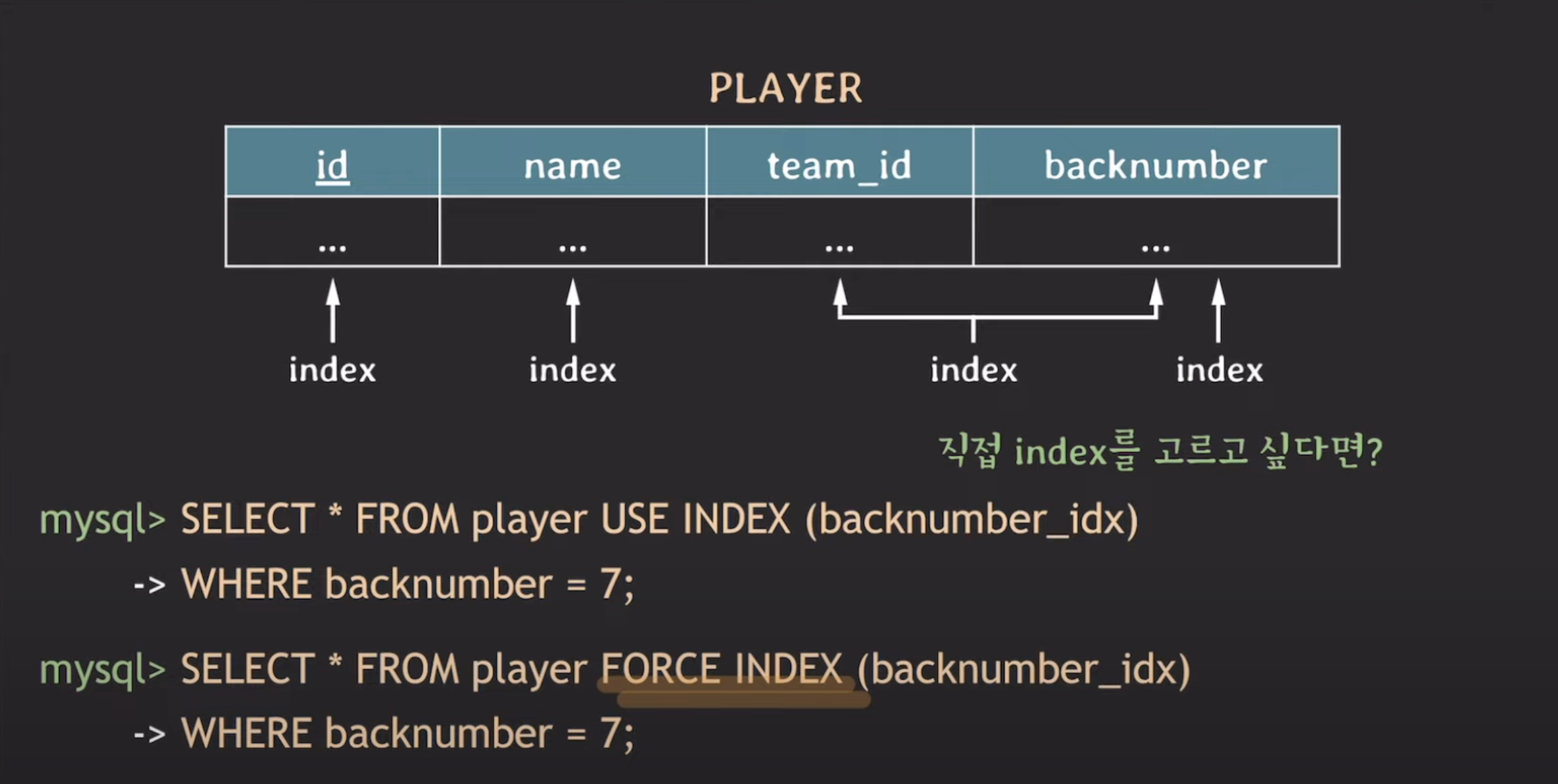
USE INDEX는 특정 인덱스를 사용하도록 명시하는 것을 의미합니다.
이는 일종의 권장사항으로, "이 인덱스를 사용해주세요"라는 느낌을 전달합니다.
하지만 옵티마이저가 USE INDEX로 명시한 인덱스를 사용하지 않는다면, FULL SCAN을 수행할 수 있습니다.
FORCE INDEX
FORCE INDEX는 인덱스를 강제로 사용하도록 지시합니다.
그러나 이러한 명시적인 지시에도 불구하고 옵티마이저가 해당 인덱스를 사용하지 않을 수 있으며, 이 경우 FULL SCAN이 발생할 수 있습니다.
대부분의 경우, 옵티마이저는 USE INDEX나 FORCE INDEX에 지정된 인덱스를 활용하려고 하지만, 특정 상황에서는 인덱스 사용이 어려운 경우도 있을 수 있습니다.
인덱스 많이 만들수록 좋은가?
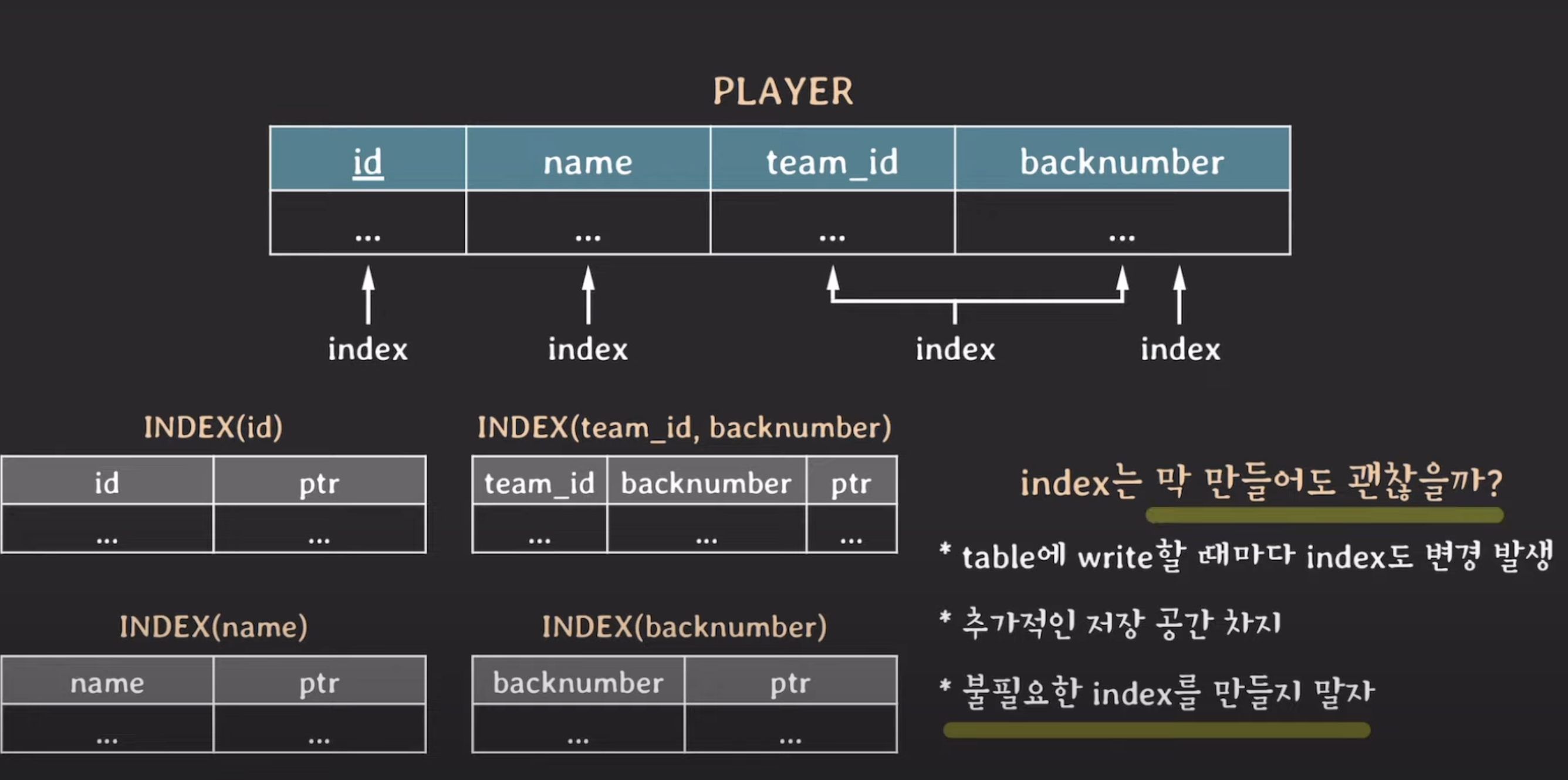
데이터베이스에서 인덱스는 데이터를 빠르게 검색하고 효율적으로 처리하기 위한 도구입니다. 그러나 인덱스를 많이 만들어 사용하는 것이 항상 좋은 것은 아닙니다. 오히려 불필요한 인덱스는 성능 저하와 저장 공간 낭비를 야기할 수 있습니다.
인덱스 단점
- table에 write(insert, update, delete) 할 때마다 index 변경으로 인한 오버헤드 발생
- 각각의 인덱스는 데이터베이스 내부에서도 저장 공간을 차지합니다. 따라서 많은 인덱스를 생성하면 데이터베이스의 전체 용량이 늘어나게 됩니다.
적절한 인덱스 사용의 중요성
-
필요한 검색 조건: 자주 사용되는 검색 조건에 대해서만 인덱스를 생성해야 합니다. 불필요한 인덱스는 오히려 성능 저하를 야기할 수 있습니다.
-
쓰기 작업 빈도: 테이블의 쓰기 작업이 빈번하다면 인덱스를 과도하게 많이 만들어서는 안 됩니다. 필요한 검색을 위한 최소한의 인덱스만 생성하는 것이 좋습니다.
-
복합 인덱스 사용: 여러 개의 열을 함께 고려해야 하는 검색 조건이 있다면, 이를 하나의 복합 인덱스로 만들어 사용하는 것이 효율적입니다.
-
테스트와 모니터링: 인덱스를 생성할 때마다 해당 쿼리의 실행 계획을 분석하고, 쿼리 성능을 모니터링하여 적절한 인덱스를 유지하도록 노력해야 합니다.
Covering index

커버링 인덱스는 데이터베이스에서 효율적인 쿼리 실행을 위한 기술 중 하나입니다. 이를 통해 데이터 검색 및 조회 성능을 개선할 수 있습니다.
특징
- 조회하는 attribute(s)를 index가 모두 cover 할 때
- 인덱스 자체만으로 쿼리 결과를 반환할 수 있음
- 조회 성능 향상
예시
예를 들어, (team_id, backnumber) 컬럼으로 구성된 인덱스 테이블이 있다고 가정해봅시다. 그리고 다음과 같은 쿼리를 실행한다고 가정하겠습니다.
SELECT tead_id, backnumber FROM player WHRER taem_id=5;이 쿼리는 team_id가 5인 선수들의 팀 ID와 백넘버를 가져오는 쿼리입니다. 이때 커버링 인덱스가 있다면 인덱스만으로도 쿼리 결과를 반환할 수 있습니다. 즉, 인덱스에서 조건에 맞는 값을 바로 가져와서 반환할 수 있기 때문에 데이터 테이블에 대한 접근이 필요하지 않습니다.
이로 인해 데이터 검색 성능이 향상되며, 특히 조회하는 컬럼이 많을수록 이점이 두드러집니다.
Hash Index
해시 인덱스는 해시 테이블을 사용하여 인덱스를 구현하는 방식입니다. 이는 특정 유형의 쿼리에 빠른 응답 시간을 제공하는데 유용합니다.
특징
- hash table을 사용해 index를 구현
- 시간 복잡도 O(1)의 성능
- rehashing에 대한 부담
- equality 비교만 가능, range 비교 불가능
- 복합 인덱스의 경우 전체 attributes에 대한 조회만 가능
- 반면 B-Tree 기반의 인덱스는 복합 인덱스 생성 시 컬럼의 접두사(Prefix)를 활용해 검색 가능
해시 인덱스는 주로 동등 비교에 사용되며, 특히 검색 결과를 빠르게 가져오는 경우에 활용됩니다. 그러나 해시 키 충돌이 발생할 경우 재해싱을 해야하는 단점이 있어 신중하게 사용해야 합니다.
그 외
- order by나 group by에도 index가 사용될 수 있다.
- fk에는 index가 자동으로 생성되지 않을 수 있다(join 관련) - mysql의 경우 fk 지정 후 table 생성 시 자동으로 생성
- 이미 데이터가 몇 백만 건 이상 있는 테이블에 인덱스를 생성하는 경우 시간이 몇 분 이상 소요될 수 있고 DB 성능에 안 좋은 영향을 줄 수 있다.
