들어가며
해당 강의를 보고 공부한 내용을 정리하였습니다.
이전 글에서는 Lock과 함께 2PL protocol을 살펴보았습니다.
해당 개념을 살펴보면서 데이터 전체 처리량에 대한 문제가 발생하였고 이를 해결하기 위해 MVCC를 사용하였다고 정리하였습니다.
이번 글에서는 MVCC에 대해 자세히 살펴보겠습니다.
MVCC 등장배경
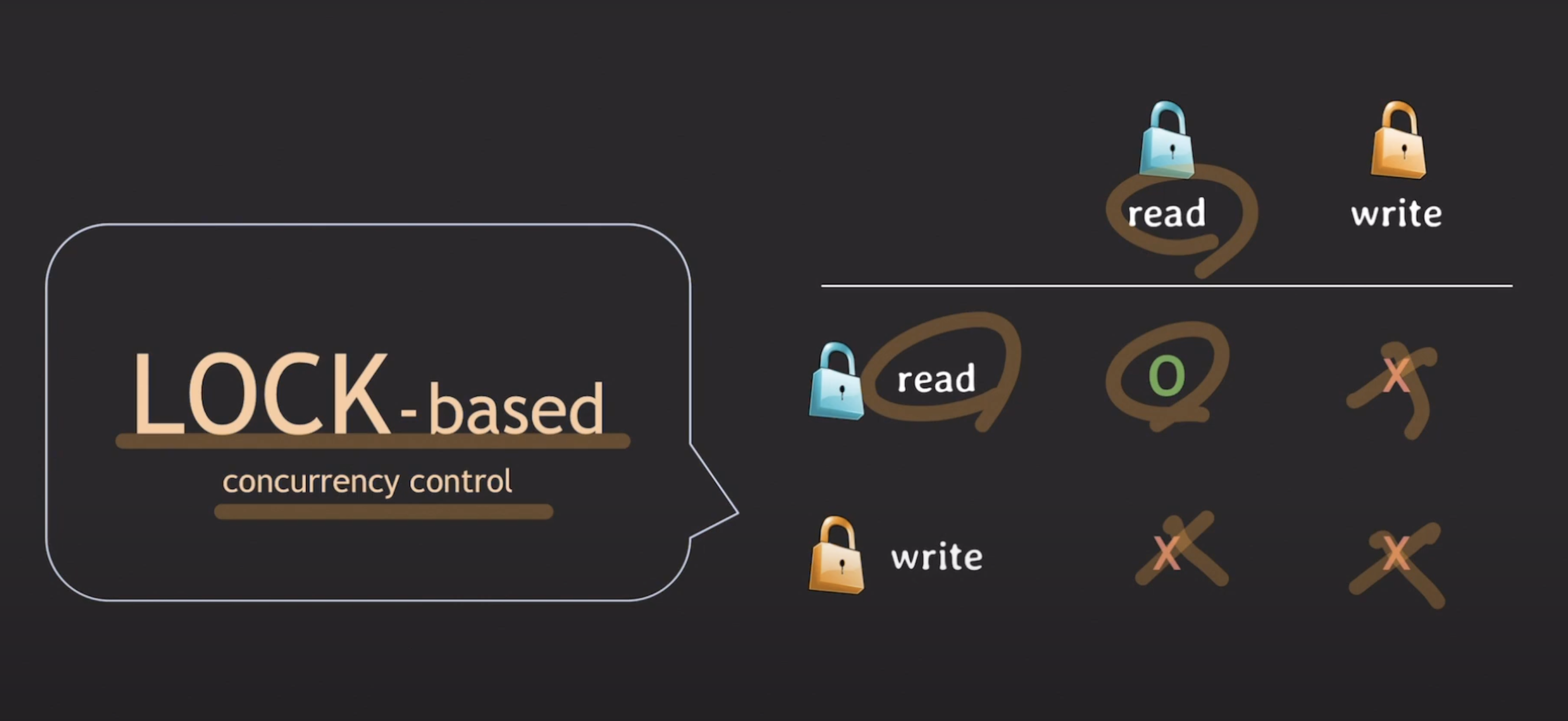
Lock-based 동시성 제어 방식은 동일한 데이터에 대해 읽기(read)와 쓰기(write)가 동시에 수행되면 한 작업이 실행되는 동안 다른 작업이 블록되어 전체 처리량이 저하되고 성능 문제가 발생할 수 있습니다.
이러한 문제를 해결하기 위해 MVCC(Multi-Version Concurrency Control) 기법이 등장했습니다.
MVCC
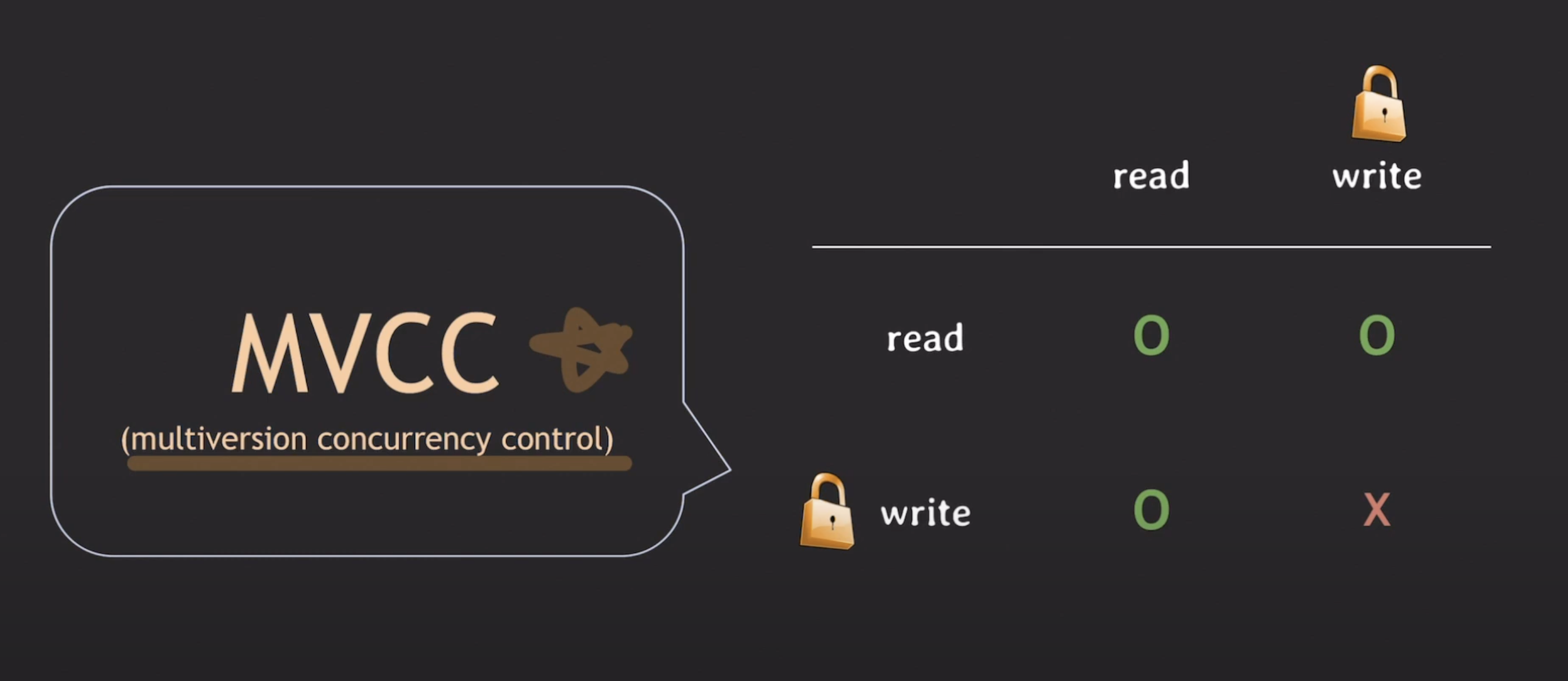
이번 글에서는 write 연산을 수행하기 위해 lock을 획득하는 과정을 생략하겠습니다.
write 연산을 수행했다는 것은 lock을 획득했다는 것으로 이해해주시면 됩니다.
또한 commit을 한 뒤 unlock 과정도 편의 상 생략하겠습니다.
-
MVCC는 데이터를 읽을 때 특정 시점 기준으로 가장 최근에 커밋된 데이터만 읽습니다. (mysql에서는 이를 consistent read라고 부릅니다.)
-
데이터 변화(write) 이력을 관리합니다. 그렇기 때문에 MVCC는 추가적인 저장공간을 많이 사용합니다.
-
read와 write는 서로 block하지 않기 때문에 Lock-based concurrency control에 비해 더 뛰어난 performance를 낼 수 있습니다.
-
오늘날의 RDBMS는 대부분 MVCC기반으로 동작합니다.
개념
MVCC는 동시 접근을 허용하는 데이터베이스에서 동시성을 제어하기 위해 사용하는 방법 중 하나입니다. MVCC 모델에서 데이터에 접근하는 사용자는 해당 시점에 데이터베이스의 snapshot을 읽습니다. 이 snapshot 데이터에 대한 변경이 완료될 때 (또는 트랜잭션이 완료될 때)까지 만들어진 변경사항은 다른 데이터베이스의 사용자가 볼 수 없습니다. 사용자가 데이터를 업데이트 하면 이전의 데이터를 덮어 씌우는 것이 아니라 새로운 버전의 데이터를 이전 버전의 데이터와 비교해서 변경된 내용을 UNDO에 생성합니다. 이러한 방식으로 하나의 데이터에 대해 여러 버전의 데이터가 존재하게 되고 사용자는 마지막 버전의 데이터를 읽게 됩니다.
이러한 방식은 lock을 사용하지 않기 때문에 RDBMS보다 빠르게 동작합니다. 또한 데이터를 읽을 때, 다른 사용자가 해당 데이터를 삭제, 수정해도 영향을 받지 않습니다. 데이터는 여러 버전으로 존재하기 때문에 주기적으로 데이터를 정리해야 합니다. MVCC 모델은 하나의 데이터에 대한 여러 버전의 데이터를 허용하기 때문에 데이터 버전이 충돌될 수 있으므로 애플리케이션 영역에서 이러한 문제를 해결해야 합니다. 또한 UNDO 블록 I/O, CR Copy 생성, CR 블록 캐싱 같은 부가적인 작업의 오버헤드가 발생합니다.
read committed
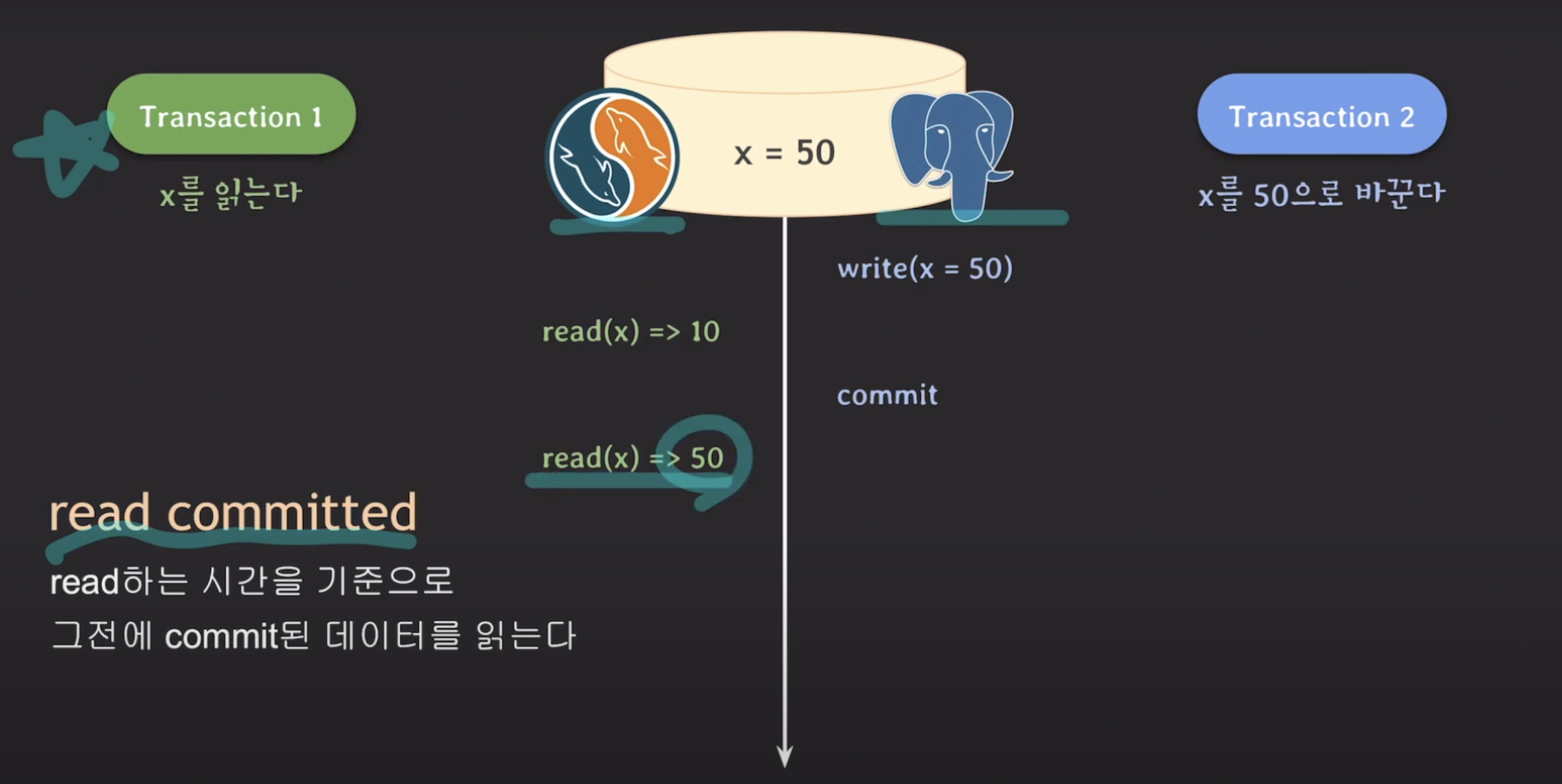
데이터를 읽을 때 읽는 시점을 기준으로 그 이전에 커밋된 데이터만 읽습니다.
repetable read
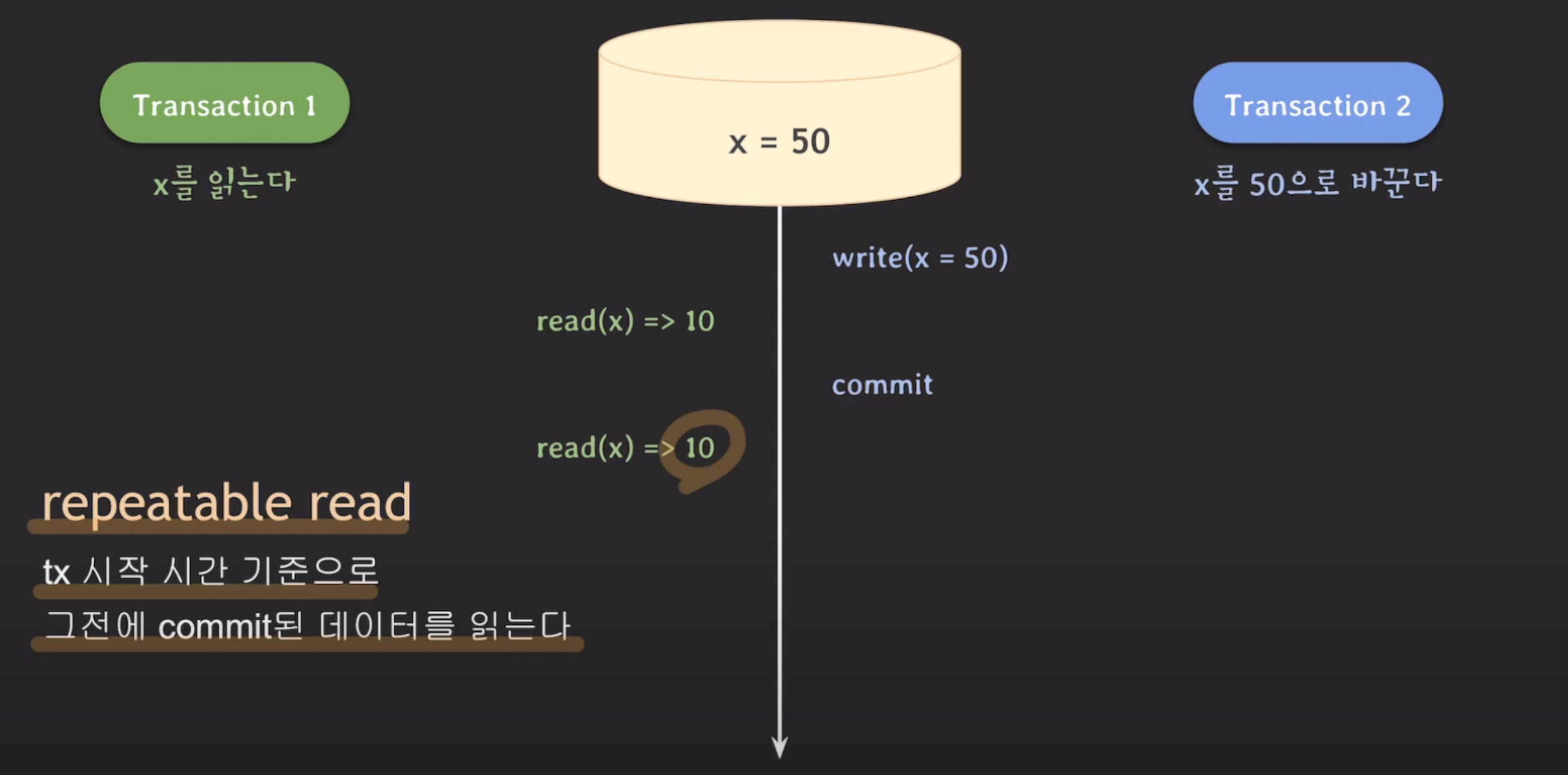
트랜잭션 시작 시간 기준(해당 기준은 RDBMS마다 다를 수 있습니다)으로 그전에 commit된 데이터를 읽습니다.
read uncommitted
MVCC는 committed된 데이터를 읽기 때문에 Read Uncommitted 레벨에서는 일반적으로 MVCC가 적용되지 않습니다. MySQL은 Read Committed부터 MVCC가 적용되며, PostgreSQL은 Read Uncommitted 레벨이지만 Read Committed처럼 동작합니다.
postgreSQL에서 lost update 문제
lost update 문제
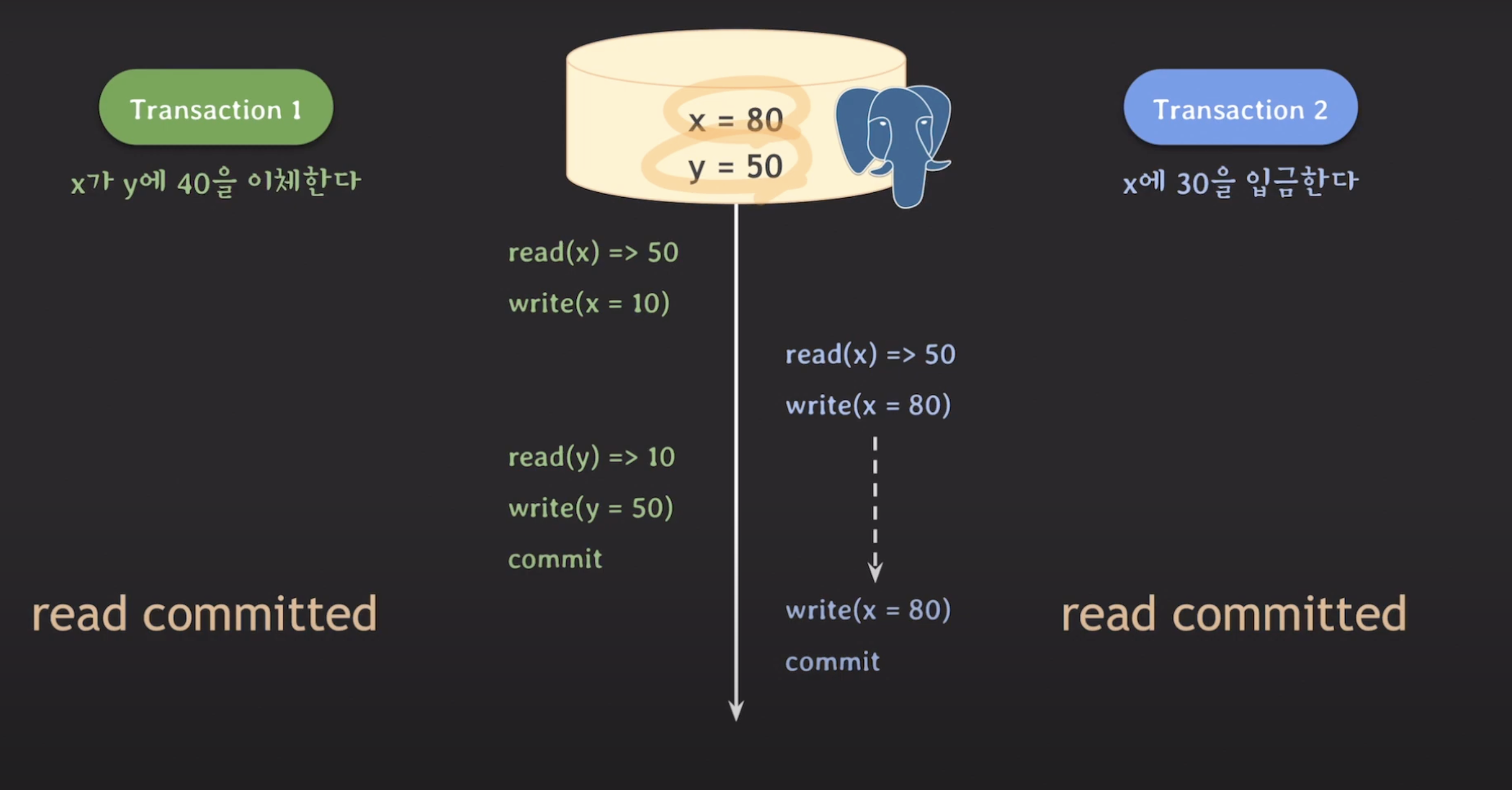
PostgreSQL은 MVCC(Multi-Version Concurrency Control) 기반으로 동작하여 동시성 문제를 해결하고 데이터 일관성을 유지합니다. 하지만 MVCC를 사용하더라도, 어떤 상황에서는 "Lost Update"라는 문제가 발생할 수 있습니다.
예를 들어, 두 개의 트랜잭션 A와 B가 동시에 수행되는 상황에서 발생하는 문제를 살펴보겠습니다. 두 트랜잭션 모두 Read Committed 레벨의 isolation을 가지고 있습니다.
예시
-
트랜잭션 A는 먼저 x의 값을 읽어오고, 해당 데이터에 Write Lock을 획득한 뒤 x의 값을 40만큼 감소시킵니다. 이때, MVCC에 따라 변경된 데이터는 추가적인 저장 공간에 보관되며 DB에 바로 반영되지 않습니다.
-
트랜잭션 B는 이어서 x의 값을 읽습니다. 트랜잭션 A가 작업한 결과는 아직 DB에 반영되지 않았기 때문에, 50을 읽습니다.
-
트랜잭션 B는 x에 30을 더하려고 시도하지만, 트랜잭션 A가 이미 x에 대한 Write Lock을 획득한 상태이기 때문에 Lock을 해제할 때까지 대기하게 됩니다.
-
이후 트랜잭션 A는 y의 값을 읽은 뒤 y 값에 40 증가시킵니다.
-
트랜잭션 A가 커밋됩니다 이때 y의 값도 DB에 반영됩니다.
-
트랜잭션 B가 x에 대한 Write Lock을 획득하고 x의 값을 30 증가시키고 커밋합니다. 이때도 x의 값을 추가적인 저장 공간에서 갱신 한 뒤 커밋 이후 DB에 반영됩니다.
이렇게 되면 최종적으로 DB에는 x=80, y=50인 결과가 반영되어, 잘못된 결과가 발생하게 됩니다.
이러한 상황을 "Lost Update" 문제라고 합니다.
postgreSQL에서 lost update 문제 해결
PostgreSQL에서는 lost update 문제를 해결하기 위해 여러 가지 방법을 제공하고 있습니다. 이 예시에서는 isolation level 조정을 통한 해결 방법을 다루겠습니다.
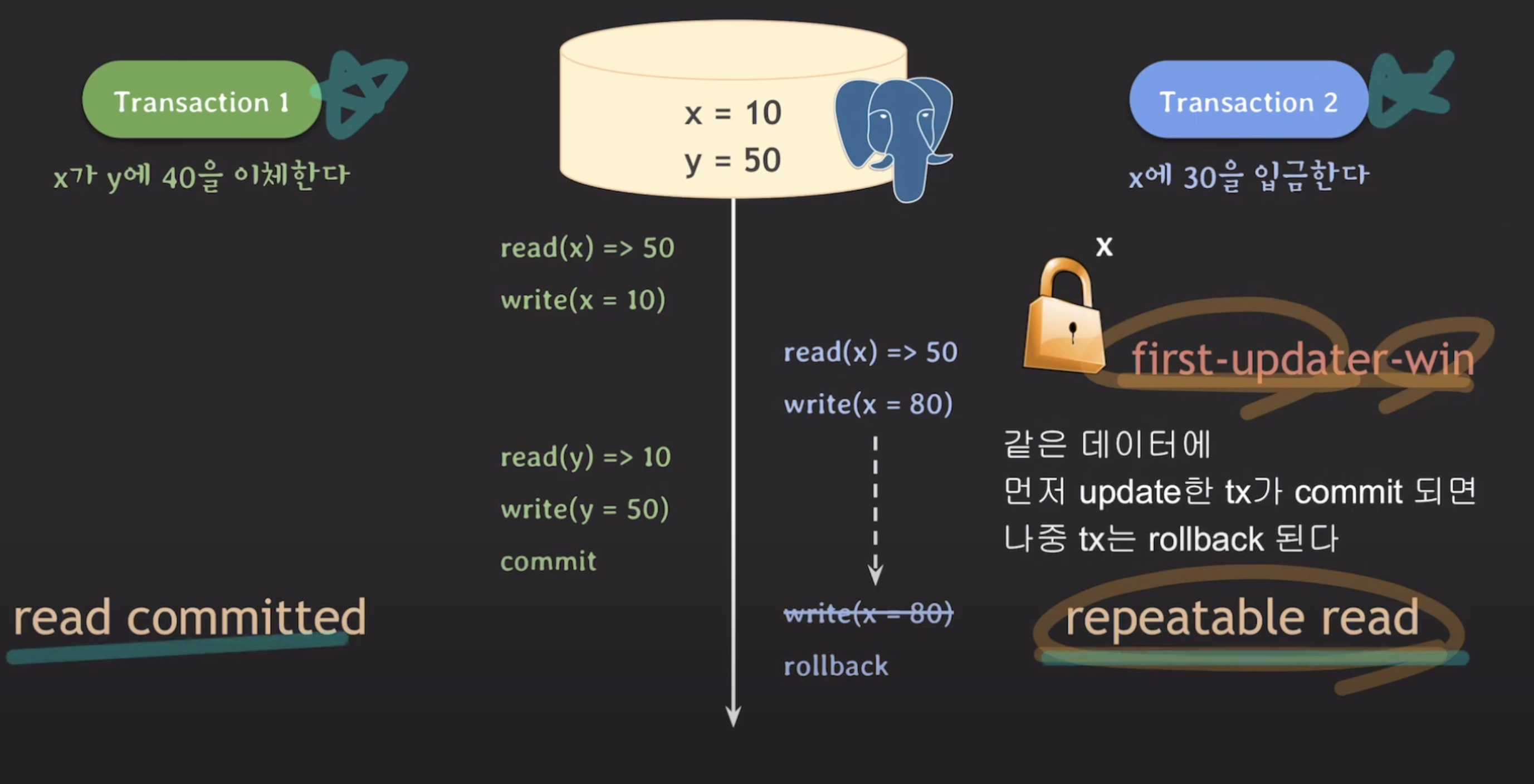
먼저, 예시에서는 트랜잭션 B의 isolation level을 Read Committed에서 Repeatable Read로 수정하여 문제를 해결하려고 시도했습니다.
Repeatable Read 레벨에서 트랜잭션 B가 x에 대한 Write 작업을 시도하면, 이미 해당 데이터를 수정한 다른 트랜잭션이 커밋되었기 때문에 트랜잭션 B는 롤백됩니다. 이는 "first-updater-win" 규칙에 따른 것입니다.
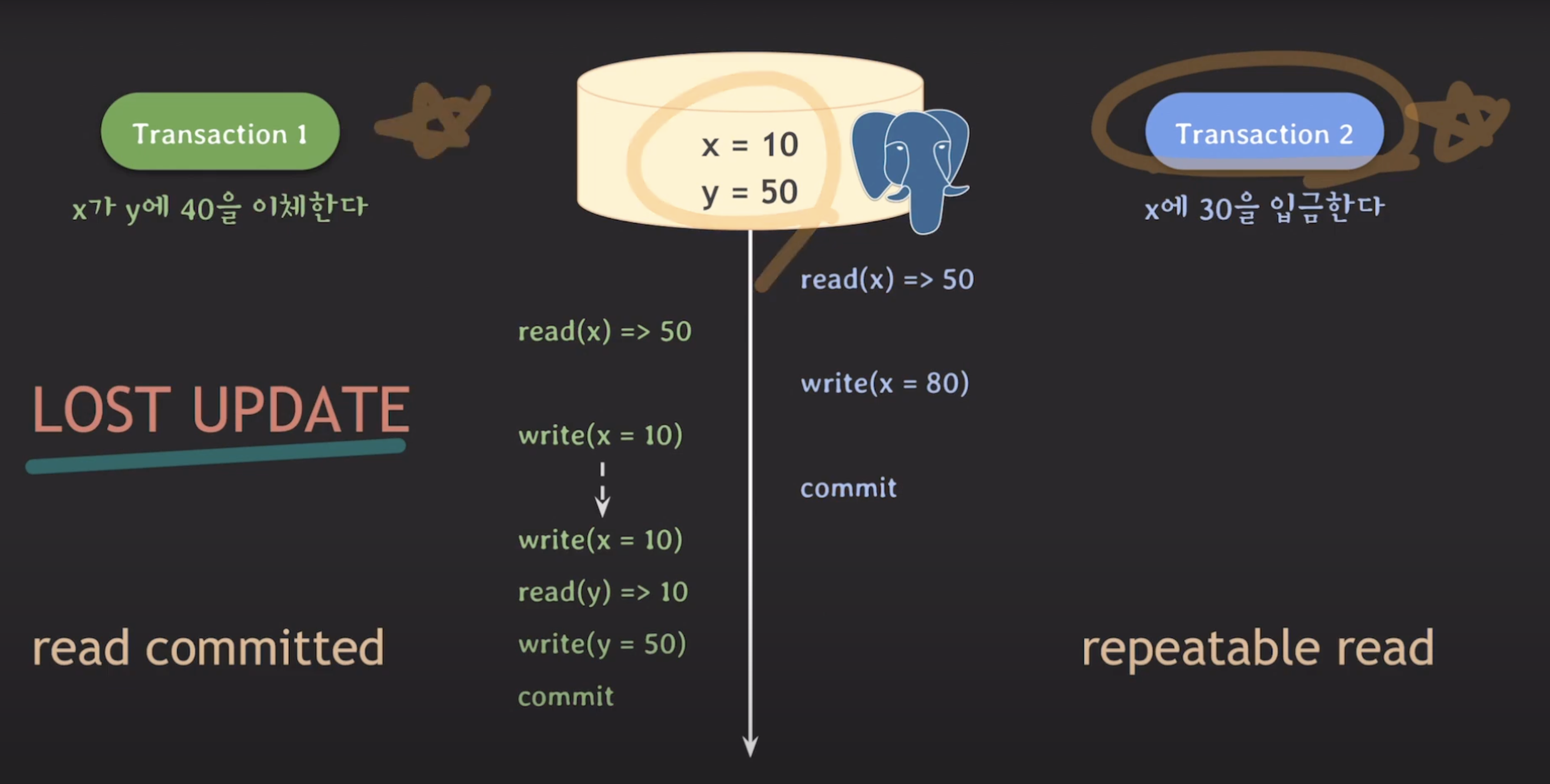
하지만 이 방법만으로는 문제를 완전히 해결하기 어려울 수 있습니다. 왜냐하면 Transaction A와 Transaction B는 서로 다른 isolation level을 가지므로, Transaction A가 Read Committed 레벨일 때 문제가 발생할 수 있습니다.
Transaction B가 먼저 실행되고 그 후에 Transaction A가 실행될 때도 "Lost Update" 문제가 발생할 수 있습니다.

따라서 "Lost Update" 문제를 해결하려면 단순히 하나의 트랜잭션의 isolation level만 조정하는 것이 아니라, 연관된 모든 트랜잭션의 isolation level을 적절히 설정해야 합니다. 모든 연관 트랜잭션이 같은 isolation level을 가지도록 조정함으로써 문제를 완전히 해결할 수 있습니다.
MySQL에서의 lost update 문제
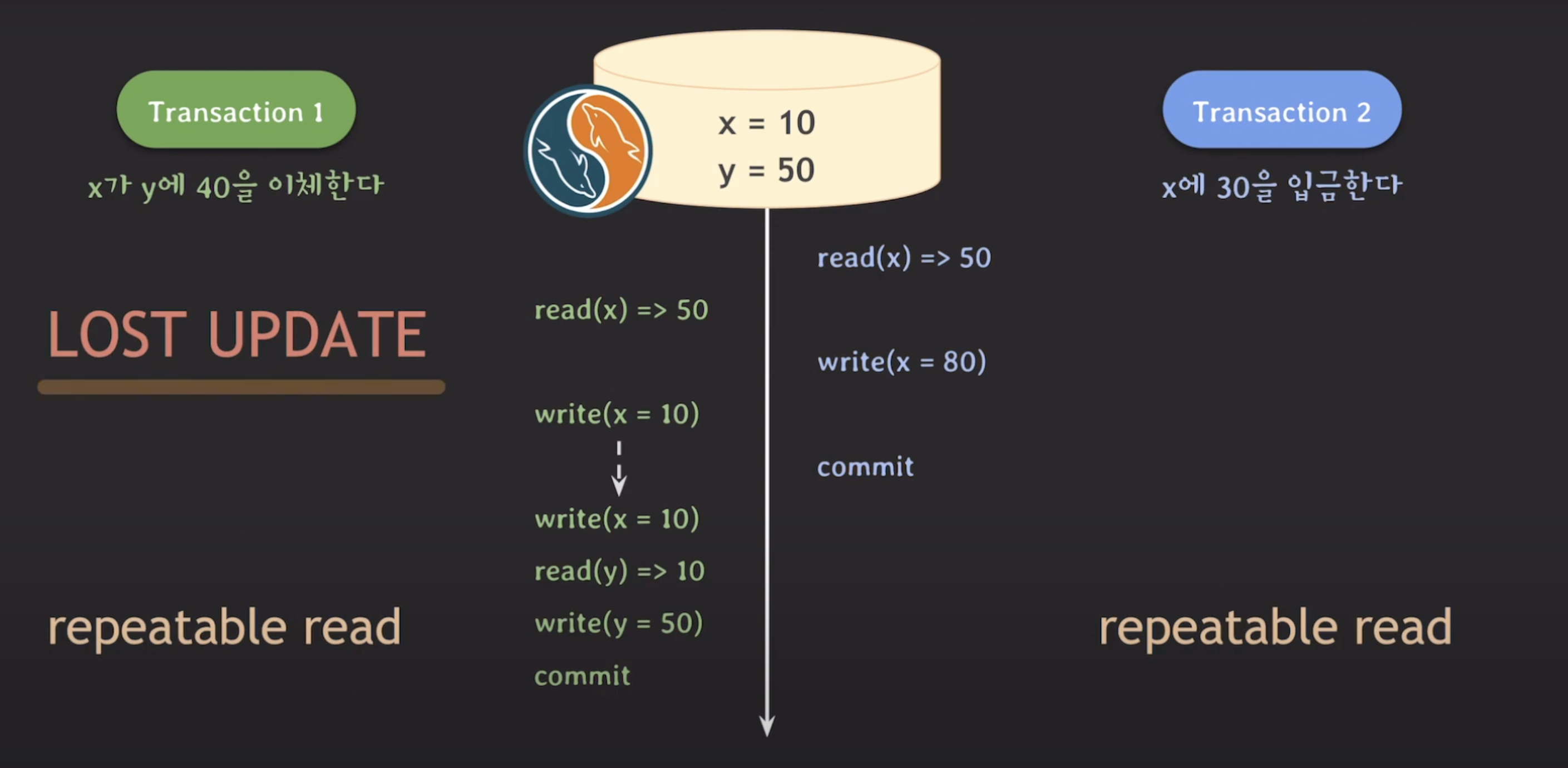
MySQL에서는 앞서 살펴본 PostgreSQL과 유사한 "Lost Update" 문제의 해결방안이 적용되지 않습니다.
트랜잭션 A와 B가 모두 Repeatable Read isolation level을 가지고 있을 때, 여전히 lost update 문제가 발생합니다.
MySQL의 Repeatable Read 레벨에서 트랜잭션 B가 x에 대한 Write 작업을 수정하려고 시도하면 롤백이 발생하지 않고 작업이 계속 진행됩니다. 이로 인해 트랜잭션 B의 작업이 무시되고, 최종 결과에 여전히 "Lost Update" 문제가 남을 수 있습니다.
다음 글에서 MySQL에서 해결방안에 대해 살펴보겠습니다.
