들어가며
이전 글에서 이어집니다.
이번 글에서는 MySQL에서 어떻게 lost update를 해결할 수 있는 지 살펴보겠습니다.
MySQL에서 lost update 문제 해결
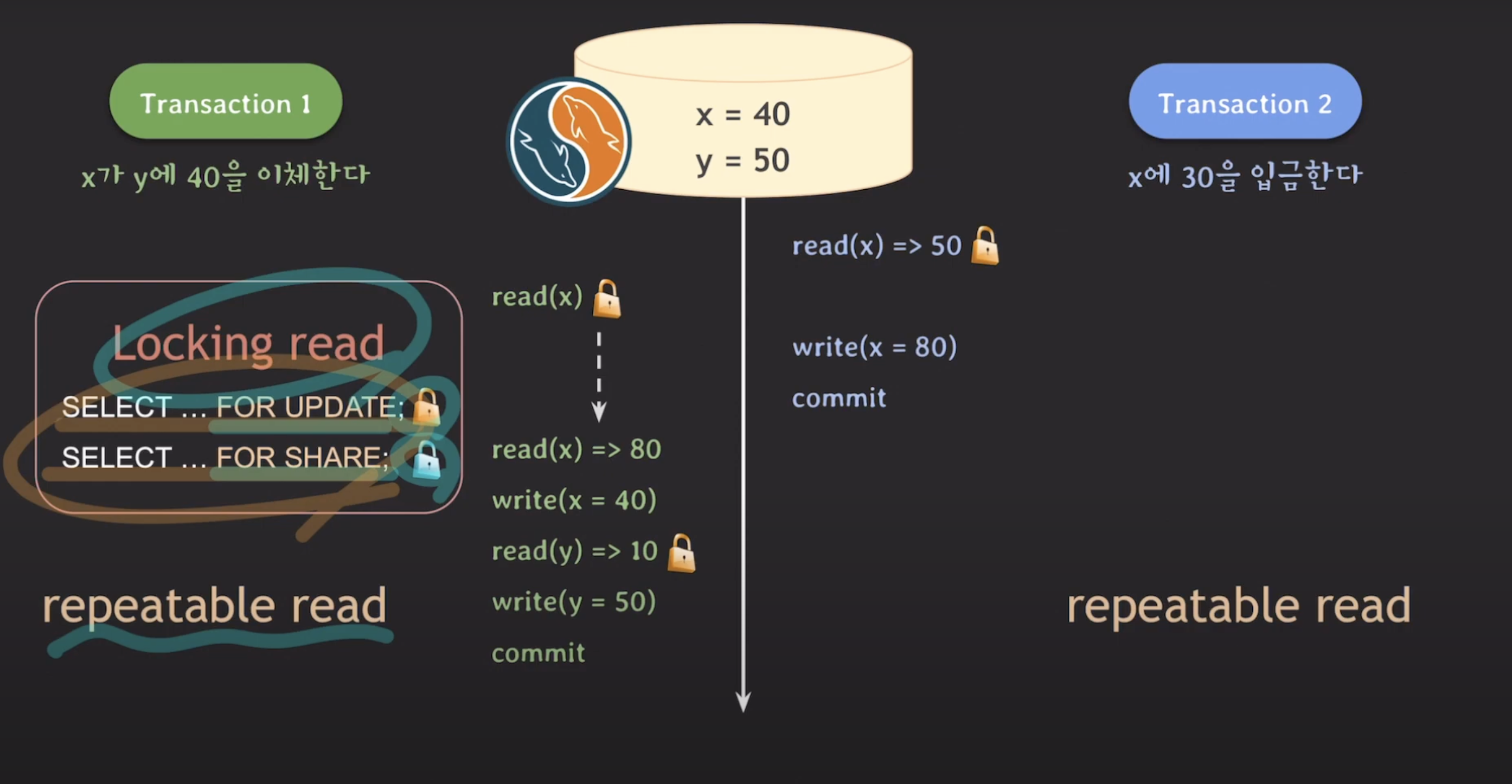
MySQL에서 Lost Update 문제를 해결하기 위해서는 Repeatable Read isolation level만으로는 해결하기 어려울 수 있습니다. 이런 경우 Locking Read를 사용하여 문제를 해결해야 합니다.
Locking Read는 DBMS가 자동으로 처리해주는 것이 아니기 때문에 개발자가 직접 사용하는 기법입니다.
MySQL에서 Locking Read가 동작을 할 때는 가장 최근에 커밋된 데이터를 읽습니다.
예시
-
트랜잭션 A가 x를 조회하기 위해 SELECT ... FOR UPDATE를 실행하여
Locking Read를 획득합니다. -
트랜잭션 B가 동시에 x를 조회하기 위해 SELECT ... FOR UPDATE를 실행하려고 시도합니다. 하지만 트랜잭션 A가 이미 Lock을 획득한 상태이므로 트랜잭션 B는 대기 상태에 들어갑니다.
-
트랜잭션 A는 x의 값을 수정하고 작업을 마치기 전에 Commit합니다. 이때 Exclusive Lock이 해제되고, x의 값은 실제 데이터베이스에 반영됩니다.
-
트랜잭션 B가 Exclusive Lock을 획득합니다. 트랜잭션 B는 x의 값을 조회합니다.
-
트랜잭션 B는 x의 값을 수정한 뒤, y의 값을 읽기 위해
Locking Read를 획득합니다. -
트랜잭션 B는 y의 값을 읽은 두, y의 값을 수정하고 commit합니다. 이때 Exclusive Lock이 해제되고, x,y 값은 실제 데이터베이스에 반영됩니다.
Locking Read
-
SELECT ... FOR UPDATE: Exclusive Lock을 사용합니다. 특정 데이터에 대한 쓰기 작업을 수행하기 위해 Lock을 획득하는 방법입니다. 이로써 다른 트랜잭션들은 해당 데이터에 대한 수정 작업을 대기하게 됩니다.
-
SELECT ... FOR SHARE: Shared Lock을 사용합니다. 데이터를 읽어올 때 Lock을 획득하며, 이는 다른 트랜잭션들도 동일한 데이터에 대한 Lock을 획득할 수 있음을 의미합니다. 다른 트랜잭션들도 읽기 작업은 가능하지만 쓰기 작업은 대기해야 합니다.
MySQL repeatable read에서 write skew 문제
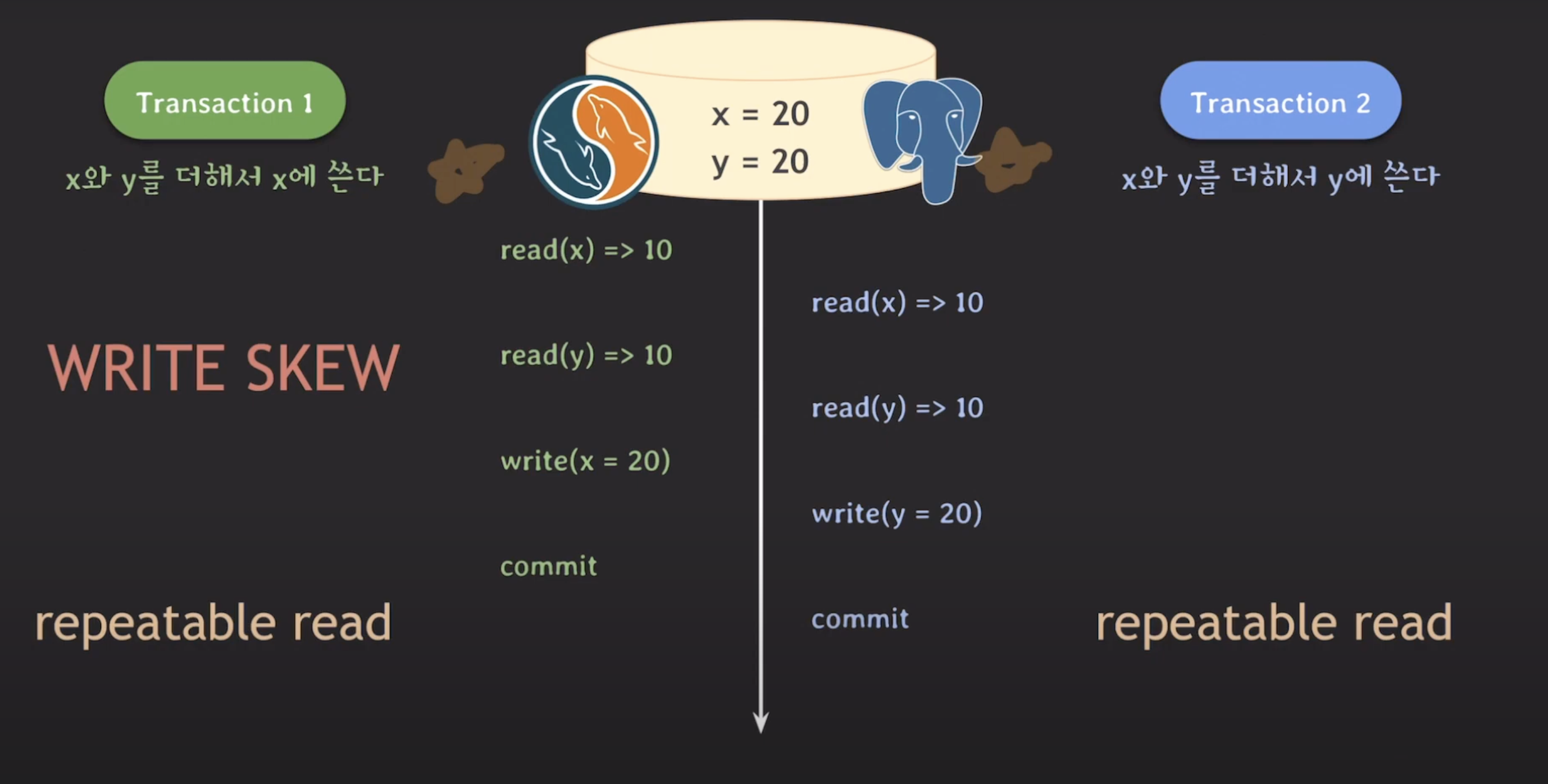
문제 해결

예시
- 트랜잭션 A가 x의 값을 읽기 위해 locking read(exclusive lock)를 획득합니다.
- 트랜잭션 B가 x의 값을 읽기 위해 locking read(exclusive lock)를 획득하려 시도하지만 트랜잭션 A가 이미 Lock을 획득한 상태이므로 트랜잭션 B는 대기 상태에 들어갑니다.
- 트랜잭션가 y의 값을 읽기 위해 locking read(exclusive lock)를 획득하고 x의 값을 갱신 한 뒤 커밋합니다. 커밋 이후 DB에 x 값이 반영됩니다.
- 트랜잭션 B가 x의 값을 읽기 위해 locking read(exclusive lock)를 획득합니다.
- x의 값을 읽습니다. 이때 MySQL에서
Locking Read가 동작을 할 때는 가장 최근에 커밋된 데이터를 읽기 때문에 isolation level이 repeatable read 일지라도 가장 최근에 커밋된 데이터 값을 읽었으므로 x의 값은 20이 됩니다. - 트랜잭션 B가 y의 값을 읽기 위해 locking read(exclusive lock)를 획득하고 y의 값을 갱신 한 뒤 커밋합니다. 커밋 이후 DB에 y 값이 반영됩니다..
MySQL의 repeatable read isolation level에서 write skew 문제를 해결하기 위해 locking read를 사용해 해결 할 수 있습니다.
postgreSQL repeatable read에서 write skew 문제
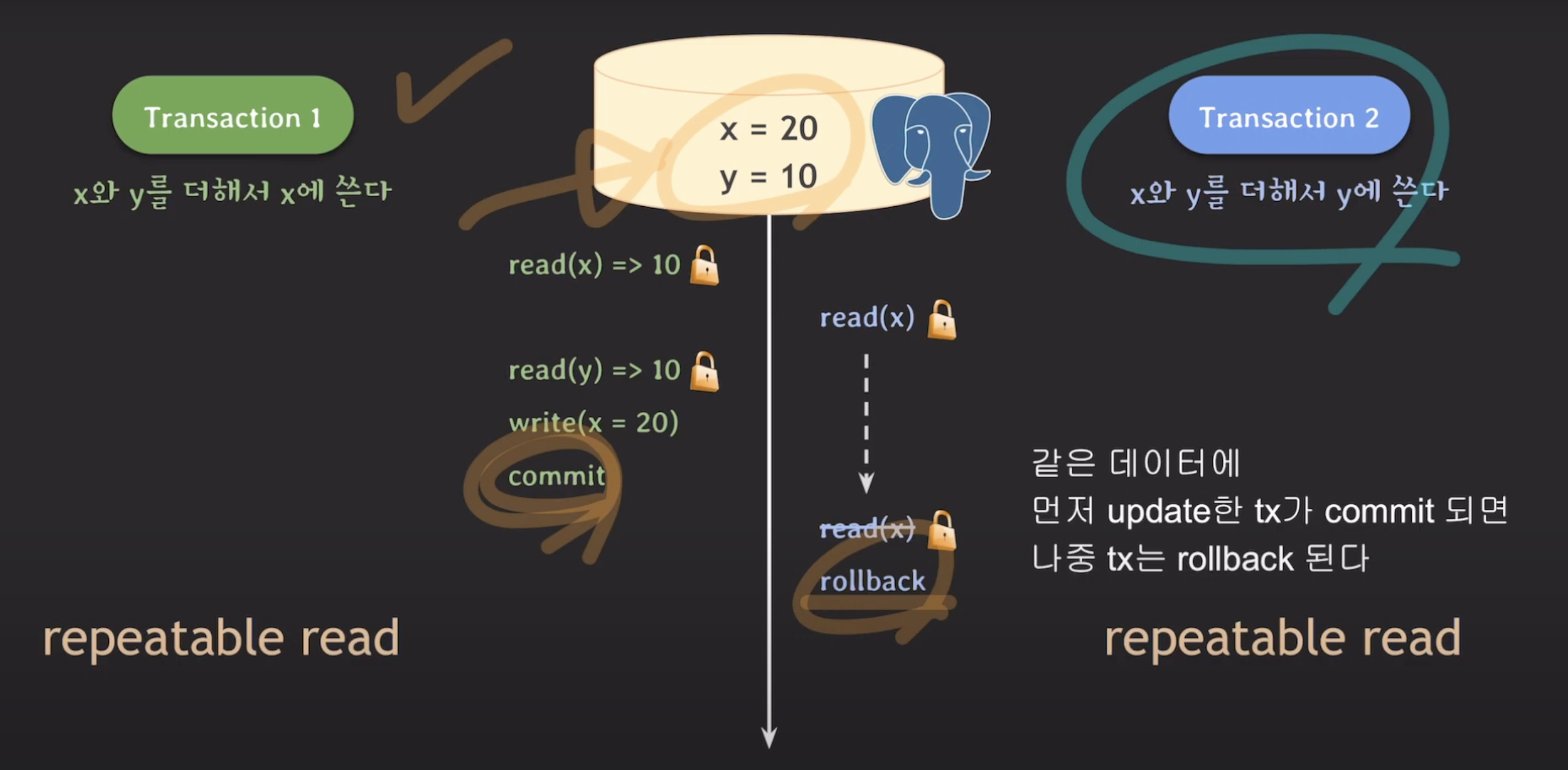
postgreSQL에서도 Locking Read를 통해 write skew 문제를 해결할 수 있습니다.
하지만, 앞서 살펴본 MySQL에서의 Locking Read를 통해 write skew 문제를 해결하는 방식과는 다르게 동작합니다.
postgreSQL에서는 트랜잭션 B가 트랜잭션 A의 작업이 완료된 후 lock을 획득하여 x의 값을 읽을 때 rollback이 발생합니다.
왜냐하면 postgreSQL에서는 repeatable read level일 때 같은 데이터에 대해서 먼저 update한 트랜잭션이 commit 되면 나중 트랜잭션이 롤백되기 때문입니다.
serializable (두 RDBMS의 차이)
Serializable 격리 수준은 데이터베이스 시스템에서 가장 높은 격리 수준으로, 동시에 여러 트랜잭션이 실행되더라도 마치 순차적으로 실행되는 것처럼 보이도록 보장합니다. 하지만 MySQL과 PostgreSQL에서 Serializable 격리 수준을 구현하는 방식과 차이가 있습니다.
MySQL

MySQL의 Serializable 격리 수준은 Repeatable Read와 유사한 방식으로 동작합니다. 다만, 모든 평범한 SELECT 문이 암묵적으로 SELECT ... FOR SHARE와 같이 동작하게 됩니다.
이는 모든 SELECT 문이 공유 락을 획득하여 다른 트랜잭션이 해당 데이터에 대한 쓰기 작업을 하지 못하도록 하는 것을 의미합니다.
따라서 MySQL의 Serializable 격리 수준은 데이터베이스에서 가장 높은 격리 수준을 제공하며, 데이터의 일관성과 무결성을 보장합니다.
postgreSQL
PostgreSQL의 Serializable 격리 수준은 Serializable Snapshot Isolation (SSI)라는 방식으로 구현됩니다.
이를 위해 First-Committer-Winner라는 원칙을 따릅니다. 즉, 여러 트랜잭션 중 가장 먼저 커밋된 트랜잭션을 우선으로 처리하고, 나머지 트랜잭션은 롤백되는 방식으로 동작합니다.
