Redis Sorted Set을 이용한 랭킹 시스템 구현
들어가며
이전 팀에서는 자체적으로 정의한 인플루언서 영향력 산정 수식을 기반으로, 인스타그램 채널 테이블에 Reels Score와 Feed Score를 계산해 관리하고 있었습니다.
해당 점수를 기준으로 유저에게 인플루언서의 순위를 제공하고, 특정 랭킹 값을 조건으로 검색할 수 있는 기능도 함께 제공했습니다.
초기에는 Virtual Column을 활용해 Reels Score 또는 Feed Score를 기준으로 실시간 순위를 계산하는 방식으로 구현했으나, 데이터가 증가함에 따라 Virtual Column 계산에 필요한 CPU 연산 비용이 급격히 증가했고, 이로 인해 DB에 과부하가 발생하여 시스템의 확장성과 성능에 한계가 드러났습니다.
이러한 문제를 해결하기 위해, Redis의 Sorted Set 자료구조를 활용한 랭킹 시스템을 도입했습니다. Redis Sorted Set은 점수를 기준으로 유저를 정렬하고, 빠르게 순위를 조회하거나 범위를 필터링할 수 있어 랭킹 시스템 구현에 적합하다고 판단했습니다.
Redis Sorted Set
Redis Sorted Set은 각 원소에 점수(score)를 부여하여 점수를 기준으로 자동으로 정렬되는 자료구조입니다. 하나의 Sorted Set 안에서 고유한 멤버들과 해당 멤버의 점수를 함께 저장하며, 점수를 기준으로 정렬된 상태로 데이터가 유지된다는 특징이 있습니다.
Sorted Set은 다음과 같은 명령어들을 통해 효율적인 랭킹 시스템 구현을 가능하게 합니다:
-
ZADD: 점수와 함께 멤버 추가 (또는 갱신)
-
ZRANK: 멤버의 순위 조회
-
ZREVRANGE: 점수를 기준으로 내림차순 정렬된 상위 N개 조회
-
ZCOUNT, ZRANGEBYSCORE: 특정 점수 범위에 해당하는 멤버 조회
Redis Sorted Set은 내부적으로 skip list와 hash table을 함께 사용하여 점수 기반 정렬과 빠른 조회/삽입을 동시에 만족시킵니다.
대부분의 연산이 로그 시간 (O(log N))에 수행되므로, 수십만 ~ 수백만 건의 데이터가 있어도 고성능을 유지할 수 있습니다.
랭킹 시스템 설계에 앞서 고민했던 점
Redis의 Sorted Set을 활용하여 랭킹 시스템을 구현하기로 하였습니다. 설계에 앞서 몇 가지 중요한 사항들을 먼저 고려했습니다.
1. 랭킹 정보를 DB(HDD)에 별도로 저장해야 하는가?
가장 먼저 고민한 부분은 Redis가 in-memory 기반의 데이터베이스라는 점이었습니다. 즉, Redis 인스턴스가 다운되거나 장애가 발생하면, 메모리에 있던 데이터는 소실될 수 있다는 특성이 있습니다.
물론 Redis는 RDB snapshot이나 AOF(Append Only File) 같은 영속성 옵션을 통해 데이터를 복구할 수 있는 장치들을 제공하지만, 본 설계에서는 이러한 복구 메커니즘은 고려 대상에서 제외하고, Redis에 저장된 랭킹 데이터가 소실될 경우, 서비스에 치명적인 장애가 발생하는가?라는 관점에서 판단했습니다.
해당 랭킹 기능은 광고주에게 제공하는 부가적인 기능으로, 핵심 서비스에는 큰 영향을 주지 않는 요소였기 때문에, 데이터 소실 시에도 치명적인 장애로 간주되지는 않았습니다.
그럼에도 불구하고, 저는 랭킹 데이터를 RDB에도 함께 저장하기로 결정했습니다.
그 이유는?
가장 큰 이유는 개발 편의성 때문이었습니다.
랭킹을 기준으로 정렬하거나, 특정 랭킹 범위에 해당하는 인플루언서 채널을 필터링하는 등 다양한 기능 요구사항이 존재했습니다. 이러한 기능들을 Redis만으로 구현할 수도 있었지만, 실제 비즈니스 로직 구현과 쿼리 작성에서의 효율성을 고려했을 때, 인스타그램 채널 테이블에 랭킹 값을 저장해두는 것이 훨씬 단순하고 직관적인 개발이 가능하다고 판단했습니다.
따라서, 랭킹 데이터는 Redis를 통해 실시간으로 관리하고, 실제 랭킹 값은 주기적으로 RDB에 동기화하여 저장하는 방식으로 설계했습니다.
2. 랭킹을 실시간으로 보여줘야하는가?
랭킹을 실시간으로 제공해야 한다면, 랭킹 데이터를 DB에 직접 저장하는 것은 성능 측면에서 큰 부담이 될 수 있습니다.
예를 들어, 인플루언서 채널이 새롭게 추가되거나 삭제될 때마다 전체 랭킹을 재계산하여 DB에 반영해야 하고, 이 과정에서 대량의 업데이트 연산이 발생합니다.
이러한 업데이트가 자주 발생하거나, 동시에 다른 API 요청에서 인플루언서 채널 데이터를 수정하고자 할 경우, 락 대기 등의 현상이 발생해 시스템의 응답성과 안정성에 악영향을 줄 수 있습니다.
하지만, 저희 서비스에서는 랭킹을 실시간으로 보여줄 필요가 없었고, 하루 단위(1일 랭킹) 로 제공하는 방식이었기 때문에, 랭킹 데이터를 RDB에 저장하더라도 성능에 큰 무리가 없다고 판단했습니다.
따라서, 다음과 같은 방식으로 구현했습니다:
-
배치 서버에서 하루에 한 번, 사용자가 적은 시간대에 랭킹 데이터를 DB에 업데이트하는 배치 작업을 수행하고,
-
인플루언서 채널이 추가되거나 삭제될 때는 우선적으로 Redis의 Sorted Set에만 랭킹 정보를 반영하도록 구현하였습니다.
랭킹 시스템 구현
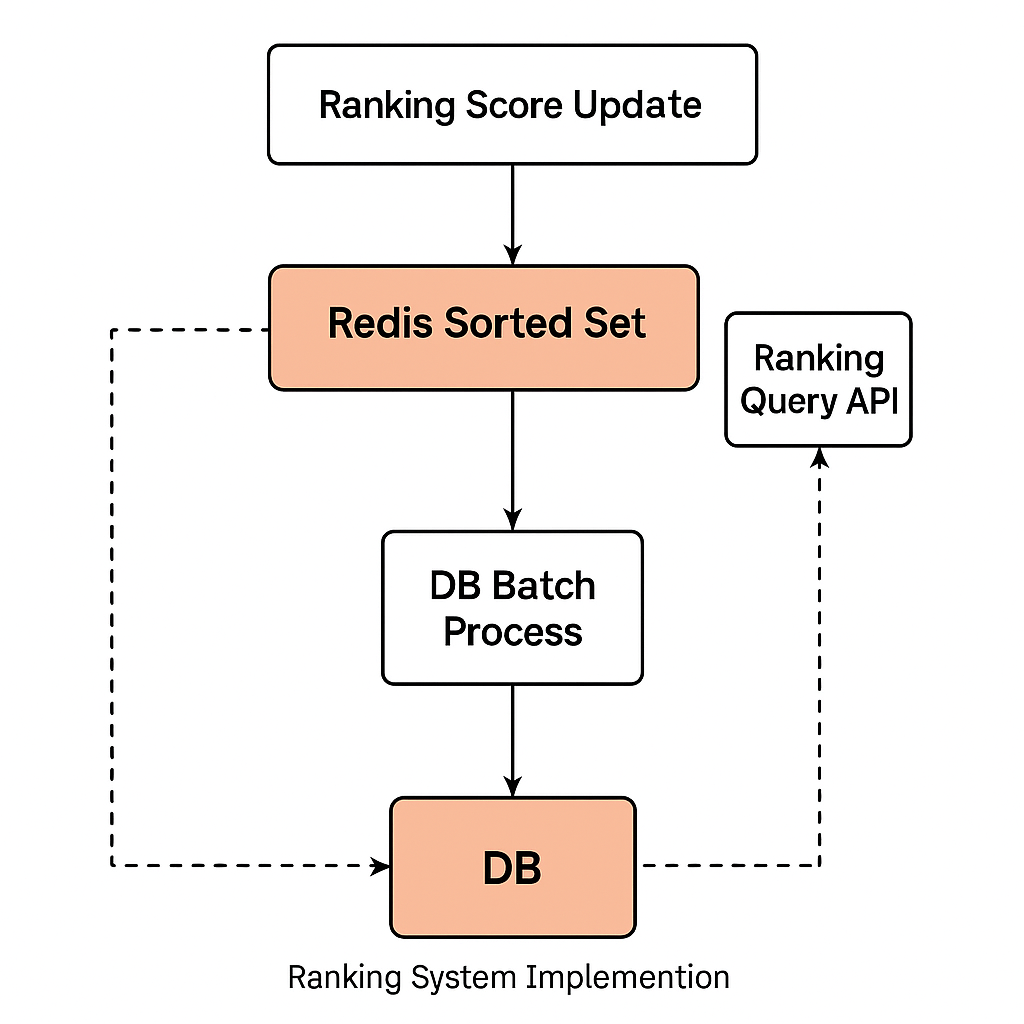
1. 실시간 점수 갱신
새로운 인플루언서 채널이 추가되거나 기존 채널의 데이터가 변경되면, 랭킹 산정에 필요한 Reels Score 및 Feed Score를 계산한 후, Redis의 Sorted Set에 ZADD 명령어를 통해 실시간으로 반영합니다.
예시:
ZADD reels_score 98.2 channelId-1
ZADD feed_score 88.2 channelId-1이 과정을 통해 Redis는 항상 최신 랭킹 상태를 유지하게 됩니다.
2. 랭킹 조회 API (비실시간)
사용자가 Reels Score 또는 Feed Score를 기준으로 정렬된 인플루언서 채널 리스트를 요청할 경우, DB에 저장된 랭킹 정보를 기준으로 응답합니다.
Redis의 최신 데이터는 실시간 반영되지만, DB에는 주기적으로 반영되기 때문에 실시간 랭킹과는 다를 수 있습니다.
예를 들어, 배치 작업 이전 시점에 Reels Score가 가장 높은 인플루언서가 새로 추가되었더라도, 해당 데이터는 DB에 반영되지 않았기 때문에 사용자에게는 표시되지 않을 수 있습니다.
3. DB 반영 (주기적, 비실시간)
Redis의 최신 랭킹 데이터를 DB에 반영하기 위해, 하루에 한 번 배치 작업이 실행됩니다.
-
배치 서버는 Redis에서 전체 랭킹 데이터를 조회한 후,
-
순위를 계산하여 인스타그램 채널 테이블에 업데이트합니다.
-
이 작업은 사용자 활동이 적은 시간대에 수행되며,
-
DB 락으로 인한 영향을 최소화하기 위해 페이지 단위로 나누어 순차적으로 처리합니다.
실시간 랭킹 서비스를 구현해야했다면?
현재는 하루 단위 랭킹 서비스를 구현했기 때문에, 상대적으로 부담이 적다고 판단하여 랭킹 정보를 DB에 저장했습니다.
하지만 만약 실시간 랭킹 서비스를 구현해야 했다면, 현재 설계 방식은 적합하지 않았을 것입니다.
랭킹 데이터가 갱신될 때마다 테이블 전체 또는 큰 범위의 데이터를 업데이트해야 할 수도 있고, 갱신 빈도도 매우 높아질 수 있기 때문입니다.
실시간 랭킹이라면, DB 컬럼에 랭킹 정보를 저장하지 않고, Redis만으로 랭킹 데이터를 관리하며 랭킹 조회 및 필터링 관련 로직을 애플리케이션에서 처리하는 방향이 더 효율적일 것입니다.
만약 랭킹 데이터가 매우 중요하고 실시간성이 필수적이라면,
-
랭킹 정보를 Redis에서 실시간으로 가져오고
-
DB에는 장애 대비용으로 주기적으로 갱신된 랭킹 데이터를 저장하는 이중 저장 구조를 고려할 수 있습니다.
이 경우 Redis 장애 시에는 DB에 저장된 랭킹 데이터를 임시로 활용해 서비스 연속성을 확보할 수 있지만,
DB에 저장된 랭킹 데이터가 Redis의 실시간 상태를 완벽히 반영하지 못한다는 한계는 존재합니다.
현재 제 생각으로는, DB 성능과 Redis와의 데이터 일관성을 동시에 완벽히 보장하는 설계는 쉽지 않으며, 실시간성 및 데이터 정확도 사이에는 불가피한 트레이드오프가 존재한다고 판단하고 있습니다.
혹시 더 나은 설계 방향이 있다면 피드백 부탁드립니다 🙇♂️
