실수로 프로덕션 DB를 삭제하다?!
들어가며
최근 저희 팀에서 실수로 프로덕션 DB를 삭제하는 사고가 발생했습니다.
당시의 상황을 되돌아보며, 기존 시스템의 문제점과 이를 개선하기 위해 도입한 방안들을 공유하고자 합니다.
사고 발생 상황
저희 백엔드 팀은 TypeORM을 사용하여 DB 마이그레이션을 관리하고 있습니다.
엔티티 변경이 발생하면 migration:generate 명령어로 마이그레이션 파일을 생성하고, migration:run 명령어로 실제 마이그레이션을 적용합니다. 환경별 DB 지정을 위해 --env 옵션을 사용하고 있었습니다.
또한, 개발 편의를 위해 DB 초기화용 스크립트를 추가했습니다:
-
db:up : DB를 생성하는 명령어
-
db:down : DB를 삭제하는 명령어
문제는 동료 개발자께서 개발 환경 DB를 초기화하려다 실수로 db:down --env=prod 명령어를 실행하여 프로덕션 DB가 삭제된 것입니다 😱

사고 수습 과정
다행히도 AWS RDS의 자동 스냅샷 기능 덕분에 즉시 복구를 진행할 수 있었습니다. 마지막 스냅샷과 DB 삭제 시점의 차이가 약 1시간이었고, 해당 시간 동안의 CUD 작업이 10건 정도로 비교적 적었던 것도 다행이었습니다.
삭제된 1시간 동안의 데이터 복구를 위해 RDS의 general_log를 확인하려 했으나, 기본 설정이 false로 되어 있어 쿼리 로그를 찾을 수 없었습니다. 결국 Loki를 활용하여 요청 로그를 분석하며 데이터를 복원했습니다.
개선 방안
1. Prod DB를 향한 명령어 실행 차단
누구나 실수로 프로덕션 DB를 삭제할 수 있는 위험이 있었습니다.
이를 방지하기 위해 db:down 명령어가 프로덕션 환경에서 실행되지 않도록 수정했습니다.
db:down": "sh -c 'if [ \"${npm_config_env}\" = \"prod\" ]; then echo \"\033[31m❌ 프로덕션 환경에서는 데이터베이스 삭제를 허용하지 않습니다.\033[0m\"; exit 1; else npm run typeorm-ext db:drop; fi'"
2. RDS 스냅샷 자동 생성 및 삭제
운 좋게 DB 삭제 시점과 자동 백업 시점의 차이가 1시간밖에 나지 않아 피해를 최소화할 수 있었습니다.
하지만, 이 간극이 더 컸다면 큰 문제가 될 수 있었겠죠.
따라서 피해 범위를 최소화하기 위해 정기적인 스냅샷 생성을 자동화하는 인프라를 구축했습니다.
RDS의 기본 설정에서는 매일 한 번 스냅샷을 생성할 수 있지만, 보다 세밀한 주기로 스냅샷을 찍기 위해 AWS Lambda + EventBridge Scheduler를 활용했습니다.
인프라 구성도
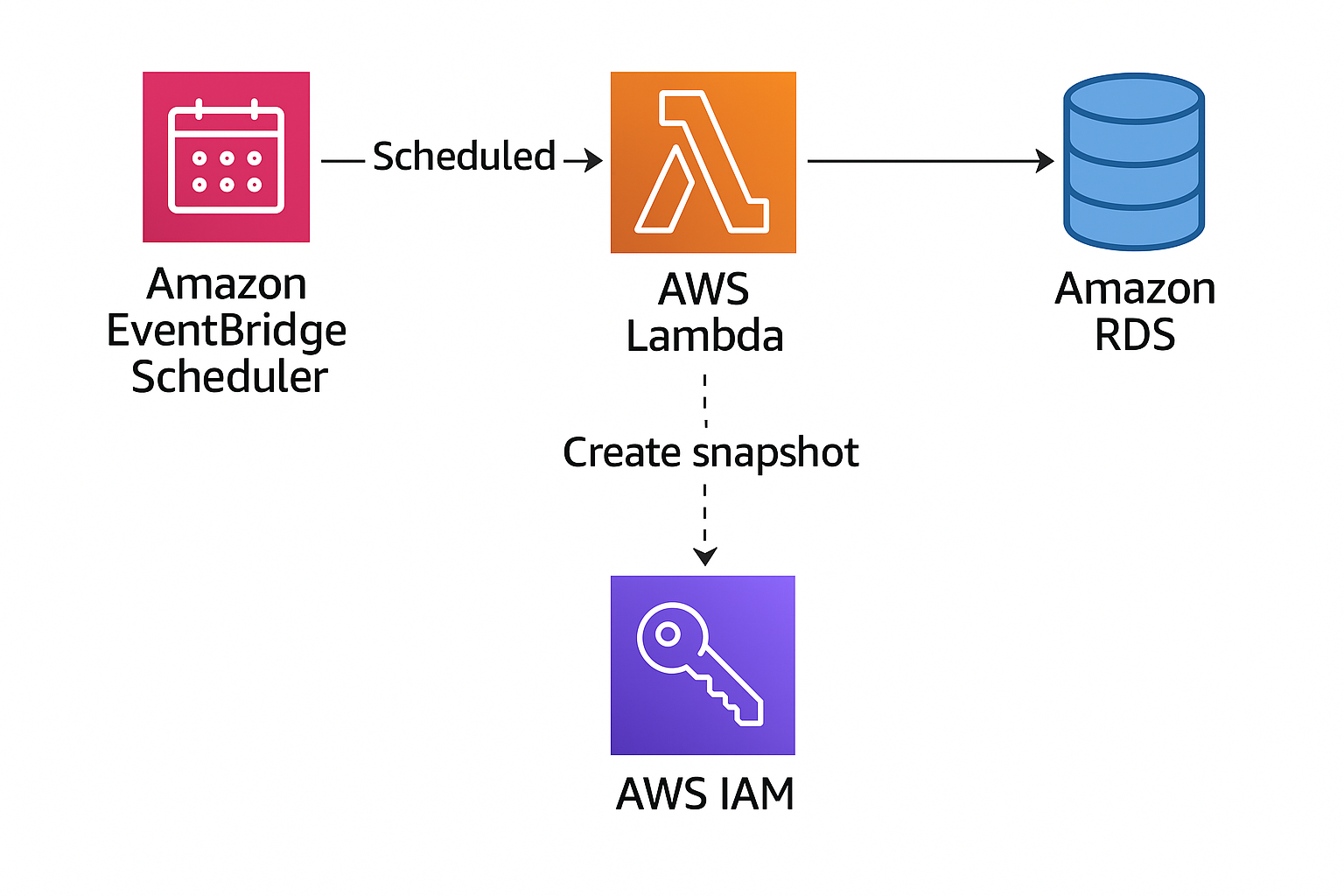
2.1 스냅샷 생성용 AWS Lambda 함수
import json
import boto3
from datetime import datetime, timedelta
def lambda_handler(event, context):
client = boto3.client('rds')
# 현재 UTC 시간을 KST(UTC+9)로 변환
now_utc = datetime.now()
now_kst = now_utc + timedelta(hours=9)
# yyyymmdd-HHMMSS 형식으로 날짜 포맷팅
date = now_kst.strftime("%Y%m%d-%H%M%S")
tagname = now_kst.strftime("%Y%m%d")
response = client.create_db_snapshot(
DBSnapshotIdentifier='${db-name}-{}'.format(date),
DBInstanceIdentifier='${db-name}',
Tags=[
{
'Key': 'backupon',
'Value': tagname
},
]
)
return response2.2 스냅샷 삭제용 AWS Lambda 함수
import json
import boto3
from datetime import datetime, timedelta
def lambda_handler(event, context):
client = boto3.client('rds')
# 삭제 기준: 1일 이전의 스냅샷
cutoff_datetime = datetime.now() - timedelta(days=1)
cutoff_date = cutoff_datetime.strftime("%d-%m-%Y")
print("=" * 80)
print(f"[INFO] 시작: RDS 스냅샷 정리 작업 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print(f"[INFO] 삭제 기준일: {cutoff_date} 이전 생성된 스냅샷")
print("=" * 80)
# 스냅샷 조회 (manual 타입만 대상)
snapshots = client.describe_db_snapshots(DBInstanceIdentifier='${db-name}', SnapshotType='manual')
total_snapshots = len(snapshots['DBSnapshots'])
print(f"[INFO] 총 {total_snapshots}개의 스냅샷을 찾았습니다.")
deleted_count = 0
skipped_count = 0
print("\n[INFO] 스냅샷 검사 시작...")
print("-" * 80)
for index, snapshot in enumerate(snapshots['DBSnapshots'], 1):
snapshot_id = snapshot['DBSnapshotIdentifier']
snapshot_type = snapshot['SnapshotType']
create_time = snapshot['SnapshotCreateTime']
snapshot_date = create_time.strftime("%d-%m-%Y")
print(f"[{index}/{total_snapshots}] 스냅샷: {snapshot_id}")
print(f" - 유형: {snapshot_type}")
print(f" - 생성일: {snapshot_date}")
if snapshot_type == "manual":
if snapshot_date <= cutoff_date:
print(f" - 상태: 삭제 대상 (기준일 {cutoff_date} 이전 생성됨)")
try:
client.delete_db_snapshot(DBSnapshotIdentifier=snapshot_id)
print(f" - 결과: 성공적으로 삭제됨 ✓")
deleted_count += 1
except Exception as e:
print(f" - 결과: 삭제 실패 ✗ - 오류: {str(e)}")
else:
print(f" - 상태: 유지 (기준일 {cutoff_date} 이후 생성됨)")
skipped_count += 1
else:
print(f" - 상태: 유지 (수동 스냅샷이 아님)")
skipped_count += 1
print("-" * 80)
print("\n" + "=" * 80)
print(f"[요약] 총 스냅샷: {total_snapshots}개")
print(f"[요약] 삭제된 스냅샷: {deleted_count}개")
print(f"[요약] 유지된 스냅샷: {skipped_count}개")
print(f"[INFO] 종료: RDS 스냅샷 정리 작업 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 80)
return {
'statusCode': 200,
'body': json.dumps({
'total': total_snapshots,
'deleted': deleted_count,
'skipped': skipped_count
})
}2.3 Amazon EventBridge Schedule 설정
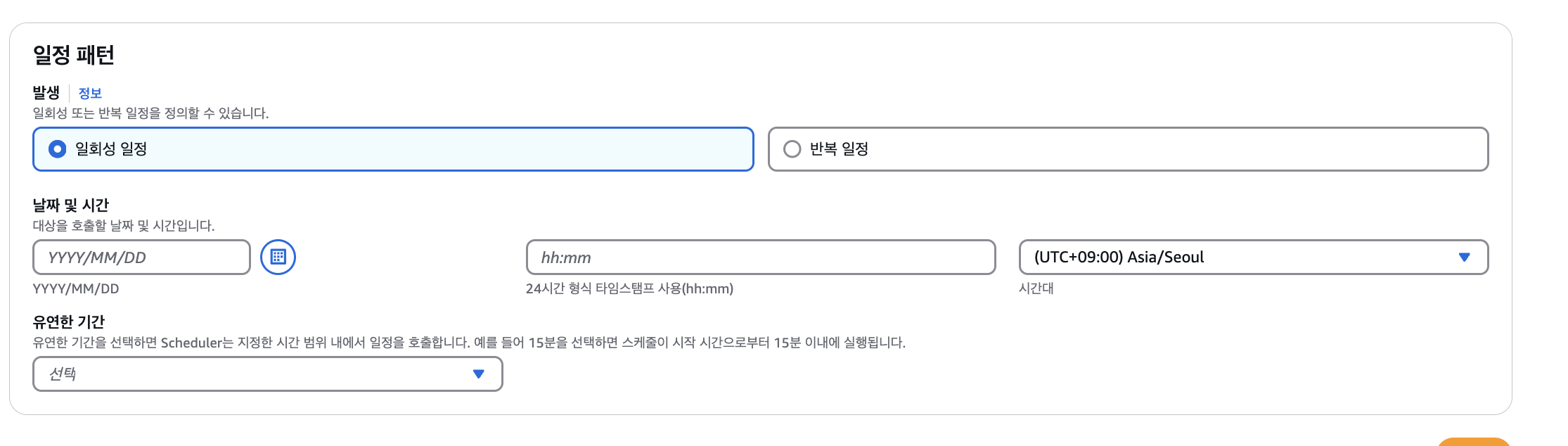
정기적인 스냅샷 생성 및 삭제를 위해 Amazon EventBridge Scheduler를 사용하여 Lambda 함수를 특정 주기로 트리거합니다.
-
스케줄 생성: EventBridge Scheduler를 통해 원하는 주기(예: 매일)에 Lambda 함수를 실행합니다.
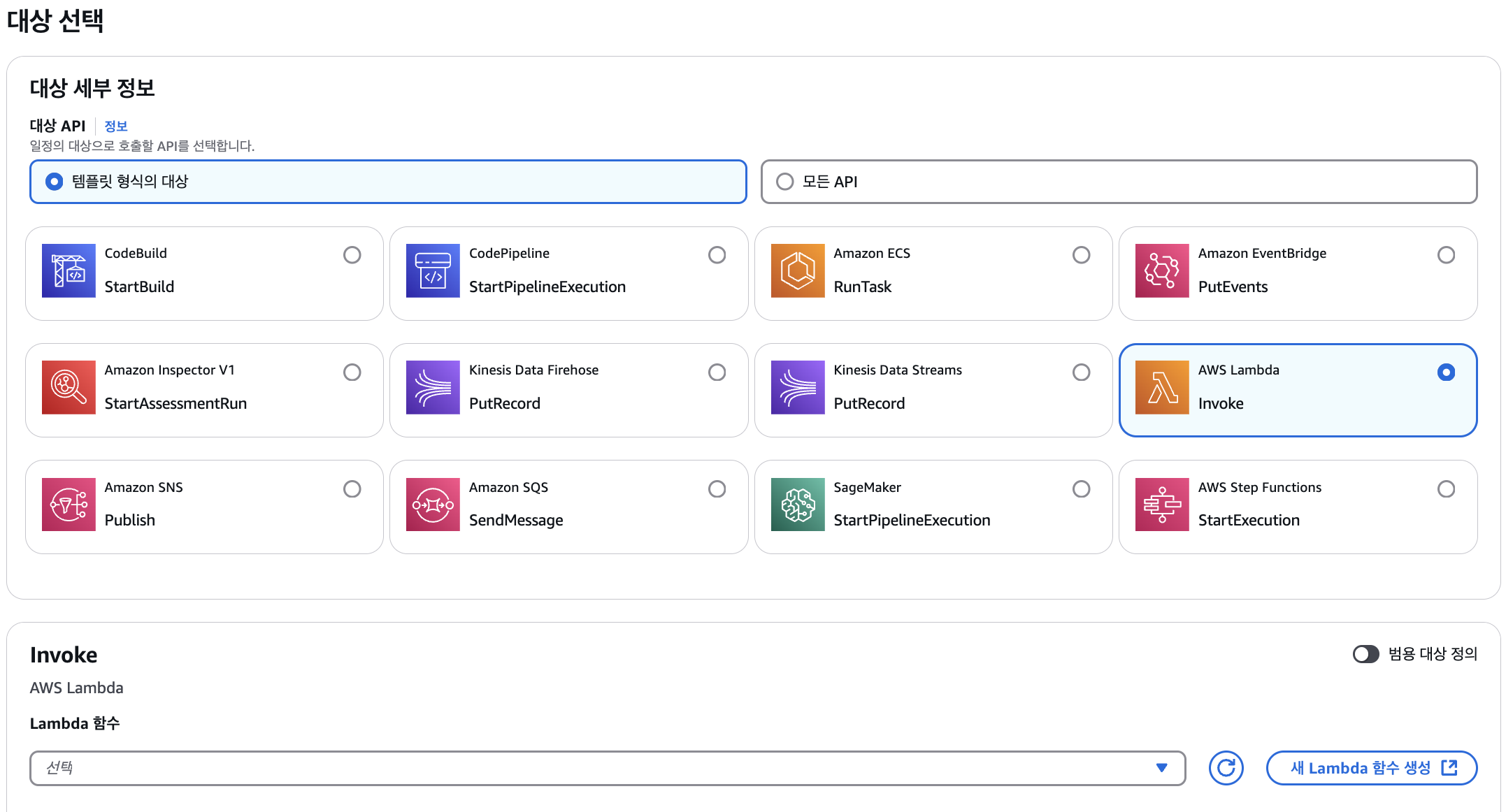
-
대상 설정: 생성된 스케줄의 대상(Target)으로 Lambda 함수를 선택합니다.
3. TypeORM Custom Logger Service를 통한 데이터베이스 변경 이력 관리
데이터 유실 사고가 발생했을 때, Loki 로그를 기반으로 데이터를 복구하는 과정에서 CUD(Create, Update, Delete) 요청을 식별하고, Request Body를 분석하는 데 많은 시간과 노력이 소요되었습니다. 이를 개선하기 위해 TypeORM의 Custom Logger Service를 활용하여 데이터베이스 변경 이력을 효율적으로 관리하는 방법을 도입했습니다.
기존 검토 사항
- RDS general_log 활성화: 모든 쿼리를 로깅하는 방법이 있지만, 이 방식은 불필요한 스토리지 사용이 발생하고, 성능에 부담을 줄 수 있는 단점이 있었습니다.
TypeORM Custom Logger Service 활용
TypeORM의 Custom Logger Service를 사용하여 CREATE, UPDATE, DELETE 쿼리만 선택적으로 로깅할 수 있도록 구현했습니다. 이 방식은 불필요한 로그를 방지하고, 중요한 데이터베이스 변경 사항만 효율적으로 추적할 수 있게 해줍니다.
Custom Logger Service는 Logger 클래스를 implements하여 생성할 수 있습니다. 여기서 중요한 부분은 logQuery 메서드로, TypeORM이 쿼리를 실행할 때마다 자동으로 호출됩니다. 이 메서드를 활용하여 원하는 쿼리만 로깅하도록 설정했습니다.
예시 코드
import { LoggerService } from '@app/external/logger/logger.service';
import { Injectable } from '@nestjs/common';
import { Logger, QueryRunner } from 'typeorm';
@Injectable()
export class TypeOrmLoggerService implements Logger {
constructor(private readonly loggerService: LoggerService) {}
logQuery(query: string, parameters?: any[], queryRunner?: QueryRunner) {
// CREATE, UPDATE, DELETE 쿼리만 로깅
const normalizedQuery = query.trim().toUpperCase();
if (
normalizedQuery.startsWith('INSERT') ||
normalizedQuery.startsWith('UPDATE') ||
normalizedQuery.startsWith('DELETE')
) {
this.loggerService.log(`Executed Query: ${query} | Parameters: ${JSON.stringify(parameters)}`);
}
}
}
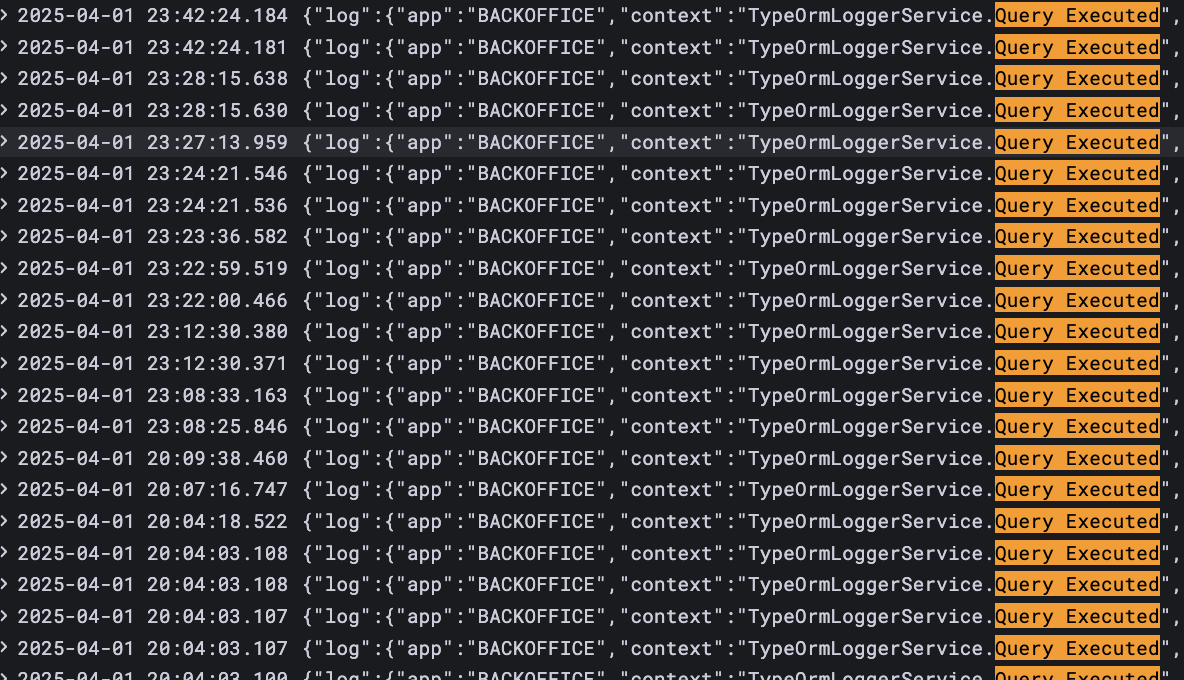
위 코드를 통해 CREATE, UPDATE, DELETE 쿼리만 로깅하며, 쿼리 내역을 Executed Query 키워드와 함께 Grafana Loki에서 조회할 수 있습니다.
이를 통해 특정 시간대에 실행된 쿼리들을 쉽게 파악할 수 있으며, 데이터베이스 변경 이력을 보다 효율적으로 추적할 수 있습니다.
Grafana 로그 예시
마무리
이번 사고를 통해 기존 시스템의 문제점을 다시금 돌아보며, 운영 환경에서 실수로 발생할 수 있는 위험 요소를 최소화하는 시스템 구축의 중요성을 더욱 깊이 깨달았습니다. 이를 개선하기 위해 운영 환경에서의 명령어 실행 차단, 자동화된 RDS 스냅샷 관리, TypeORM Custom Logger Service를 활용한 데이터 변경 이력 관리 등의 방안을 도입했습니다.
이러한 경험을 바탕으로 팀 전체가 더욱 신뢰할 수 있는 시스템을 구축하고, 향후 발생할 수 있는 문제를 사전에 예방하며 신속하게 대응할 수 있도록 지속적으로 개선해 나가겠습니다.
