들어가며
이전 글에서 이어집니다.
이전 글에 이어서 stored procedure 단점에 대해 살펴보겠습니다.
transparent 하다고 무조건 좋은 것은 아니다
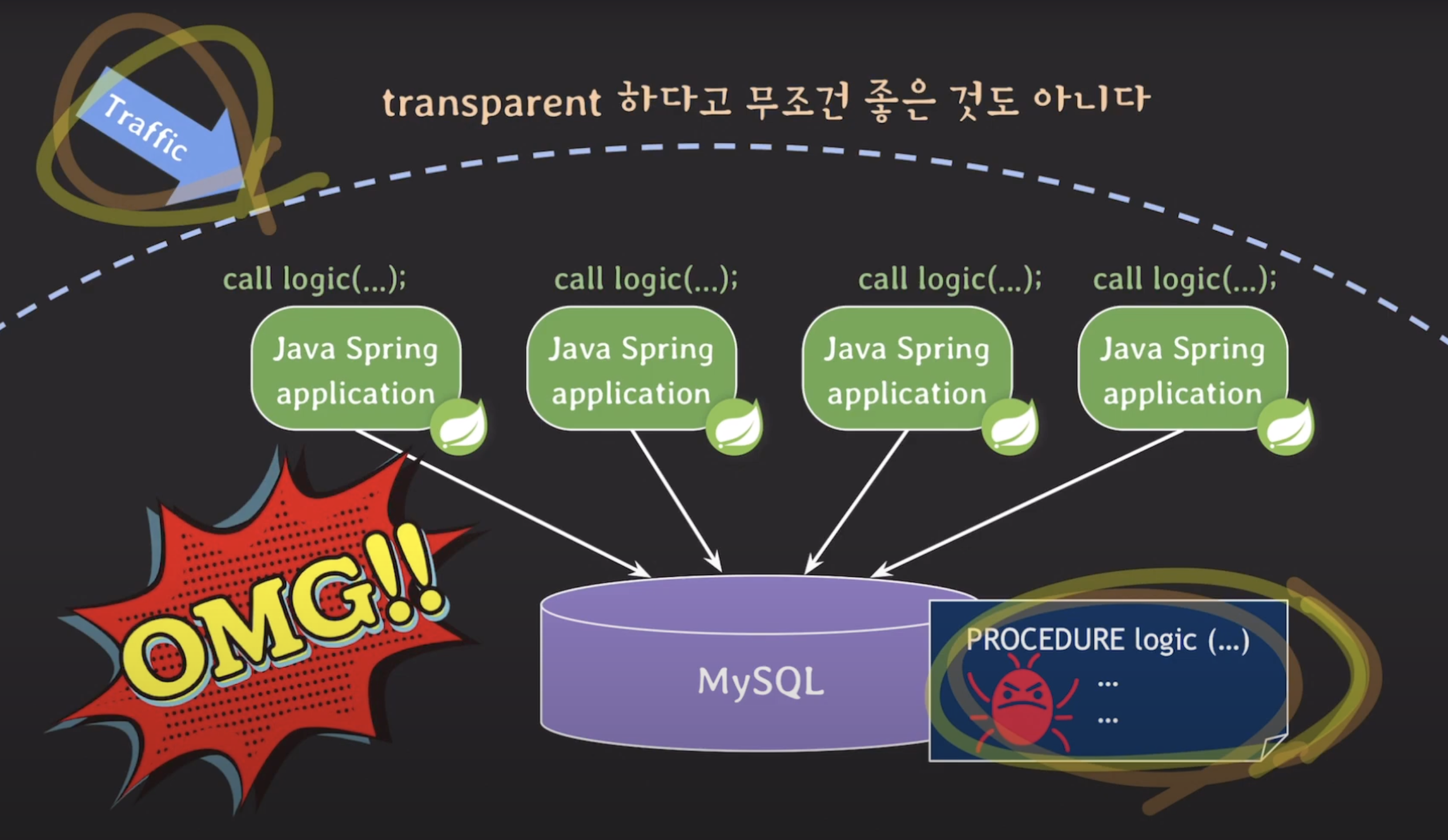
Stored Procedure를 통해 비즈니스 로직을 관리하는 상황에서 transparent 하다고 항상 모든 상황에서 좋은 것은 아닙니다. 예를 들어, 변경 사항을 적용한 뒤 배포를 진행했는데 예상치 못한 버그가 발생한다고 가정해봅시다. 이럴 경우 빠르게 이전 버전으로 롤백하여 버그를 해결하게 될 것입니다.
그러나 문제가 있었던 프로시저를 사용하고 있던 모든 웹 애플리케이션 서버에서는 해당 문제가 발생한 시간 동안 잘못된 로직이 담긴 프로시저를 사용하고 있었습니다. 이로 인해 해당 서버에서 발생한 트래픽들은 잘못된 로직을 사용하고 있어 안 좋은 영향을 받았을 것입니다.
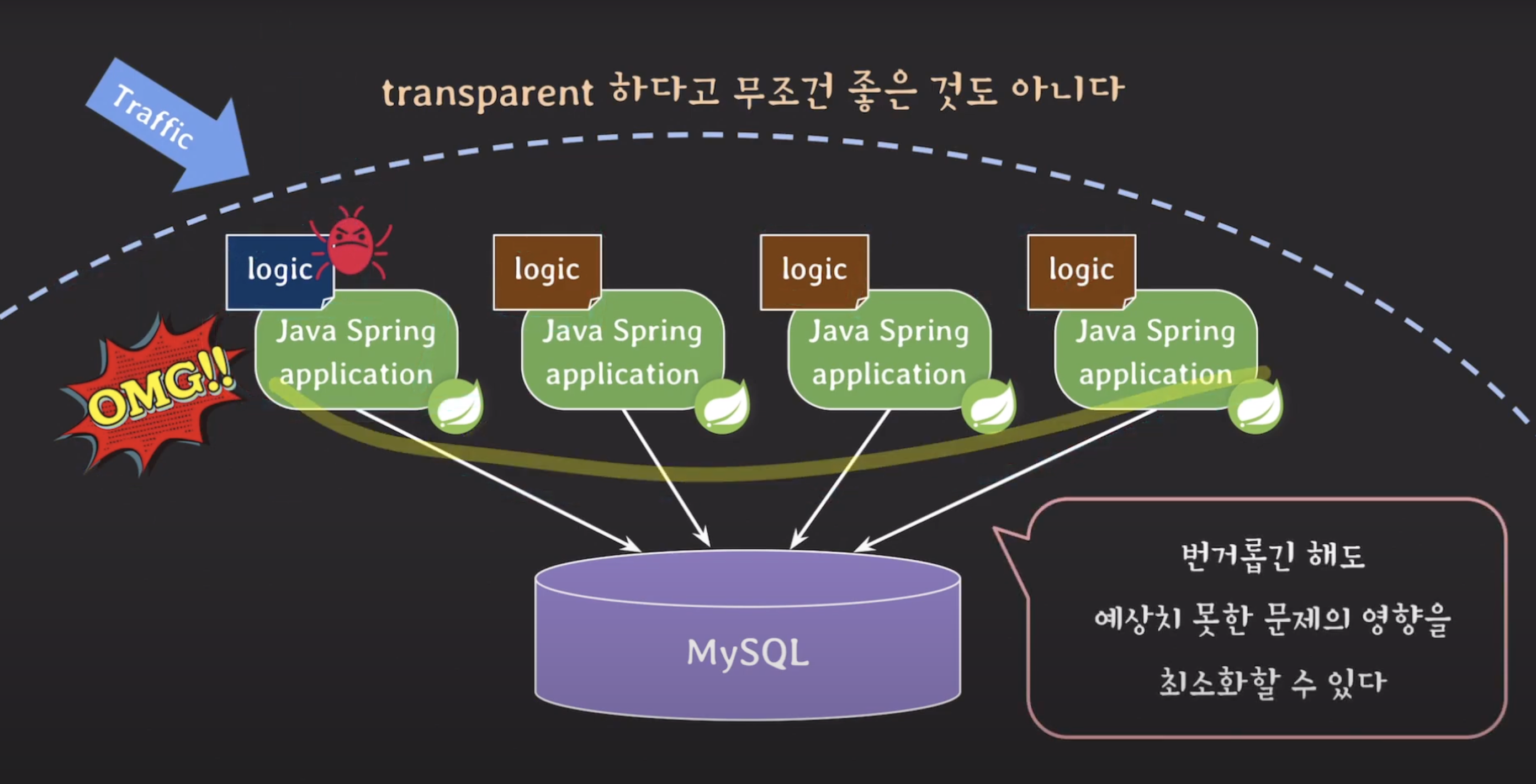
반면에 로직 티어에서 소스 코드를 통해 비즈니스 로직을 관리할 경우, 변경 사항을 적용한 뒤 모든 웹 애플리케이션 서버를 한 번에 재시작하는 것이 아니라 서버를 하나씩 변경된 로직이 적용된 상태로 재시작할 수 있습니다.
이렇게 하나의 서버에서 문제가 발생한 경우, 해당 서버만 롤백하고 재시작할 수 있습니다. 이렇게 하면 예상치 못한 문제가 발생한 경우에도 영향을 최소화할 수 있습니다. 모든 웹 애플리케이션 서버가 동시에 영향을 받지 않으므로 문제 상황을 조기에 파악하고 대응할 수 있습니다.
재사용 가능하다는 것이 양날의 검이 될 수도..
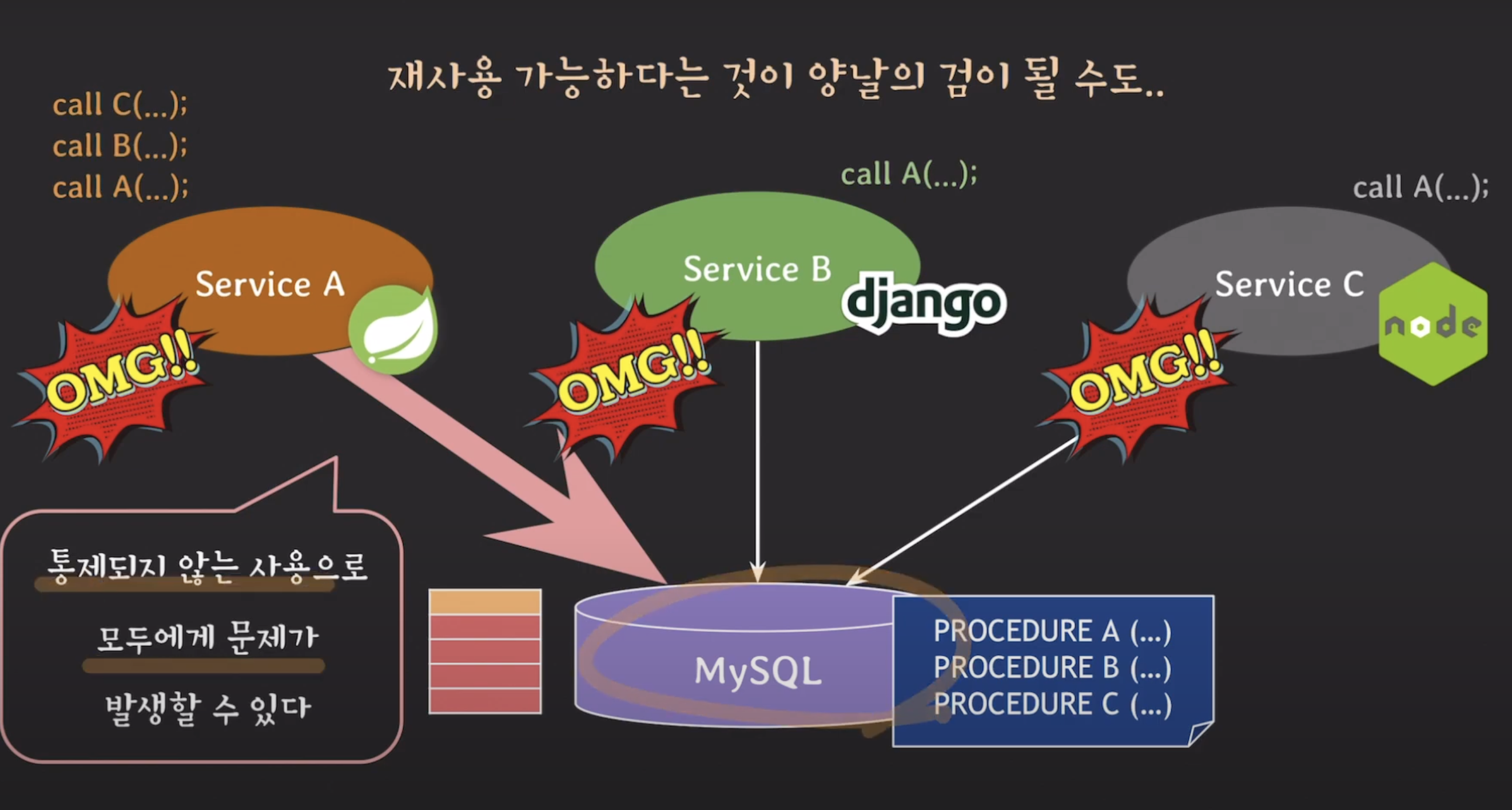
이전에 살펴봤듯이, 여러 서비스가 공통된 비즈니스 로직을 사용하고 싶을 때, 프로시저를 활용하여 비즈니스 로직을 관리하면 서로 다른 언어로 구현할 필요 없이 해당 프로시저를 호출하여 사용할 수 있어 재사용성이 높다는 장점이 있습니다.
그러나 이런 점은 양날의 검이 될 수 있습니다. 예를 들어, 서비스 A에서 프로시저를 호출하는 양이 많아지면서 DBMS의 CPU 사용량이 90% 이상 증가하는 상황에 놓였다고 생각해봅시다.
이렇게 되면 DB의 프로시저를 사용하는 모든 서비스들에 악영향을 미칠 수 있습니다. 따라서 통제되지 않은 사용으로 인해 프로시저를 사용하는 모든 서비스들에 문제가 발생할 수 있습니다.
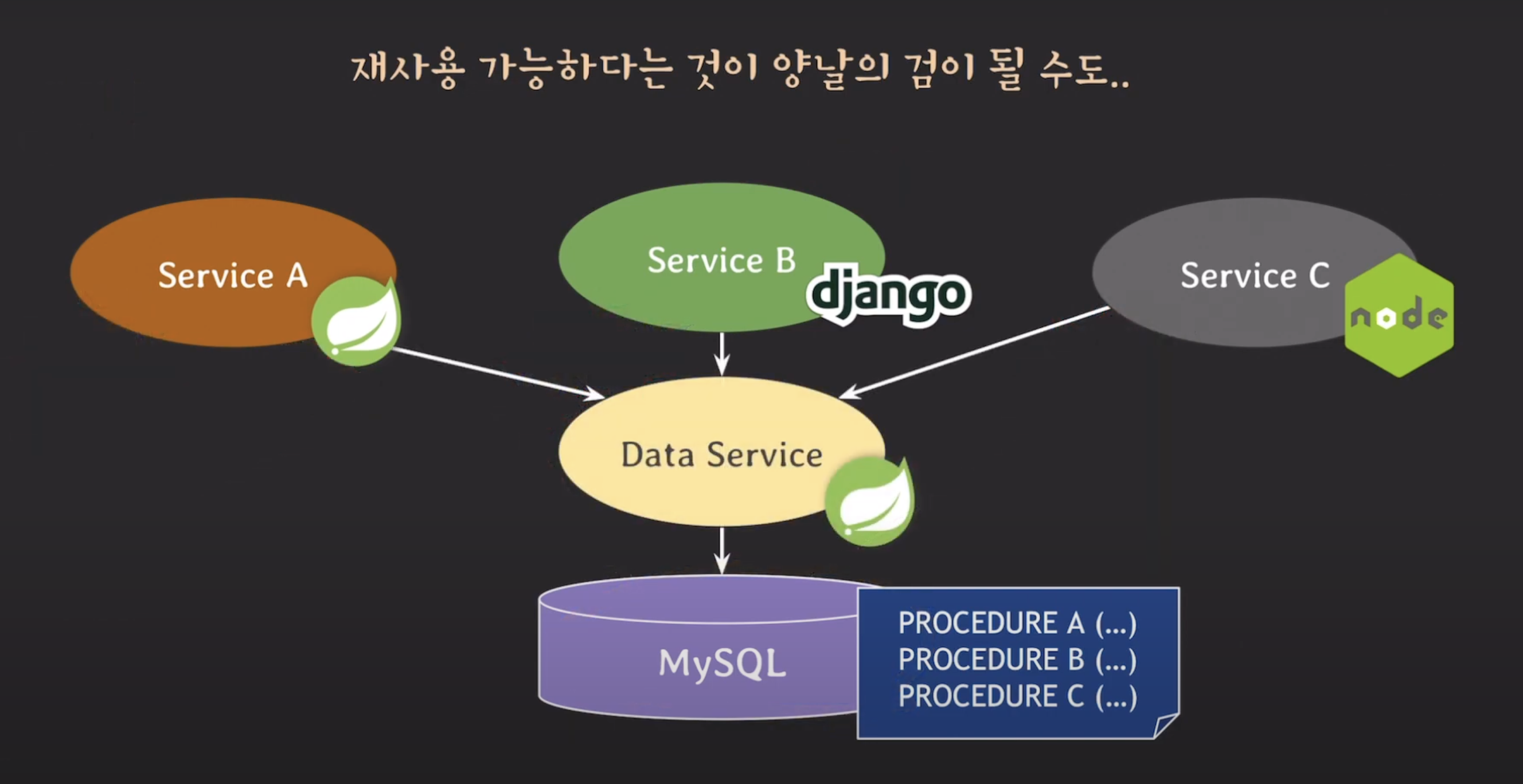
이러한 문제를 방지하기 위해서는 서비스 계층과 DB 계층 사이에 데이터 서비스(Data Service)를 도입하여 서비스 계층이 직접적으로 DB 계층에 접근하는 것을 방지하는 구조를 만들어야 합니다.
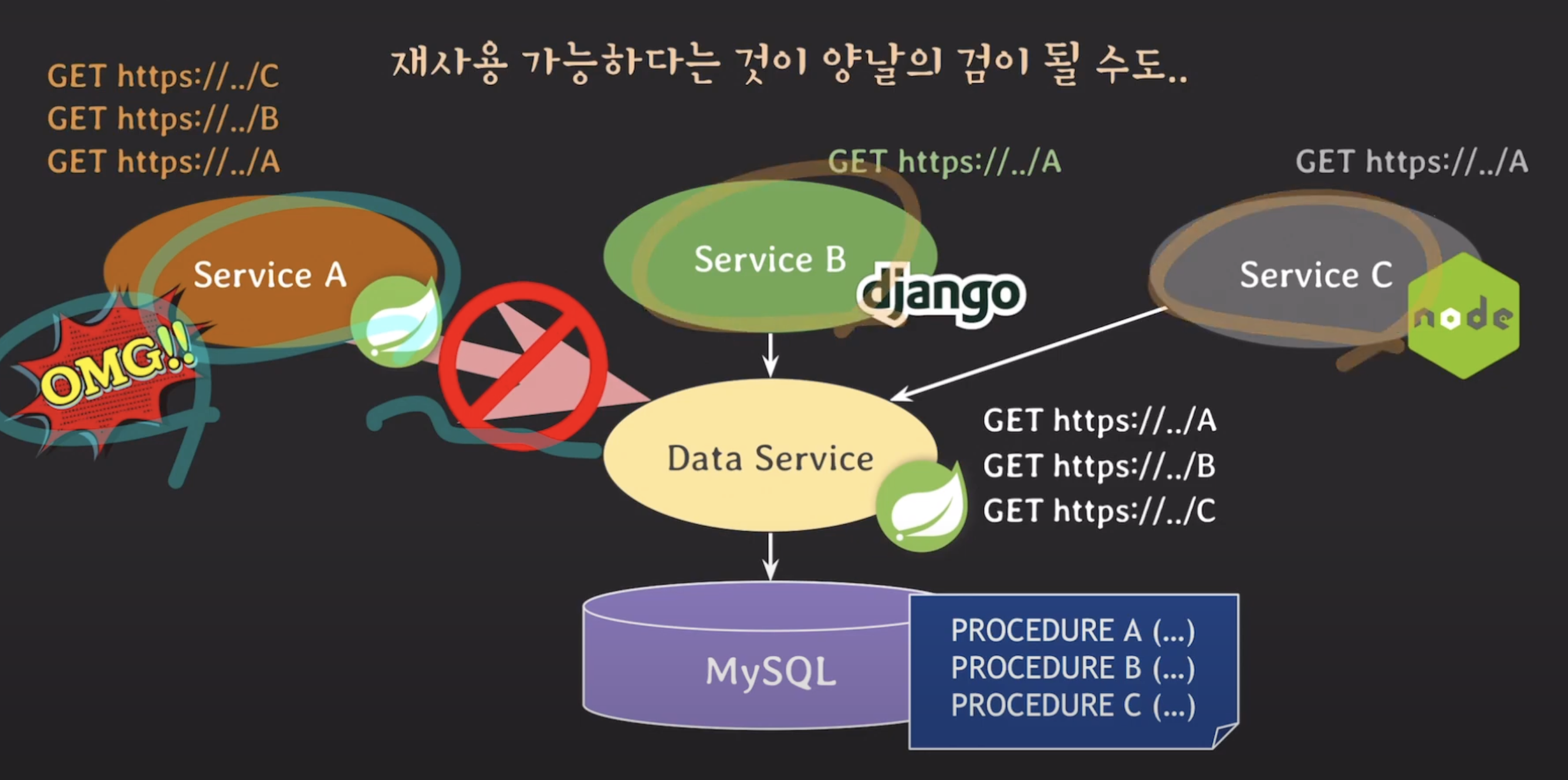
데이터 서비스는 RESTful API와 같은 인터페이스를 제공하여 서비스 계층이 API를 호출하는 형태로 데이터에 접근할 수 있도록 합니다. 이런 상황에서 서비스 A가 데이터 서비스를 과도하게 호출하는 상황이 발생하면, 데이터 서비스는 서비스 A의 호출을 제한하여 다른 서비스들에게 문제가 전파되지 않도록 예방할 수 있습니다. 이렇게 함으로써 모든 서비스에 문제가 발생하는 상황을 막을 수 있습니다.
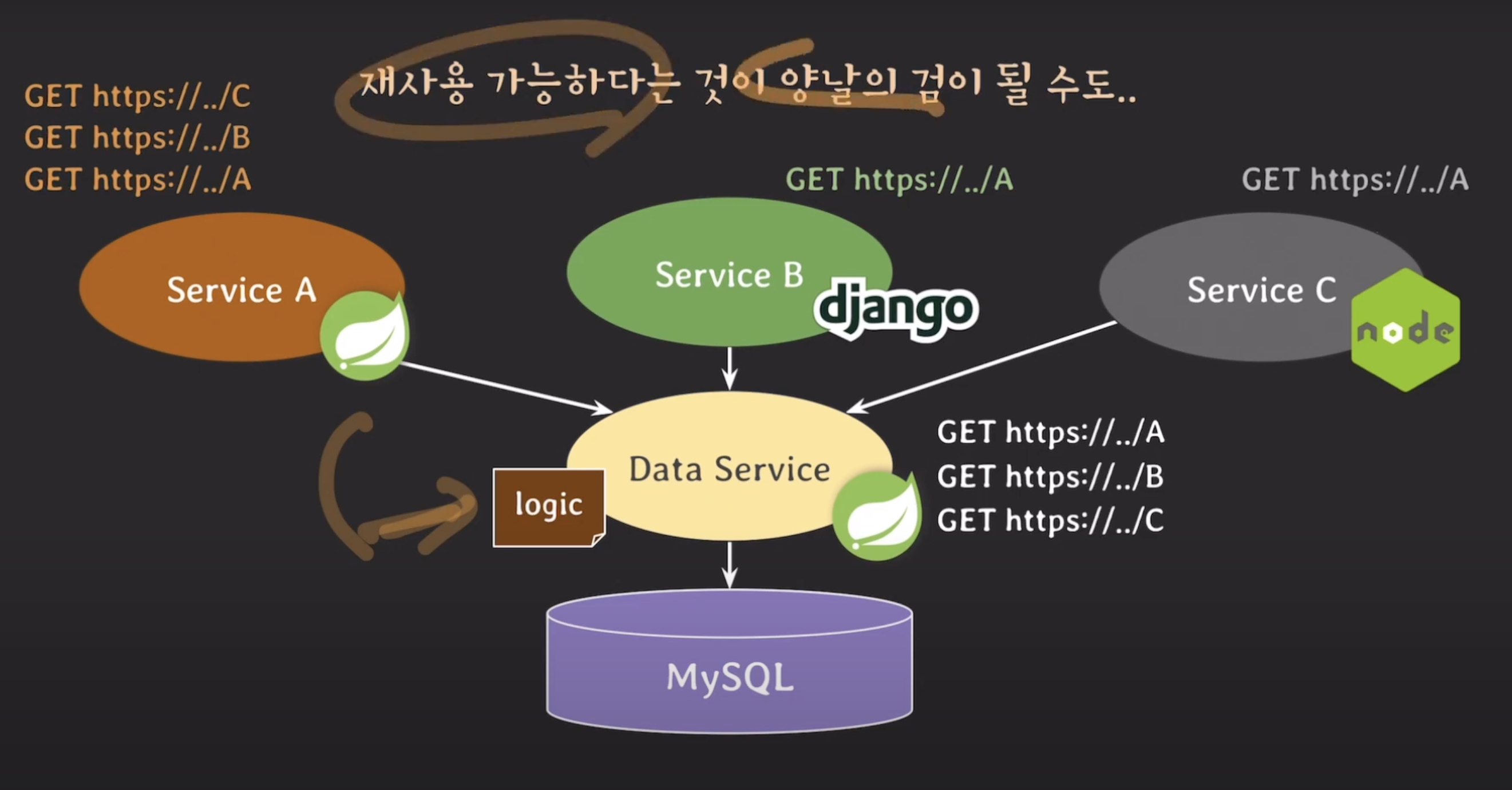
이러한 접근 방식은 데이터 서비스 계층을 관리하는 팀에서 비즈니스 로직을 어떻게 관리해야 할 지 고민하게 되며, 결국 로직 계층에서 비즈니스 로직을 관리하게 될 것입니다. 이를 통해 재사용성과 시스템의 안정성을 모두 확보할 수 있습니다.
비즈니스 로직을 소스코드에 두고도 응답속도를 향상 시킬 수 있다
저번에 살펴본 것처럼, 프로시저를 사용하는 가장 큰 장점 중 하나는 네트워크 트래픽을 줄여 응답 속도를 향상시킬 수 있다는 점입니다.
그러나, 비즈니스 로직을 소스 코드에 유지하면서도 응답 속도를 향상시킬 수 있는 방법들이 있습니다.
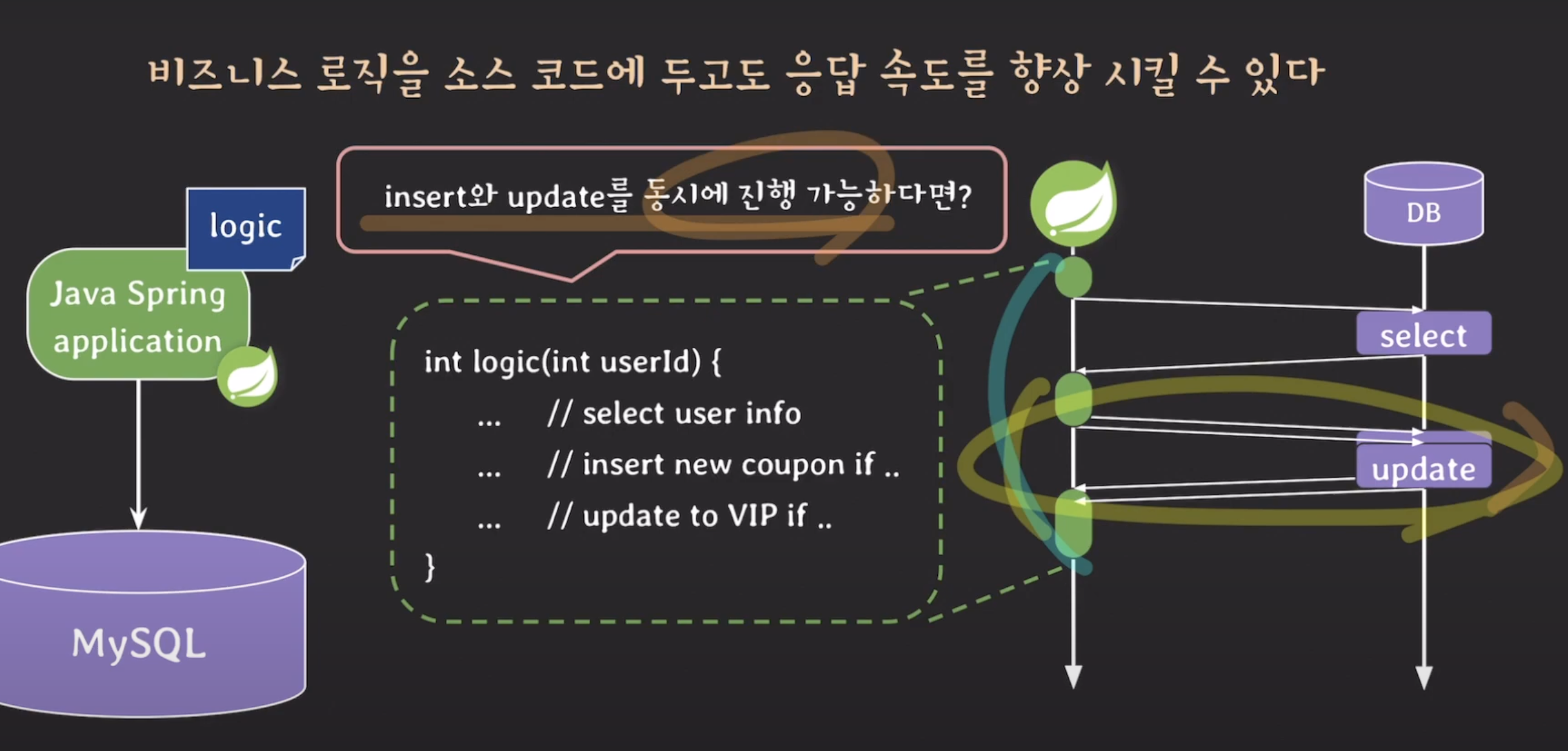
비즈니스 로직에는 여러 개의 SQL 문이 순차적으로 호출될 수 있습니다. 이 경우에는 서비스 계층과 DB 계층 간의 네트워크 오버헤드로 인해 응답 속도에 악영향을 미칠 수 있습니다.
하지만 만약 동시에 실행 가능한 작업들이 있다면 이를 병렬로 처리함으로써 응답 속도를 향상시킬 수 있습니다. 예를 들어, 동시에 수행 가능한 insert와 update 작업이 있다면 이를 순차적으로 호출할 필요 없이 동시에 호출하여 응답 속도를 향상시킬 수 있습니다.
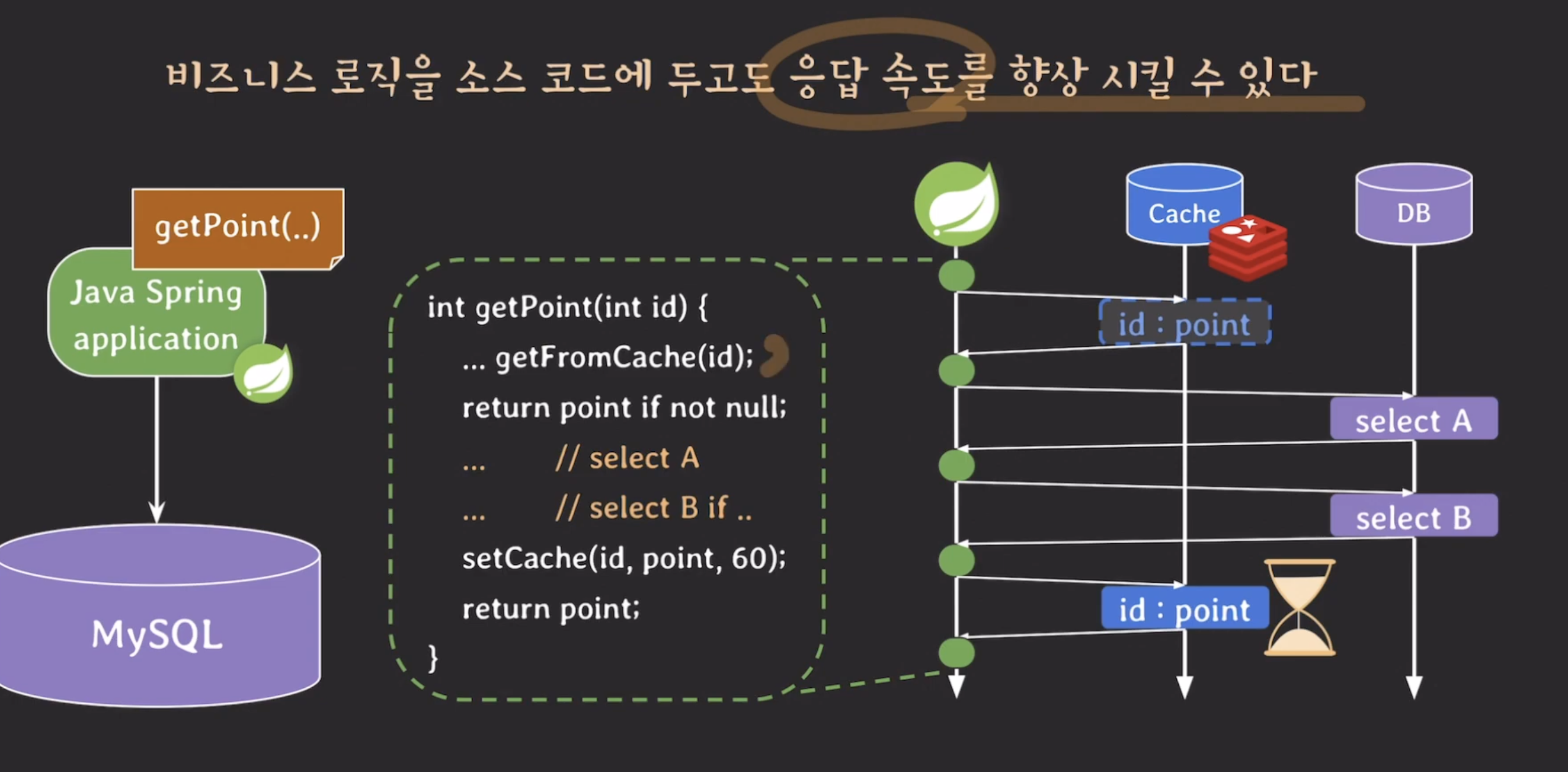
예를 들어, getPoint라는 method의 2개의 select문이 있다고 합시다.
해당 select문은 반드시 순차적으로 처리해야하는 로직입니다.
이럴 경우에는 어떻게 응답속도를 향상 시킬 수 있을까요?
cache를 사용해 응답속도를 향상 시킬 수 있습니다.
cache를 사용하면 이전에 처리한 결과를 저장해두고, 동일한 요청이 들어올 경우에는 저장된 결과를 반환함으로써 DB 부하를 줄이고 응답 속도를 향상시킬 수 있습니다.
그 외
- procedure로는 복잡하고 유연한 코드를 작성하기 어렵다.
- 오늘날의 프로그래밍 언어는 훨씬 다양하고 강력한 기능들을 제공한다.
- procedure는 가독성이 떨어진다.
- procedure는 디버깅이 어렵다.
