파이토치를 처음 입문하시는 분들이 가장 기초가 되는 텐서에 대해 보실 수 있도록 정리했습니다. (저 스스로도 Pytorch를 이해하기 위해서...)
Tensor
Pytorch에서는 텐서를 사용해 모델의 input, output, 모델의 파라미터를 encode(부호화)한다.
텐서는 GPU나 다른 하드웨어 가속기에서 실행할 수 있다는 점만 numpy.ndarray와 다르지, 나머지는 별 차이가 없다. 다음과 같이 라이브러리를 실행할 수 있다.
import torch
import numpy as np다만, 여기서 기본적으로 이해해야 할 개념이 있다. 벡터, 행렬, 텐서에 대해 이해할 수 있어야 한다.
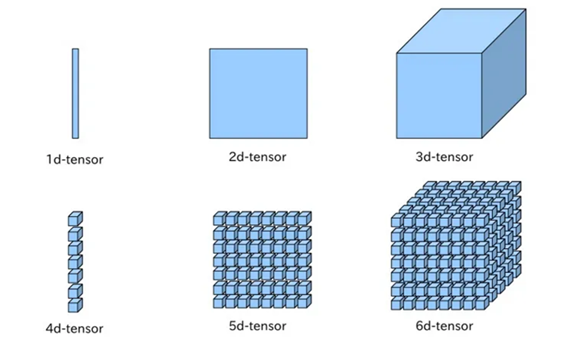
여기서, 1차원으로 구성된 값을 벡터, 2차원으로 구성된 값을 행렬, 그 이상은 주로 텐서라고 부른다. 하지만 편의상, 그냥 다 텐서라고 부른다.
여기서 중심이 되는 2d-tensor, 3d-tensor에 대해 간단하게 설명한다.
2D Tensor
2차원 텐서는 크기를 (batch size x dimension)으로 표현한다. 행의 크기가 Batch Size, 열의 크기가 Dimension이다.
예시를 들어 설명하면, 훈련 데이터 하나의 크기를 256이라 한다면, [3, 1, 2, 4…]와 같은 이런 숫자들의 나열이 256개가 있다고 할 수 있다. 즉, 훈련 데이터 하나에는 256개의 숫자가 있다. 그런데, 훈련 데이터의 개수가 3000개라면, 전체 훈련 데이터의 크기는 256 x 3000이 되는 것이다. 이때, 컴퓨터에서는 하나씩 처리하는 것보다 무리지어서 처리하는 것을 선호하는데, 한 번에 몇개씩 처리할지에 대해 이야기할 때 나오는 것이 Batch Size이다.
즉, batch size가 64라면, 한번에 64개씩 처리하게 되는 것이다. → 2D 텐서의 크기는 (64x256)이 된다. 그렇다면, 3000을 64로 나누면 46.875가 나오는데, 47번 데이터를 넣어야 모든 데이터를 넣을 수 있게 된다.
3D Tensor
3차원 텐서의 경우, (Batch Size, Width, Height)로 표현한다. 일반적으로 자연어처리보다는 비전 분야에서 많이 다루게 되는데, 세로가 batch size, 가로가 width, 안쪽으로 height가 된다.
만약 NLP에서 3차원으로 사용하게 된다면, (Batch Size, 문장 길이, 단어 벡터의 차원) 이렇게 사용한다.
이거는 그냥 보고만 넘어가면 될 것 같다. 모르면 무시하자.
만약 4개의 문장이 있는데, 이를 훈련 데이터로 재구성하는 다음과 같다.
[[나는 사과를 좋아해], [나는 바나나를 좋아해], [나는 사과를 싫어해], [나는 바나나를 싫어해]]라는 케이스가 있을 때, 컴퓨터가 이해할 수 있도록, 단어별로 구분을 해줘야 한다. 그렇다면, 다음과 같이 나눌 수 있다.
[
['나는', '사과를', '좋아해'],
['나는', '바나나를', '좋아해'],
['나는', '사과를', '싫어해'],
['나는', '바나나를', '싫어해']
]이제 4x3의 텐서를 가지게 된다. 아래와 같은 벡터로 변환을 한다면
'나는' = [0.1, 0.2, 0.9]
'사과를' = [0.3, 0.5, 0.1]
'바나나를' = [0.3, 0.5, 0.2]
'좋아해' = [0.7, 0.6, 0.5]
'싫어해' = [0.5, 0.6, 0.7]훈련 데이터를 재구성할 때 다음과 같다.
[[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.7, 0.6, 0.5]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.7, 0.6, 0.5]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.5, 0.6, 0.7]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.5, 0.6, 0.7]]]Batch Size를 2로 설정한다면 (2x3x3) 이렇게 설정이 되고, 다음과 같이 나뉜다.
첫번째 배치 #1
[[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.7, 0.6, 0.5]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.7, 0.6, 0.5]]]
두번째 배치 #2
[[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.5, 0.6, 0.7]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.5, 0.6, 0.7]]]텐서 초기화
데이터로부터 직접 생성
데이터로부터 직접 텐서를 생성할 수 있는데, 데이터의 자료형은 자동으로 유추한다.
data = [[1,2], [3,4]]
x_data = torch.tensor(data) # print시 tensor([[1, 2], [3, 4]])Numpy 배열로부터 생성
np_array = np.array(data)
x_np = torch.from_numpy(np_array)다른 텐서로부터 생성
x_ones = torch.ones_like(x_data) # x_data의 속성을 유지합니다.
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float) # x_data의 속성을 덮어씁니다.
print(f"Random Tensor: \n {x_rand} \n")Ones Tensor:
tensor([[1, 1],
[1, 1]])
Random Tensor:
tensor([[0.8823, 0.9150],
[0.3829, 0.9593]])random or constant 값 사용
shape = (2, 3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")Random Tensor:
tensor([[0.3904, 0.6009, 0.2566],
[0.7936, 0.9408, 0.1332]])
Ones Tensor:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])텐서의 속성 (Attribute)
텐서의 속성은 shape, datatype 및 어느 장치에 저장되는지 나타낸다.
tensor = torch.rand(3, 4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")텐서 벡터의 Rank, Shape
ndim은 몇 차원인지를 설명해주고, shape는 크기를 설명한다.
t = np.array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.], [10., 11., 12.]])
print('Rank of t: ', t.ndim) # Rank(차원)
print('Shape of t: ', t.shape)Rank of t: 2
Shape of t: (4, 3)텐서 연산 (Operation)
https://pytorch.org/docs/stable/torch.html 해당 링크의 텐서 연산들을 수행할 수 있다. 각 연산들은 모두 GPU에서 실행할 수 있다.
Numpy 식의 표준 인덱싱, 슬라이싱
tensor = torch.ones(4, 4)
tensor[:,1] = 0
print(tensor)tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])torch.cat (더하기)
주어진 차원에 따라 텐서를 연결할 수 있다.
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)tensor([[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.]])torch.mul (곱하기)
# 요소별 곱(element-wise product)을 계산합니다
print(f"tensor.mul(tensor) \n {tensor.mul(tensor)} \n")
# 다른 문법:
print(f"tensor * tensor \n {tensor * tensor}")tensor.mul(tensor)
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
tensor * tensor
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])두 텐서 간의 행렬 곱(matrix multiplication)은 다음과 같이 사용할 수 있다.
행렬 곱셈을 모를 수도 있는 사람들을 위해 설명하면, 행렬 곱셈은 전제 조건이 갖춰져야 한다.
“두 행렬 A와 B가 있을 때, A의 열의 개수 = B의 행의 개수”
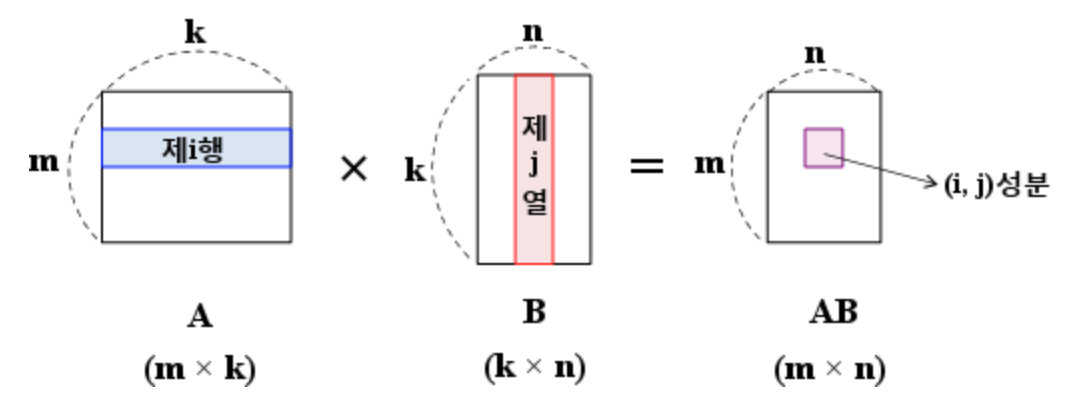
예시를 들면 다음과 같이 계산된다.
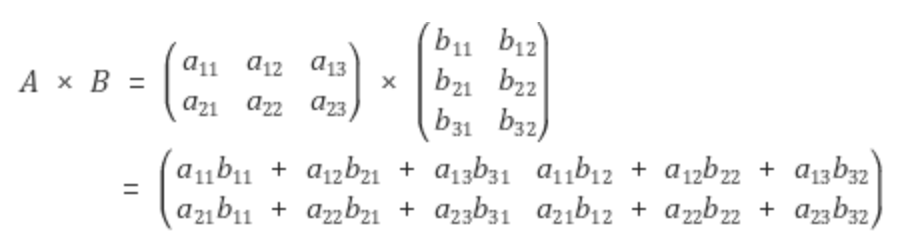
위 식을 본다면, 행렬 A는 2x3 행렬, B는 3x2 행렬이다. 그렇기에, 결과는 2x2행렬이 된다.
print(f"tensor.matmul(tensor.T) \n {tensor.matmul(tensor.T)} \n")
# 다른 문법:
print(f"tensor @ tensor.T \n {tensor @ tensor.T}")tensor.matmul(tensor.T)
tensor([[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.]])
tensor @ tensor.T
tensor([[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.]])→ 나누기 (torch.div)도 같은 곱셈과 같은 코드로 작성해 수행된다.
평균(mean)
보통은 전체 행렬의 평균으로 값이 나온다. 다만, 다른 식과 같이 dim옵션을 준다면, 그 부분에 해당해서만 수행한다.
t = torch.FloatTensor([[1, 2], [3, 4]])
print(t.mean())tensor(2.5000)덮어쓰기 연산(in-place)
접미사를 갖는 경우, 바꿔치기 연산이다. ex) x.copy()나 x.t_()는 x를 변경한다.
print(tensor, "\n")
tensor.add_(5)
print(tensor)tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
tensor([[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.]])덮어쓰기 연산의 경우, 메모리를 일부 절약할 수 있지만, 기록이 삭제되어 도함수(미분) 계산에 문제가 발생할 수 있기에 권장하지 않는다. 그렇기에, 별도의 변수로 저장을….
번외1, 브로드캐스팅 (BroadCasting)
딥러닝을 수행할 때, 불가피하게 크기가 다른 행렬 또는 텐서에 대해 사칙 연산을 수행하는 경우가 있는데, 자동으로 크기를 맞춰서 연산을 수행하게 만드는 기능을 말한다.
다만, 자동으로 실행되는 기능이기에 주의해야 한다. 원하는 결과가 나오지 않았을 때, 어디에서 문제가 발생했는지 확인할 수 없기 때문이다.
예시 코드는 다음과 같다.
# 2 x 1 Vector + 1 x 2 Vector
m1 = torch.FloatTensor([[1, 2]])
m2 = torch.FloatTensor([[3], [4]])
print(m1 + m2)[1, 2]
==> [[1, 2],
[1, 2]]
[3]
[4]
==> [[3, 3],
[4, 4]]번외2, Max, Argmax
max는 원소의 최대값을 반환하고, Argmax는 최대값을 가진 인덱스를 반환한다.
t = torch.FloatTensor([[1, 2], [3, 4]])
print(t.max(dim=0)) # Returns two values: max and argmax
print('Max: ', t.max(dim=0)[0])
print('Argmax: ', t.max(dim=0)[1])(tensor([3., 4.]), tensor([1, 1]))
Max: tensor([3., 4.])
Argmax: tensor([1, 1])Numpy 변환 (Bridge)
CPU 상의 텐서와 Numpy 배열은 메모리 공간을 공유하기에, 하나를 변경하면 다른 하나도 변경되는 특징을 가지고 있다.
텐서 → Numpy
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")t: tensor([1., 1., 1., 1., 1.])
n: [1. 1. 1. 1. 1.]Numpy → Tensor
n = np.ones(5)
t = torch.from_numpy(n)
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
n: [2. 2. 2. 2. 2.]텐서 만들때 주로 사용하는 코드
torch.empty(x, y)= x * y 사이즈의 요소들의 값이 초기화 되지 않은 행렬 반환 (무조건 0으로)torch.rand(x, y): x * y 사이즈의 요소들이 0 ~ 1 사이의 랜덤한 값으로 초기화 된 행렬 반환.torch.randn(x, y): x * y 사이즈의 요소들이 정규분포 그래프 상의 랜덤한 값으로 초기화 된 행렬 반환.torch.zeros(x, y, dtype=type): x * y 사이즈의 요소들이 0으로 초기화 된 행렬 반환, 요소들은 type에 맞게 초기화 된다.torch.ones(x, y, dtype=type): x * y 사이즈의 요소들이 1으로 초기화 된 행렬 반환, 요소들은 type에 맞게 초기화 된다.torch.tensor(iterable): iterable한 객체를 Tensor 객체로 변환한다.torch.zeros_like(tensor, dtype=type): 파라미터로 들어 간 Tensor 객체의 사이즈과 똑같은 행렬을 반환하며, 요소들은 0으로 초기화 되어 있다.torch.ones_like(tensor, dtype=type): 파라미터로 들어 간 Tensor 객체의 사이즈과 똑같은 행렬을 반환하며, 요소들은 1으로 초기화 되어 있다.torch.randn_like(tensor, dtype=type): 파라미터로 들어 간 Tensor 객체의 사이즈과 똑같은 행렬을 반환하며, 요소들은 정규분포 그래프 상의 랜덤한 값으로 초기화 되어 있다.
View (매우 중요)
Numpy에서 reshape와 같은 기능을 수행한다고 볼 수 있다. 원소의 수를 유지하면서, 텐서의 크기를 변경하는 역할을 수행한다.
t = np.array([[[0, 1, 2],
[3, 4, 5]],
[[6, 7, 8],
[9, 10, 11]]])
ft = torch.FloatTensor(t)
이러한 3차원 크기의 텐서는 (2,2,3)의 크기를 가지고 있다고 가정한다.
텐서 차원 변경
3차원 텐서에서 2차원 텐서로 변경할 때, 다음과 같이 작성할 수 있다.
print(ft.view([-1, 3])) # ft라는 텐서를 (?, 3)의 크기로 변경
print(ft.view([-1, 3]).shape)tensor([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.],
[ 9., 10., 11.]])
torch.Size([4, 3])여기서, view([-1,3])은, -1은 첫번째 차원의 경우, 사용자가 잘 몰라서 토치에 맡기는 것이고, 3은 두번째 차원의 길이는 3을 가지도록 설정하는 것이다. 즉, 현재의 (2,2,3)을 2차원 텐서로 변경하되 (?,3)으로 변경시키는 것을 말한다.
view는 다음과 같은 규칙을 가진다.
- 변경 전, 후의 텐서 안의 원소의 개수는 유지되어야 한다.
- view는 size가 -1로 설정되면, 다른 차원으로부터 해당 값을 유추해야 한다.
3차원에서 3차원으로 변경할 때도 다음과 같이 수행한다.
print(ft.view([-1, 1, 3]))
print(ft.view([-1, 1, 3]).shape)tensor([[[ 0., 1., 2.]],
[[ 3., 4., 5.]],
[[ 6., 7., 8.]],
[[ 9., 10., 11.]]])
torch.Size([4, 1, 3])기타 자주 활용되는 함수
squeeze
차원이 1인 경우, 해당 차원을 제거하는 기능을 수행한다. 별도의 차원을 설정하지 않으면, 1인 차원은 모두 제거한다.
예시 코드는 다음과 같다.
ft = torch.FloatTensor([[0], [1], [2]]) # torch.Size([3, 1])
print(ft.squeeze())
print(ft.squeeze().shape)tensor([0., 1., 2.])
torch.Size([3])원래 (3x1)의 크기를 가지지만, 두번째 차원이 1이므로 squeeze를 통해 (3,)의 차원을 가지는 텐서로 변경된다.
실제 딥러닝 과정에서, (3, 1, 20, 128)의 차원을 가지는 부분이 있다. 여기서 Squeeze를 수행한다면, (3, 20, 128)이 되는 것이다. 단, 주의할 점은 batch가 1이라면, batch의 차원도 없애버릴 수 있기에, 주의해야 한다. 이것 때문에, Validation에서 주로 에러가 발생한다.
unsqueeze
특정 위치에 1인 차원을 추가하는 기능을 수행한다. 예시는 다음과 같다.
ft = torch.Tensor([0, 1, 2]) # torch.Size([3])
print(ft.unsqueeze(0)) # 인덱스가 0부터 시작하므로 0은 첫번째 차원을 의미한다.
print(ft.unsqueeze(0).shape)tensor([[0., 1., 2.]])
torch.Size([1, 3])다른 예시 코드도 같이 설명하면 다음과 같다.
x = torch.rand(3, 20, 128)
x = x.unsqueeze(dim=1) #[3, 20, 128] -> [3, 1, 20, 128]Type Casting (텐서의 자료형)
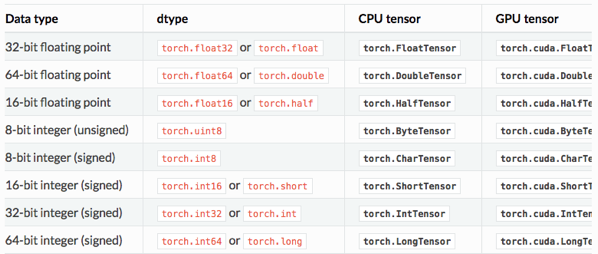
Type Casting은 자료형을 변환하는 것을 말한다.
lt = torch.LongTensor([1, 2, 3, 4])
print(lt)
print(lt.float())
------------------------
tensor([1, 2, 3, 4])
tensor([1., 2., 3., 4.])
bt = torch.ByteTensor([True, False, False, True])
print(bt)
print(bt.long())
print(bt.float())
----------------------------------------
tensor([1, 0, 0, 1], dtype=torch.uint8)
tensor([1, 0, 0, 1])
tensor([1., 0., 0., 1.])연결하기 (concatenate) → cat
우선 (2x2) 크기의 텐서 2개가 있다고 가정한다.
x = torch.FloatTensor([[1, 2], [3, 4]])
y = torch.FloatTensor([[5, 6], [7, 8]])두 텐서를 torch.cat을 통해서 연결할 수 있다. 그런데 이제, 어떤 차원을 늘릴 것인지 설정할 수 있다.
위의 x, y 두개의 행렬의 경우,
dim=0이면 두 개의 2x2 텐서가 4x2 텐서가 된다.
print(torch.cat([x, y], dim=0))tensor([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.]])dim=1을 인자로 준다면, 두 개의 2x2 텐서가 2x4 텐서가 된다.
print(torch.cat([x, y], dim=1))tensor([[1., 2., 5., 6.],
[3., 4., 7., 8.]])- 딥 러닝에서는 주로 모델의 입력 또는 중간 연산에서 두 개의 텐서를 연결하는 경우가 많은데, 두 텐서를 연결해서 입력으로 사용하는 것은 두 가지의 정보를 모두 사용한다는 의미를 가지고 있다.
Stacking
Concatenate의 또다른 방법이다. 단, Stacking은 순차적으로 쌓는 것을 의미한다.
x = torch.FloatTensor([1, 4])
y = torch.FloatTensor([2, 5])
z = torch.FloatTensor([3, 6])다음과 같이 3개의 동일한 (2,) 차원의 벡터가 있을 때, stack을 적용한다면
print(torch.stack([x, y, z]))
-------------------------------
tensor([[1., 4.],
[2., 5.],
[3., 6.]])다음과 같이 3개의 벡터가 순차적으로 쌓여 3 x 2 텐서가 된 것을 보여준다.
dim=1을 적용해 옆으로 쌓는다면(*실제로는 2번째 차원 증가) 다음과 같이 결과가 나온다.
print(torch.stack([x, y, z], dim=1))
------------------------------------
tensor([[1., 2., 3.],
[4., 5., 6.]])3개의 벡터가 스태킹되어 2 x 3 텐서가 된다.
chunk
하나의 텐서를 여러 개로 나눌 때 사용한다. 여기서 몇개의 텐서로 나눌 것인지에 대해서 입력을 해줘야 한다.
x = torch.rand(3,6)
t1, t2, t3 = torch.chunk(x, 3, dim = 1) ## x를 3개로 나눈다.
print(x)
print("------------------------------------------------------------------")
print(t1)
print("------------------------------------------------------------------")
print(t2)
print("------------------------------------------------------------------")
print(t3)tensor([[0.6757, 0.1670, 0.8002, 0.3195, 0.2859, 0.1874],
[0.5722, 0.7830, 0.6999, 0.7082, 0.5811, 0.4180],
[0.4047, 0.6115, 0.0471, 0.0122, 0.2065, 0.8178]])
------------------------------------------------------------------
tensor([[0.6757, 0.1670],
[0.5722, 0.7830],
[0.4047, 0.6115]])
------------------------------------------------------------------
tensor([[0.8002, 0.3195],
[0.6999, 0.7082],
[0.0471, 0.0122]])
------------------------------------------------------------------
tensor([[0.2859, 0.1874],
[0.5811, 0.4180],
[0.2065, 0.8178]])여기에는 추가로, 17개의 행이 있을 때, 4개로 나누고 싶다면, 마지막 데이터가 부족한 경우 그냥 남는 데이터들만 내보내는 과정을 수행한다.
x = torch.FloatTensor(17,4)
chunks = x.chunk(4, dim = 0) ## 0번째 축을 기준으로 4덩이를 나누고 싶다.
## chunk(4, dim = 0) ==> chunk(4(n), dim = 0)
## 각 data set마다 최대 5개를 갖고 있음(0번째 축 이 17)
## 마지막 데이터가 부족한 경우 그냥 내보냄
for c in chunks:
print(c.size()) torch.Size([5, 4])
torch.Size([5, 4])
torch.Size([5, 4])
torch.Size([2, 4])ones_like, zeros_like
ones_like는 동일한 크기지만, 1로만 값이 채워진 텐서를 생성한다.
zeros_like는 마찬가지로, 동일한 크기를 지니지만, 0으로만 값이 채워진 텐서를 생성한다.
x = torch.FloatTensor([[0, 1, 2], [2, 1, 0]])
print(torch.ones_like(x)) # 입력 텐서와 크기를 동일하게 하면서 값을 1로 채우기
print(torch.zeros_like(x)) # 입력 텐서와 크기를 동일하게 하면서 값을 0으로 채우기
---------------------------------------------------------
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[0., 0., 0.],
[0., 0., 0.]])참고
https://meaningful96.github.io/pytorch/pytorch1/#텐서의-자료형
https://gloomysky.tistory.com/16
https://meaningful96.github.io/pytorch/pytorch2/#91-텐서간-분할---chunk
