1. Problem Statement
기존 Sequential Recommendation은 크게 2가지 단계로 진행되었는데, 이는 각각의 한계점을 가진다.
표현 방식에서의 문제
-
ID-based Representation
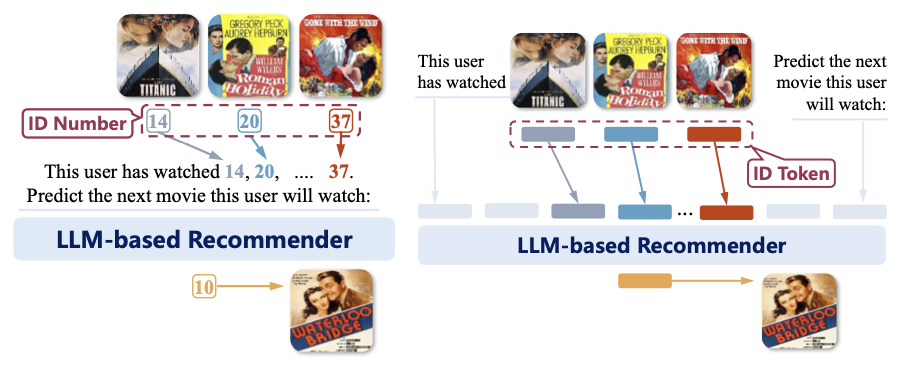
- 각 Item → Random하게 초기화된 ID Token으로 표현
- 아이템의 textual 특징을 활용하지 못하고, LLM과의 통합에도 어려움을 가짐. → NLP Task에 잘 맞지 않음 (LLM의 경우는, LLM Task에 최적화)
-
Text-based Representation

- 각 Item에 대한 Title, Description 등을 텍스트 메타데이터로 활용
- 사용자의 순차적 행동 패턴(Behavioral patterns)를 반영하지 못하는 문제 → 추천 품질이 저하되는 현상
LLM을 활용한 추천의 비효율성에 대한 문제
- LLM을 추천 모델 자체로 사용하는 경우
- Training from Scratch (추천 데이터 이용한 사전 학습), Fine-Tuning, Prompting, In-context Learning 등으로 활용
- 기존의 추천 모델이 학습한 행동 패턴을 고려하지 않고, 무시하는 경향이 있음
- LLM을 Enhancer(보완하는 도구)로만 사용하는 경우
- LLM으로 기존 순차 추천 모델을 보완하는 역할로 사용
- 기존 추천 모델이 예측한 결과를 LLM이 post-processing하는 방식 등으로 사용
- 그렇지만, 실제 추천 프로세스는 여전히 기존 모델이 수행, LLM의 핵심적인 추론 능력을 제대로 활용하지 못함
→ 이러한 문제를 보완하기 위해, LLaRA는 Traditional Sequence Recommendation Model과 LLM을 정렬하는 방식을 선택한다.
앞서 언급한 문제를 해결하기 위해,
- 기존 Traditional Model이 학습한 순차적 행동 패턴 활용 (ID-based Embedding)
- LLM이 가지고 있는 지식, 추론 능력을 함께 사용 (Text-based Representation)
2가지의 방법을 사용하는 Hybrid Prompting 방식을 채택한다.
추가로, Curriculum Tuning 전략을 활용해 LLM이 점진적으로 행동 패턴을 학습하도록 설계했다.
이로써, 기존 LLM 기반 추천들보다 안정적이고 효과적인 추천 성능을 달성한다.
2. Model Structure
Sequential Recommender System은 여러 아이템 시퀀스 을 바탕으로 다음 아이템 을 예측하는 방식을 사용한다.
LLaRA에서는, 간략하게 말하면 단순 text-based prompting이 아닌, 사용자의 행동 표현을 LLM의 언어 공간과 정렬시키는 Hybrid Prompting을 사용한다.
추가로, Curriculum Learning을 사용하는데, Text-based Prompt에서 Hybrid Prompt로 전환하는 방식으로 진행한다. 이를 통해서 LLM이 추천 매커니즘을 익히고, Traditional Recommendation System의 행동 지식을 학습할 수 있도록 한다.
우선, LLaRA는 다음의 과정을 거치며 추천을 진행하게 된다.
1) Item Representation
Text Token Representation
Item의 Title, Description 등의 textual features은 LLM이 보유한 지식을 활용하는데 필요한 요소다. 이를 Textual Token으로 표현하게 된다면 다음의 식으로 표현한다.
여기서 LLM-TKZ()는 LLM의 Tokenizer, Word Embedding Layer을 나타내는데, 이는 텍스트 데이터를 LLM이 처리할 수 있는 토큰으로 변환하는 것이다.
Behavior Token Representation
기존의 전통적인 순차 추천 모델은, 사용자의 행동 패턴을 학습한 ID 기반 아이템 임베딩을 활용한다. 여기서 특정 아이템 에 대해 순차 추천 모델에서 학습된 ID-based Representation은 다음과 같은 식으로 정의한다.
여기서 SR-EMB()는 전통적인 순차 추천 모델에서 아이템 임베딩을 생성하는 함수를 말하고, 는 추천 모델의 trainable projector의 파라미터이다.
결론적으로, 이는 특정 아이템 의 차원 임베딩 벡터가 된다. ()
다만, 이는 LLM이 자연어 형식으로 이해하는 것이 아니기에, 텍스트 기반의 LLM 입력과 직접적으로 호환되지 않는다. → 이를 해결하기 위해 ID-based 표현을 LLM의 언어 공간과 정렬하는 과정이 필요하다.
여기서는, ID 기반 표현이 텍스트 데이터와는 별도의 Modality라는 점을 고려해야 한다. 이를 위해, SR2LLM이라는 모듈을 사용해서 정렬한다.
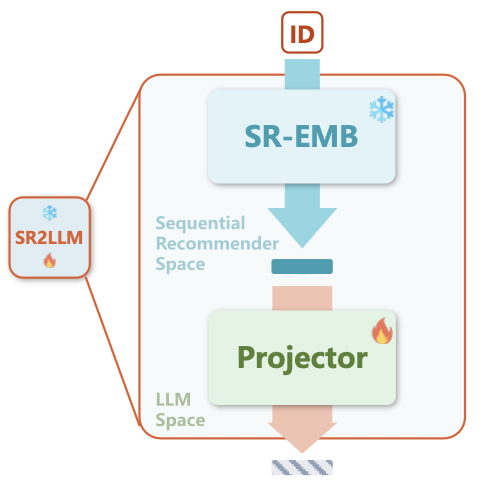
- SR2LLM : ID 기반 임베딩을 LLM이 처리할 수 있는 형태로 변환하는 Projector 역할 수행
여기서 아이템 기반의 표현을 LLM 공간으로 매핑하는 과정은 다음과 같다.
Proj는 Multi Layer Perceptron을 의미하고, 는 Projector의 학습 가능한 파라미터이다. 결론적으로, 는 ID 기반 표현을 LLM의 토큰 공간에 적용한 것이다.
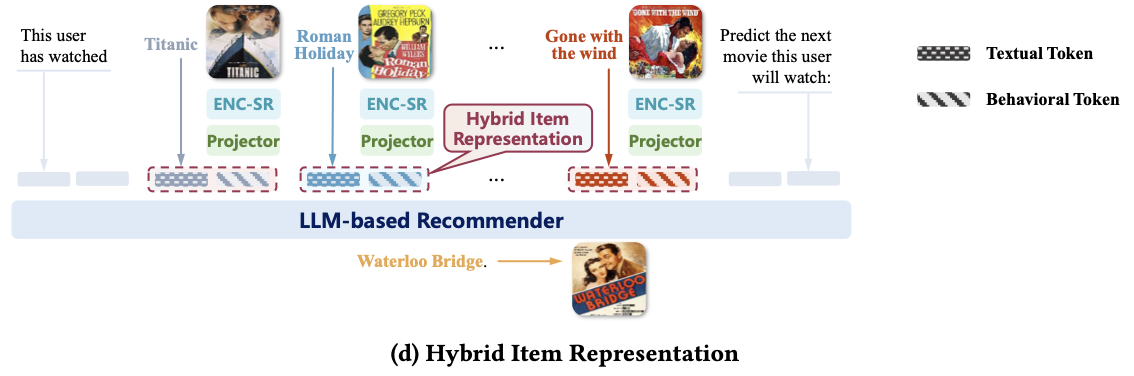
Hybrid Token Representation
ID 기반, Text 기반 데이터의 장점을 활용하기 위해, 이를 결합한 하이브리드 토큰 표현으로 결합한다. 이는 다음과 같은 식으로 사용된다.
결과적으로, 아이템 의 하이브리드 표현은 Text, Behavior 특징을 모두 포함하는 표현이 된다.
2) Hybrid Prompt Design

순차적 Interaction 데이터를 LLM이 이해할 수 있도록, Text-Only에서 Hybrid Prompting 방식으로 변환하는 과정으로 작성한다.
Text-Only Prompting
이 과정에서는 아이템을 Text Metadata로 설명한다.
- Task Definition : 모델이 수행해야 하는 작업 정의 ex) “predict the next movie this user will watch”
- Interaction Sequence : 사용자가 과거에 본 item 나열 ex) “Titanic , Roman Holiday , . . . , Gone with the wind ”
- Candidate set : 후보 아이템 집합 입력 ex) “The Wizard of Oz , Braveheart , . . . , Waterloo Bridge , . . . , Batman & Robin ”
여기서 는 Placeholder Token, 이후 행동 정보를 삽입할 공간을 말한다.
Hybrid Prompting
LLM이 순차 추천 모델이 학습한 행동 패턴을 반영할 수 있도록, 도입한다. 이 과정에서는 Textual, Behavioral Features들을 결합하여 프롬프트를 구성한다.
- Task Definition : 모델이 수행해야 하는 작업 정의 ex) “predict the next movie this user will watch”
- Interaction Sequence : 사용자가 과거에 본 item들을 텍스트 토큰과 행동 토큰을 결합한 형태로 표현 ex) "Titanic , Roman Holiday , ... Gone with the Wind ”
- Candidate set : 후보 아이템 집합을 하이브리드 형식으로 입력 ex) "The Wizard of Oz , Braveheart , ... Batman & Robin ”
기존의 Text-Only 방식은 사용자 행동 패턴을 반영하지 못하는 단점을 가지고 있지만, 하이브리드 프롬프팅은 LLM이 사용자의 행동 패턴과 아이템 간의 연관성을 동시에 학습할 수 있도록 도와준다.
3) Curriculum Prompt Tuning
LLM은 순차 추천 모델의 행동 임베딩을 이해하는 것에 장애물이 있다. 즉, 여기에서 Text-Only 방식은 LLM의 학습 방식과 같지만, 하이브리드 방식은 LLM이 학습하지 않은 새로운 형태의 데이터를 포함하기에, 새로운 Modality에 적응하는 것이 필요하다. 이를 위해 Curriculum Learning을 적용하여 Text 기반 데이터로 학습을 먼저 시작, 점진적으로 하이브리드 프롬프팅으로 전환하도록 유도한다.
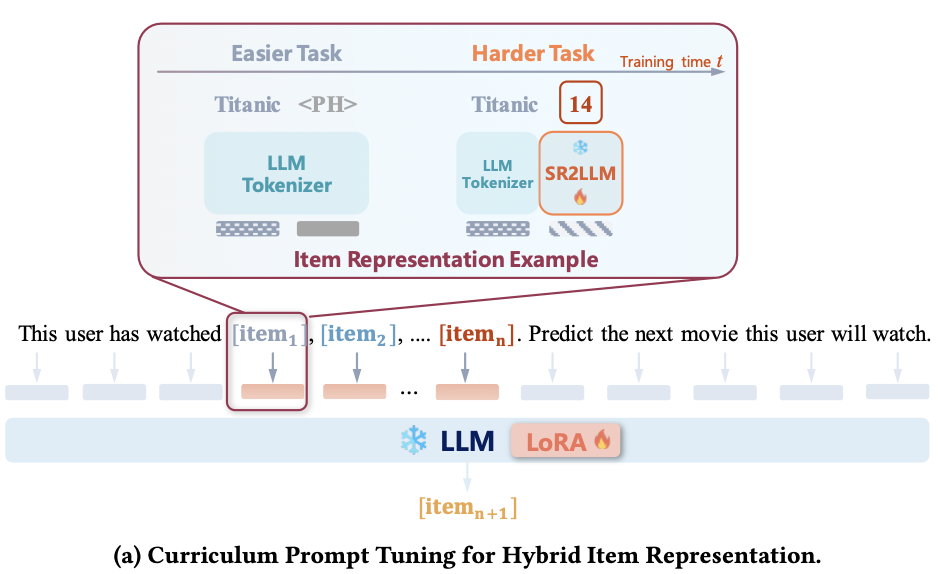
Curriculum Learning은 크게 3개의 단계로 구성된다
Complexity Assessment (복잡도 평가)
학습의 난이도를 평가해, Easy 단계에서 Hard 단계로 전환하는 전략을 수립한다. 여기에서 쉬운 태스크는 Text-Only, 어려운 태스크는 하이브리드 방식이다.
여기서 각 태스크의 손실 함수는 다음과 같이 정의한다.
위 식은 Instruction Tuning의 식에서 변형된 것이다.
여기서 (), ()는 각 방식의 input, output이고, 는 Sequential Recommender의 projector와 임베딩 레이어의 파라미터이다.
Scheduler Formulation (학습 스케줄 설계)
처음에는 쉬운 태스크(Text-only)만 학습하고, 학습이 진행될수록 하이브리드 프롬프팅을 점진적으로 도입하는 방식을 사용한다.
여기서 난이도 조절 함수 를 정의해 시간이 지날수록 어려운 태스크를 학습할 확률이 증가한다.
- : 현재 training time
- : 쉬운 태스크를 학습할 확률
- : 어려운 태스크를 학습할 확률
Training Execution
이 과정에서는 LoRA를 활용해서 LLM을 효율적으로 튜닝한다. 여기서 Indicator을 활용해서 어떻게 학습시킬지를 정의한다.
쉬운 태스크에서 어려운 태스크로 점진적으로 전환하는 Curriculum Learning을 적용하고, 순차 추천 모델에서 추출된 행동 패턴을 점진적으로 학습할 수 있도록 유도한다.
최종 목표 함수는 다음과 같다.
이 과정을 통해 LLM이 순차 추천 모델의 행동 패턴을 자연스럽게 학습할 수 있도록 유도하여 추천 모델의 성능을 향상시키는 것을 목표로 한다.
초기 단계에서는 텍스트 기반 방식으로 추천 개념을 익히고, 이후에는 사용자 패턴을 학습하는 방식이다.
3. Experiment
평가 부분
RQ1 : LLaRA가 기존 전통적 추천 모델과 LLM 기반 추천 방법과 비교할 때, 어떤 성능을 보이는가?
RQ2 : 하이브리드 프롬프팅은 기존 아이템 표현 방식과 비교했을 때 어떤 성능 차이가 있는가?
RQ3 : Curriculum Learning은 다른 Modality Injection 방법과 비교할 때, 어떤 효과를 보이는가?
- Experiment Data : MovieLens, Steam, LastFM
- Evaluation Metric : HitRatio@1, Valid Ratio
- Valid Ratio : LLaRA가 생성한 응답이 후보 아이템 내 존재하는 비율
- 비교 대상 모델
- Traditional Sequential Recommender System Model : GRU4Rec, SASRec, SASRec
- LLM Based : TALLRec, Llama2, GPT-4, MoRec
Performance Comparison (RQ1)
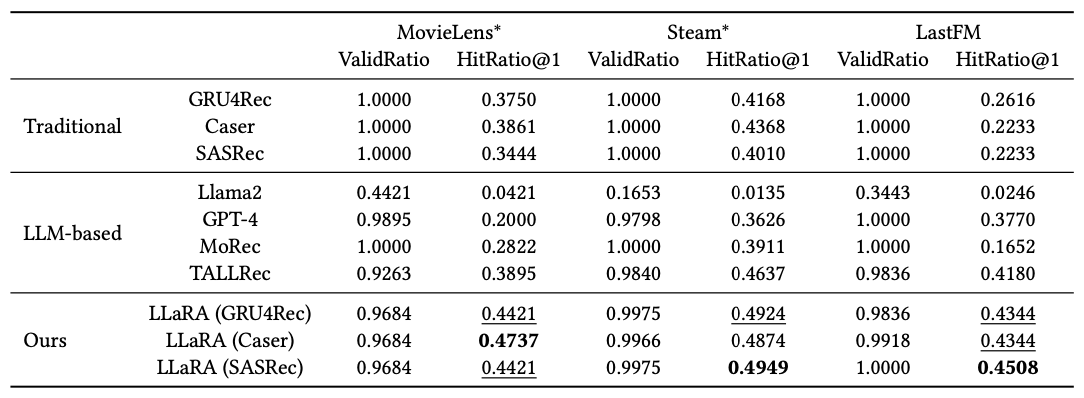
LLaRA 모델이 기존 순차 추천 모델들, LLM 기반 모델들보다 더 높은 HitRatio@1을 기록해서 우수한 성능을 보였다.
전통적인 순차 추천 모델은 행동 패턴을 학습하지만, 아이템의 의미적 정보를 담지 못하고, LLM 기반 방법은 추론 능력과 지식을 활용하지만, 순차적 행동 패턴을 반영하지 못한다.
반대로, LLaRA는 이 2개의 능력을 모두 활용하여 가장 높은 지표를 기록했고, 이는 행동 패턴과 의미 정보를 통합한 것이 성능 향상에 기여했다는 것을 보여준다.
Impact of Hybrid Item Representation (RQ2)
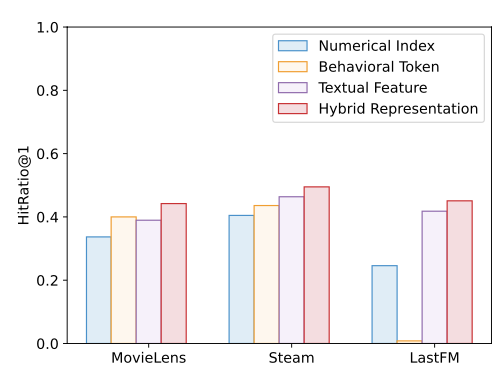
실험을 통해 하이브리드 방식이 가장 높은 성능을 보이는 것을 확인했다.
개별 방식의 결과를 설명하면,
- 숫자 인덱스(numerical index): LLM이 해당 ID에 대한 사전 정보를 학습하지 않으므로 추천 성능이 낮다.
- 행동 토큰(behavioral token): 순차 추천 모델에서 추출한 행동 패턴을 반영하지만, LLM의 지식을 활용하지 못한다.
- 텍스트 특징(textual feature): 아이템의 제목이나 설명을 활용하여 LLM의 의미적 이해를 돕지만, 사용자 행동 패턴을 반영하지 못한다.
- 하이브리드 표현(hybrid representation, LLaRA 적용 방식): 행동 패턴과 세계 지식을 결합하여 가장 효과적인 추천을 수행한 것을 확인했다.
Impact of Curriculum Prompt Tuning (RQ3)
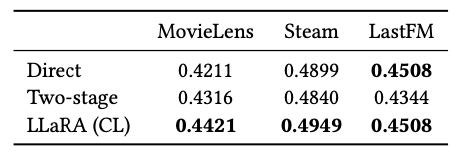
- Direct Training : 처음부터 하이브리드 프롬프팅을 사용해서, 복잡한 학습 과정으로 인해 최적의 성능을 달성하지 못했다.
- Two-stage Training : 먼저 텍스트 프롬프트로 학습을 진행한 이후, 하이브리드 프롬프트로 학습한 과정인데, 성능이 개선되기는 했지만, 최적화 과정이 부족했다.
- LLaRA : 텍스트 프롬프트에서 점진적으로 하이브리드 프롬프트로 이동하는 방식인데, 이것이 가장 높은 성능을 기록했다.
4. Conclusion
- 위 연구는 LLaRA를 통해 순차 추천 모델의 행동 패턴을 LLM에 점진적으로 도입하는 Curriculum Learning을 도입하여 기존 두 케이스의 문제를 보완했다.
- 실험을 통해 Curriculum Learning과 하이브리드 프롬프팅이 성능 향상에 있어 중요한 요수임을 알 수 있었고, LLM 지식과 행동 패턴 결합이 정확한 추천에 도움을 주는 것을 알 수 있다.
→ 결론적으로 LLM과 기존 추천 모델을 결합해 순차 추천 모델의 새로운 가능성을 제시했다.
