[Paper Review] LLM2Rec: Large Language Models Are Powerful Embedding Models for Sequential Recommendation
PAPER REVIEW
LLM2Rec 논문 KDD 2025에 Accept된 논문입니다.Problem Statement
LLM-based Sequential Recommendation (Hybrid)
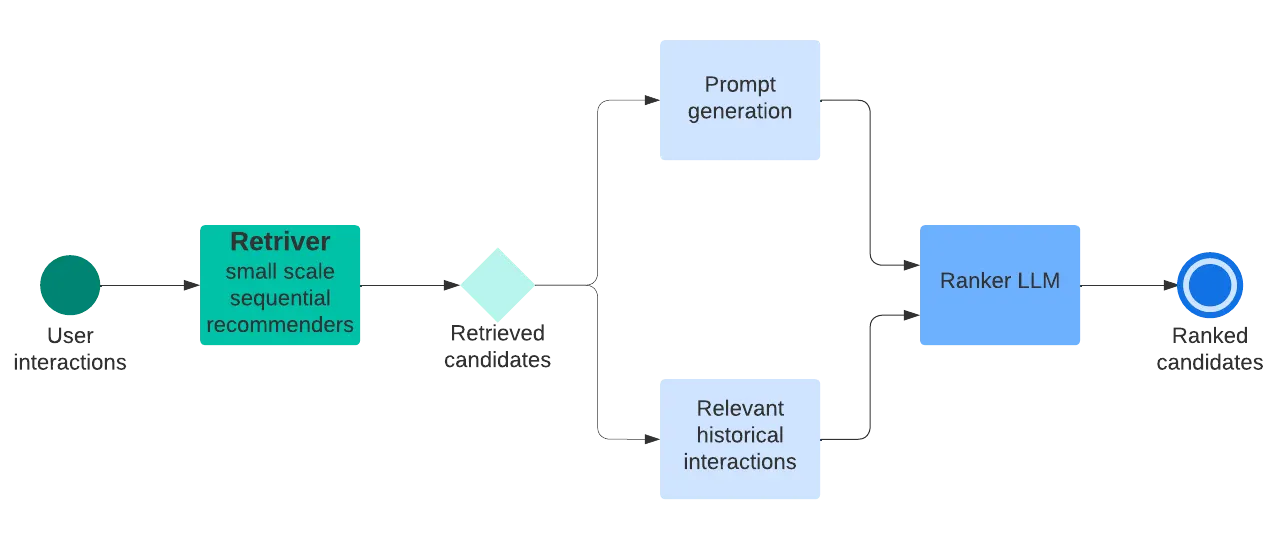
- LLM을 이용해서 이전 사용자 이력을 바탕으로 다음 아이템 추천
- 웜스타트 (상호작용 이력이 많은 사용자)에 취약한 문제점이 있어, 이를 반영하기 위해 CF 정보 + Semantic 정보를 결합하는 연구들이 많이 시도되고 있음.
- 이를 Hybrid Method라고 함. (semantic, CF 신호를 다양한 퓨전 전략을 사용해서 통합)
- Concatenation (단순 연결) : ID, semantic embedding 단순히 이어붙임
- Guidance : 텍스트 임베딩을 신호/정규화 손실로 써서 ID 임베딩 학습을 보조
- 하이브리드 융합 아키텍처 : ID와 텍스트 사이의 크로스/멀티모달 어텐션으로 상호작용을 학습해 가중 융합. 단순 concat보다 표현 교류가 풍부.
- Tuning to bridging spaces : 임베딩 모델 자체를 튜닝(특히 대조학습)해 CF 공간–의미(텍스트) 공간을 하나의 표현 공간으로 맞춤
- 이를 Hybrid Method라고 함. (semantic, CF 신호를 다양한 퓨전 전략을 사용해서 통합)
Previous Limitations
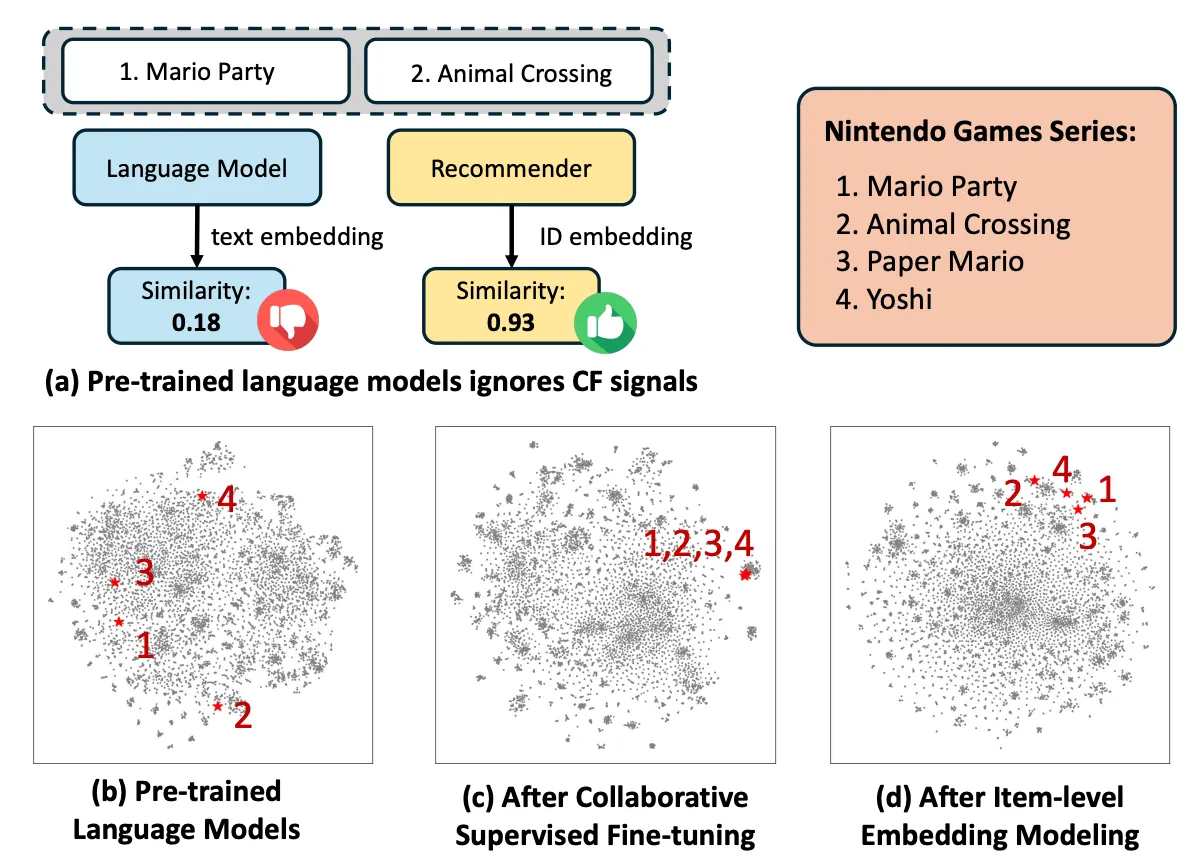
- 도메인 일반화에 취약 → 아직 Collaborative ID 의존성에서 아직 벗어나지 못함
- 아이템 의미. 사용자 행동 공간을 Concat, Cross Attention을 시도하더라도 단일 공간으로 정렬하기가 힘듦
- 의미 공간, 행동 공간의 불일치
- 두 공간을 하나의 통합된 공간으로 정렬하기 위한 방법들이 여러 제안되었지만, 이를 위해서는 대규모 학습 샘플이 필요하고, 큰 배치 크기가 필요해 학습에 제약 사항이 존재
- 최신 LLM의 성능을 이해, 추론 능력 등을 제대로 활용하지 못함.
→ 이러한 한계점을 극복하기 위해 LLM의 의미 이해와 CF 신호의 캡쳐 능력을 결합하는 것이 목표 (추천 특화 임베딩 모델)
Method
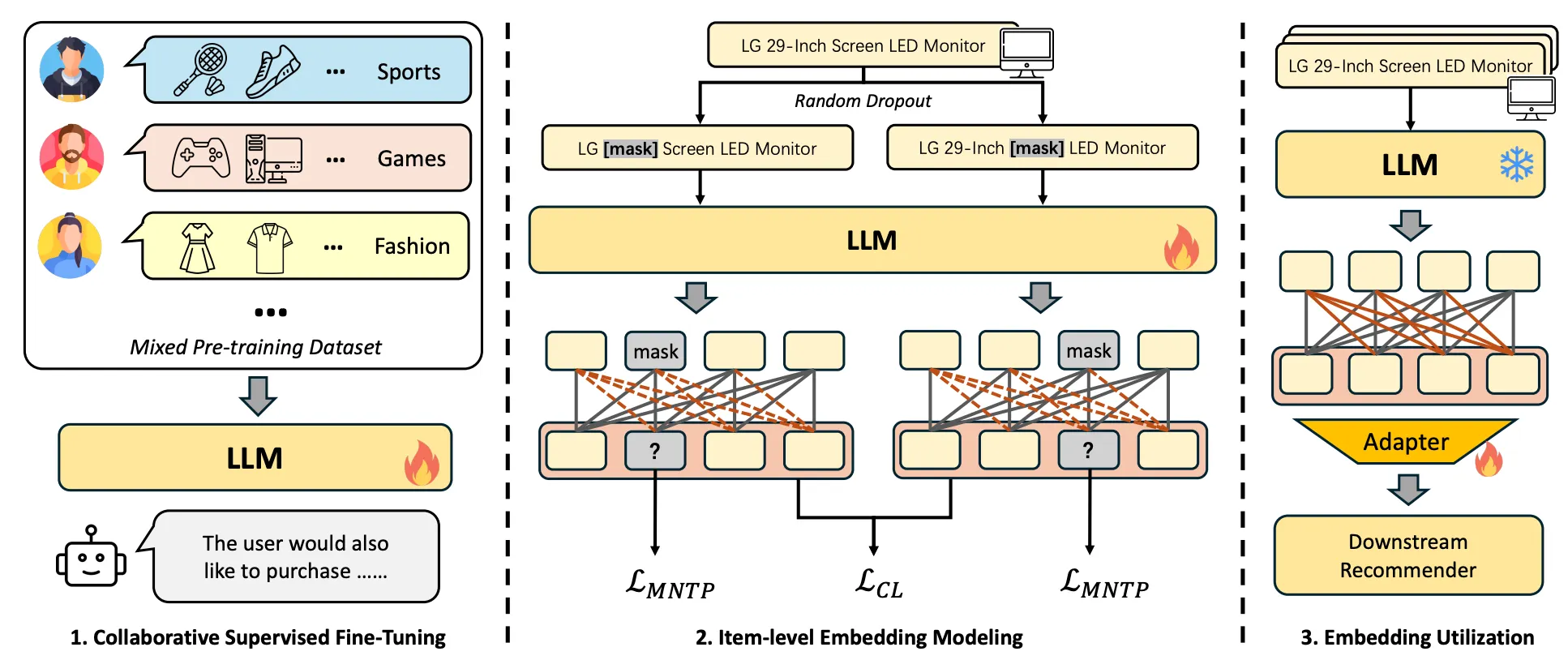
Collaborative Supervised Fine-tuning

- 추천 아이템을 활용한 instruction 생성
- Input : 사용자의 이전 상호작용 이력, Output : 다음 추천 아이템
- 과거에 본 아이템들의 제목 텍스트를 쉼표로 이어 붙인 시퀀스로 표현
- 같이 소비되는 아이템들이 무엇인지를 직접 학습하게 하므로, 자주 함께 등장하는 아이템들이 표현공간에서 가까워지도록 그라디언트가 유도
- 자기회귀(autoregressive) 방식으로 title의 토큰들을 순차 예측하도록 학습
- 사용자 상호작용 시퀀스 내의 다른 아이템들 사이 관계를 포착하는 것이 목표
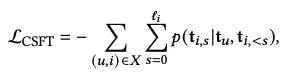
Item-level Embedding Modeling
마스킹된 다음 토큰 예측(MNTP, Masked Next Token Prediction)을 통해 양방향 어텐션을 가능하게 하고, 아이템 수준 대조 학습(item-level contrastive learning)을 적용하여 LLM이 임베딩 모델로 기능하도록 더욱 촉진
→ 사전 학습 목표를 토큰 수준에서 아이템 수준으로 명시적으로 전환하여, 구별 가능한 아이템 임베딩을 생성하면서도 CF 신호를 유지하도록
Reforming Decoder-only LLM to Encoder
- 인코더 구조와 디코더 기반 LLM의 지식을 바탕으로 item-level의 임베딩을 얻도록 LLM을 임베딩용 인코더로 재구성
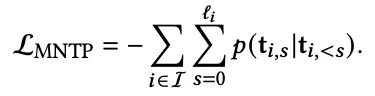
- 양방향 Attention, Masked Next Token Prediction으로 LLM 파인튜닝 진행
- 아이템 시퀀스를 입력으로 받아 미리 정한 비율만큼 토큰을 무작위로 마스킹 (20%)
- 사전 정의된 함수로 랜덤하게 토큰 마스킹 진행 → 양방향으로 Masked next token prediction 방식으로 LLM 학습
Bidirectional attention이 아이템 타이틀 내에 문맥적 정보를 포착하는 것을 가능하도록 함, 또한, MNTP는 LLM이 새로운 양방향 어텐션 마스크에 적응하도록 도움
Casual → Bidirectional attention
- Casual Attention은 토큰 임베딩 생성 과정에서 다음 토큰으로의 접근을 막음 → 다음(미래)의 토큰을 볼 수 없어서 풍부한 반영이 되지 않음
- Casual mask를 해제하고, 앞 뒤 문맥을 모두 볼 수 있는 Biridectional Attention 적용해 아이템 내부 토큰 문맥만 보고 임베딩 품질을 보완함.
- 양방향 문맥을 활용해 가려진 [mask] 부분 예측
- 단일 아이템 내부 정보에만 집중하여 item-level 임베딩을 정렬하는 것이 목표
token level → item level로 변환, 구별가능한 임베딩을 생성하면서 CF 신호를 보존하도록 함.
Item-level Contrastive Learning
- Downstream 추천 작업에 더 유리하고 보편적인 item-level 임베딩 생성이 목표
- token-level 임베딩의 mean pooling을 적용하는 것이 가장 직관적
- 이러한 평균 풀링을 강화하기 위해 item-level Contrastive learning 적용
Token → Item level embedding
- input item은 마스킹을 랜덤으로 적용해 독립적으로 LLM을 2번 통과함
- 2개의 masked embedding 생성
- Contrastive learning을 적용해 최적화 진행
- InfoNCE 형태의 식으로, 동일 아이템은 가깝게, 다른 아이템은 더 멀리 학습 진행 (in-batch negative)
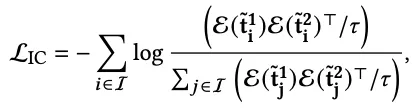
- 아이템 임베딩은 전체적 관점에서 학습되고, 다른 아이템과 대조됨으로써 고유성이 강화되는 효과
Optimization & Utilization
- Stage 1 : CSFT로 협업 신호 주입
- Stage 2 : MNTP, Item-level Contrastive learning으로 임베딩 생성 정렬
- casual → bidirectional mask
- 학습 종료 이후, linear adapter을 적용해 Downstream 학습 목적으로 최적화
- adapter을 거친 표현을 추천에 적용 → 다양한 도메인에도 적용할 수 있도록 함.
Experiments
Experiments Settings
- Pretrain : Amazon 6개 데이터셋을 혼합해 임베딩 모델에 대한 사전 학습 진행 (Games, Arts, Movies, Home, Electronics, Tools)
- Maximum history length : 10으로 제한
- Leave-one-out strategy 적용
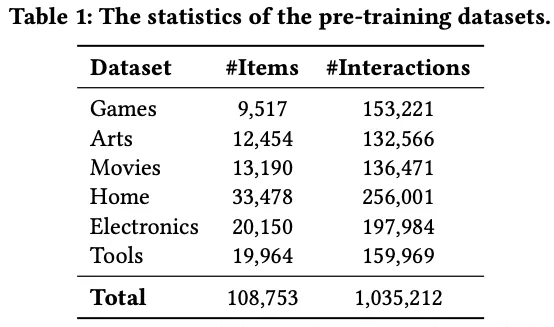
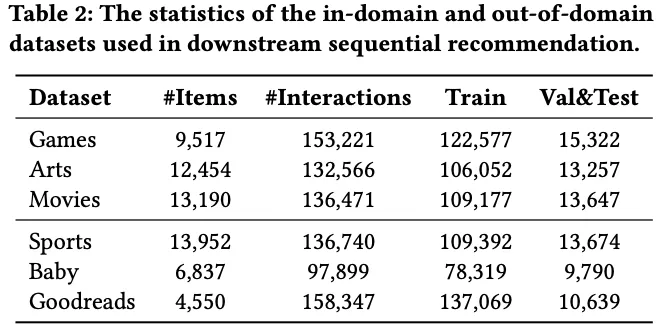
- Downstream 순차 추천 데이터셋 :
- In-domain : Games, Arts, Movies
- Out-domain : Sports, Baby, Goodreads
- Evaluation Metrics : Recall, NDCG @ 10, 20
- LLM : Qwen2-0.5B
- 랜덤하게 input token의 20%를 마스킹, LLM2Vec과 동일한 하이퍼파라미터 진행
- Early stop : 20
Overall Performance
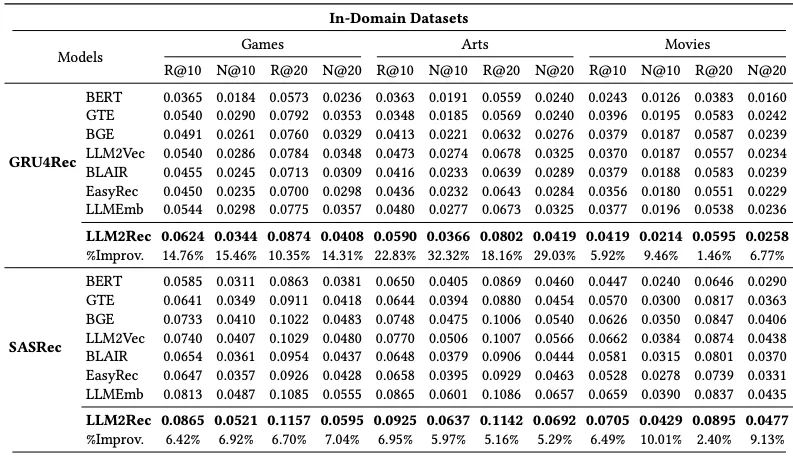
- In-domain에서 모든 비교 모델보다 가장 좋은 성능 도출
- 효과적으로 협업 정보를 포착함에 따라 성능 향상이 이루어짐
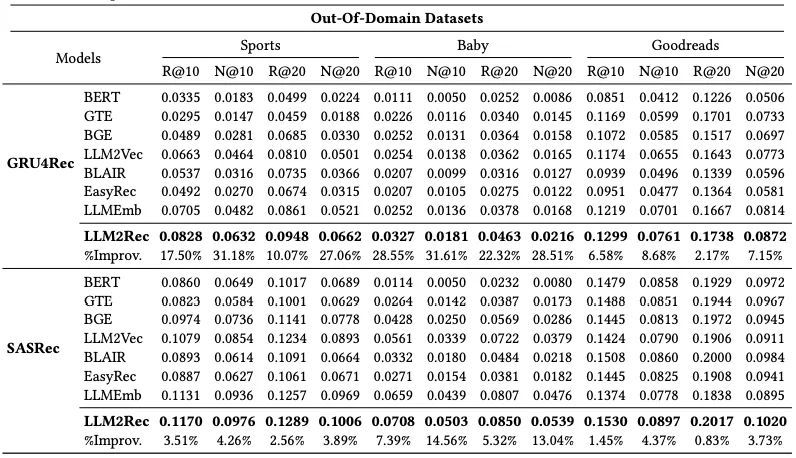
- Out-domain에서도 가장 높은 성능을 보여줌
- 다양한 추천 데이터로 학습하면 CF 인식과 도메인 밖 데이터의 일반화가 동시에 강화됨을 시사
→ 추천을 위한 일반화 생성된 임베딩이 CF 정보와 의미 이해를 바탕으로 높은 추천 성능을 보여줌
Ablation Study
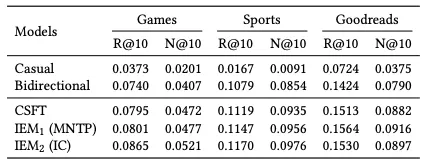
- CF Model : SASRec 사용
- In-domain : Games, Out-domain : Sports, Goodreads 사용
Ablation 1
- Casual : casual mask 유지, [EOS]의 마지막 hidden state로 아이템 임베딩을 만듦
- Bidirectional : casual mask 해제, 마지막 hidden state에 대해 mean pooling 진행
→ Bidirectional일 때, 일관되게 우수한 경향이 나옴, 효율적인 생성은 casual이 유리하지만, 성능 부분에서는 양방향 문맥이 더 적합
Ablation 2
- 단계별로 Bidirectional을 누적 적용했을 때의 성능 평가
- CSFT를 적용했을 때 가장 큰 성능 향상 제공, CF 포착의 중요성 확인
- IEM2 역시 높은 개선율을 보여줌 (단, Goodreads에서는 소폭 하락한 결과)
Model Study
Effect of Different LLM Backbones
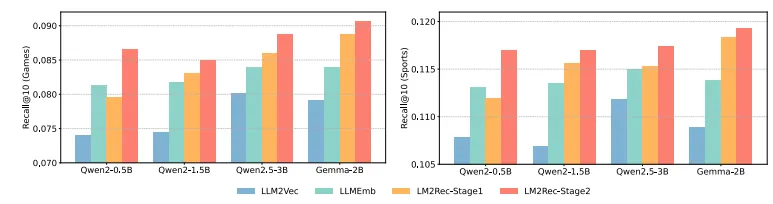
- LLM2Rec에서는 backbone의 선택이 성능에 영향을 미침
- 두 단계를 거칠수록 추천 성능이 일관되게 향상됨.
- 동일 backbone을 기준으로 비교한다면, LLM2Vec(범용 임베딩)보다 항상 앞서고, Stage 2까지 마치면 LLMEmb(추천 특화 임베딩)보다도 훨씬 더 우수한 성능을 보임
Effect of Mixed Dataset Training
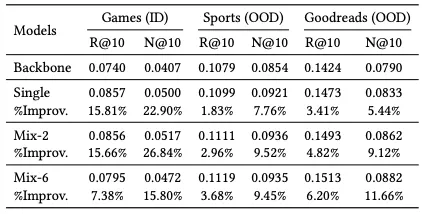
- 단일 카테고리로만 학습(Games) 시 In-domain 정확도가 높아지는 장점이 있음.
- 여러 카테고리를 함께 학습시키면 성능은 조금 떨어질 수 있지만, 일반화 성능이 크게 향상됨을 볼 수 있음.
- In-domain에는 집중 사전학습, Out-domain에는 multi-domain 혼합 학습이 유리
Efficiency Analysis
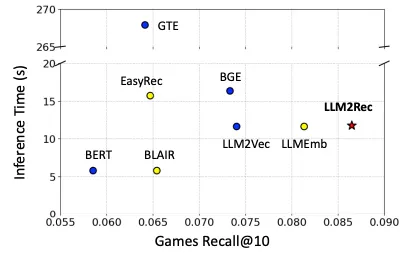
- Games 데이터셋의 title encoding에 걸리는 시간 측정
- 일반적으로 작은 모델의 경우는 빠르지만 성능이 낮고, 큰 모델의 경우는 성능이 좋지만, 추론 시간이 오래 걸림
- Qwen2-0.5B 기반의 LLM2Vec, LLMEmb 대비 낮은 비용, 높은 성능을 보임 → 효율성을 유지하면서 추천 특화 fine-tuning으로 높은 성능 달성해서 실용 부분에 유리
Contributions, Limitations
Contributions
- Hybrid 기반 방법론에서 문제되던 임베딩 공간 정렬 문제와 비용 문제를 해결하고, linear adapter로 범용 도메인 추천이 가능하도록 함
- 0.5B의 모델만으로도 다른 고사양의 LLM 이상으로 좋은 성능 도출
- CSFT를 통해 CF 정보를 LLM에 주입하고, 임베딩 변환, 추천까지 단일 LLM으로 모두 수행하는 부분에서 Novelty 존재
Limitations
- 아이템의 다른 정보 (description, category 등)를 활용하지 않아 텍스트 의미 표현 부분이 부족할 수 있음
- 사용자 정보가 충분히 반영되지 않아, 사용자 선호도를 파악하기 힘듦
- 특히, max_history_length를 10으로 제한해 최근 상호작용밖에 파악하지 못함
