🎯 사건의 발단
팀플 중이다. 스터데이
OAuth2 와 JWT 를 이용해서 Stateless 인증 환경을 구현했다.
코드를 본 멘토님은 두 가지 물음을 던졌다.
- 단일 서버인데 왜 토큰 관리만을 위해 Redis 를 쓰는가?
- 왜 특정 캐시 종류에 종속적인 코드를 작성했는가?
우리 프로젝트 실상에 적합한 기술을 적용하기 위해 각 물음에 답을 찾아봤다.
- 단일 서버라면, 로컬 캐시로도 충분하지 않을까?
- 캐시를 추상화하면, 여러 캐시를 섞어서 쓸 수 있지 않을까?
🔍 톺아보기
캐시 왜 씀?
핵심을 말하자면, 단일 서버 환경에서 토큰 관리를 가볍게 하기 위해서다.
원래는 토큰 관리에 REDIS 를 썼다고 했다.
REDIS 는 Remote Dictionary Server 의 약자다.
원격이 키워드다.
이건 마치 단독주택에 살면서 경비아저씨를 고용하는 것처럼 썩 말이 되지 않는 일이다.
단독주택에 살면, 집 안에 사는 가족 중에 한 명이 경비 역할을 수행하면 된다.
아니면, 경비 역할을 잘 할 수 있는 강아지를 한 마리 데려오는 것도 좋을 것 같다.
한 마디로 정리해서 서버 내 자원을 활용해서 토큰을 관리하는 것이 현재 상황에 더 적합하다고 생각한다.
그래서 로컬 캐시를 적용했다.
그럼 왜 카페인 캐시 씀?
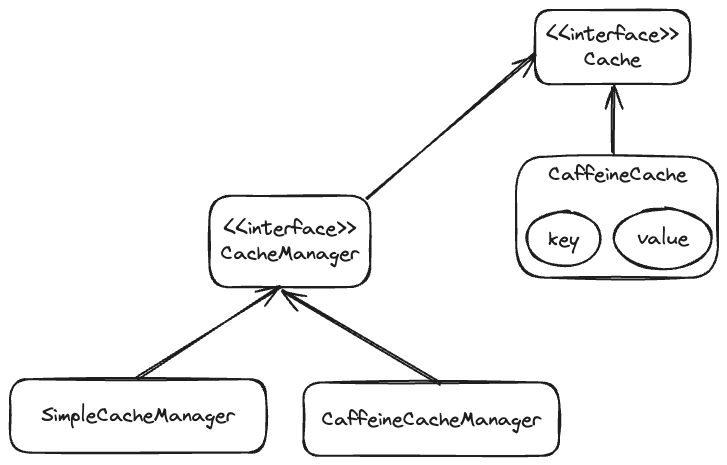
일단 스프링 캐시에서 지원하는 캐시는 여러 종류가 있다.
이 중에서 카페인 캐시 성능이 제일 좋다. 이게 결론.
애초에 카페인 캐시 깃헙에 자기소개로 고성능, 최적 이렇게 설명한다.
Caffeine is a high performance, near optimal caching library. For more details, see our user's guide and browse the API docs for the latest release. - Caffeine Cache Github
스프링 캐시가 지원하는 캐시 매니저 종류
- SimpleCacheManager
- EhCacheManager
- ConcurrentMapCacheManager
- CaffeineCacheManager
- JCacheCacheManager
- CompositeCacheManager
이 중에서 눈여겨 볼 것은 EhCache 와 Caffeine 이다.
EhaCache 의 경우 사용할 수 있는 기능이 많다고, 오래되어서 검증되었다는 장점이 있다.
하지만 Caffeine 캐시가 우리 서버 상황엔 더 맞는다.
이유는 다음과 같다.
- Window TinyLfu Eviction 정책을 사용
- EhCache 의 LRU, LFU 정책 보다 좋은 성능 - EhCache의 분산 캐싱이 필요치 않음
단일 서버 + 성능 우세 = 카페인이 좋겠다
이렇게 사용하게 됐다.
캐시 추상화 왜 씀?
결론부터 말하자면,
- 특정 캐시 라이브러리에 종속적인 프로그램 개발을 방지하기 위해
- 여러 캐시를 사용하는 경우 관리를 편리하게 하기 위해
- 스프링 캐시가 제공하는 어노테이션 기반 캐싱으로 가독성과 생산성을 높이기 위해
카페인 캐시 없이는 동작할 수 없는 서버라면 어떤 문제가 발생할까?
카페인 캐시가 더이상 지원하지 않게 되면 서버 내 모든 캐시를 마이그레이션 해야 한다.
이름도 모르고 얼굴도 모르는 라이브러리 개발자의 갈대같은 마음에 소중한 우리 서버가 취약점을 갖게 된다는 말이다.
캐시 추상화를 적용하면, 우리 서버 내에서 코드를 변경하는 것은 기껏해야 캐시 설정 클래스 정도로 영향 범위가 줄어든다.
만약 카페인 캐시 이외에 다른 캐시를 사용하게 된다면 어떻게 해야할까?
아래서 설명하겠지만, 캐시를 사용하려면 우선 캐시 설정을 해야 한다.
설정 방법은 다양하지만, 캐시 추상화를 사용하지 않는 방법은 캐시를 다양하게 쓸 수 없거나, 엄청난 노가다로 스프링 빈을 하나씩 다 만들어주는 방법 뿐이다.
캐시 추상화를 사용한다면, 내가 원하는 캐시마다 설정을 달리하여 빈으로 등록하고 사용할 수 있다.
스프링 캐시에서는 어노테이션 기반으로 캐시 기능을 제공한다.
스프링 AOP의 장점을 활용할 수 있다는 말이 된다.
AOP는 스프링의 꽃이지 않은가. 적극 활용하자.
🏗️ 구조
스프링 캐시
우선 사용법 부터 알아보는 것이 좋을 것 같다.
@Cacheable
- 어노테이션이 적용된 메소드의 반환값을 캐시에 저장
적용할 메소드에 어노테이션을 붙여줌으로써 사용이 가능하다.
노파심에 말하는데 JPA에서 제공하는 @Cacheable 과는 다른 거다.
캐시에 데이터 없으면 메소드 로직을 실행해 캐시에 넣어주고,
캐시에 데이터가 있으면 메소드 로직을 실행하지 않고 캐시값을 반환한다.
cacheName이라는 속성을 기준(key)로 해서 데이터를 저장한다.
만약 디테일한 키값이 필요하다면 key 속성을 이용할 수 있다.
@Cacheable(cacheNames = CacheType.REFRESH_TOKEN.name())
public AuthToken getRefreshToken(String accessToken)
@Cacheable(cacheNames = CacheType.REFRESH_TOKEN.name(), key = "#root.target + #root.methodName + '_' + #p0")
public AuthToken getRefreshToken(String accessToken)이외에도 다양한 속성 사용이 가능하다
| 속성 | 설명 |
|---|---|
| cacheName | 캐시 이름 |
| value | 캐시 이름 별명 |
| key | SpEL 동적 표현식 키 |
| condition | SpEL 표현식이 참인 경우 캐싱 적용 |
| unless | SpEL 표현식이 참인 경우 캐싱 미적용 |
| cacheManager | 캐시 매니저 지정 |
| sync | 동기화 기능 설정 |
@CacheEvict
- 캐시값 제거
@CacheEvict(key = "key")
public String removeToken(String token)| 속성 | 설명 |
|---|---|
| cacheName | 캐시 이름 |
| value | 캐시 이름 별명 |
| key | 키 값 |
| allEntries | 캐시 내 모든 값 제거 |
| cacheManager | 캐시 매니저 지정 |
| beforeInvocation | 캐시값 제거 시점 (true = 메소드 실행 전 제거) |
@CachePut
- 캐시 값 저장만 하는 용도
- 캐시 값 읽지 못함
다시 말해서 캐시에 값이 있던 없던 메소드의 로직은 실행되고, 캐시 값은 갱신된다는 말이다.
@CachePut(key="key")
public String refreshToken(String token)@Caching
- 하나의 메소드에서 여러 캐싱 동작을 수행토록 함
@Caching(
put = {@CachePut(key="put")},
evict = {@CacheEvict(key="evict")})
public String doSomething(String something)@CacheConfig
- 클래스 단위 캐싱 설정
캐시는 클래스 레벨이 아니라 메소드 레벨에 어노테이션을 붙이고 사용한다.
클래스 레벨에 붙이면 캐싱이 적용되지 않는 문제가 발생하기 때문.
이 어노테이션은 클래스 레벨에 캐싱 기능을 붙여주는 것이 아니라, 단순히 해당 클래스에서 사용되는 모든 메소드 레벨 캐시의 설정을 모아주는 역할을 한다.
@CacheConfig(cacheNames={CacheType.REFRESH_TOKEN, CacheType.LOGOUT_TOKEN})
public class CacheService {
...
}카페인 캐시
캐시 추상 객체를 상속받고 있으므로, 사실상 코드 차이는 없다.
🧳 준비물
Gradle 의존성
Spring Cache
// Spring Boot Cache (2024.01.11 기준)
implementation 'org.springframework.boot:spring-boot-starter-cache:3.2.1'Caffeine Cache
// Caffeine Cache (2024.01.11 기준)
implementation 'com.github.ben-manes.caffeine:caffeine:3.1.8'캐시 설정
공통
@EnableCaching 어노테이션을 설정 클래스에 추가해야, @Cacheable 같은 어노테이션 기반 캐시 기능을 쓸 수 있다.
@EnableCaching
@Configuration
public class CacheConfiguration {
...
}설정 가능한 속성
| property | description |
|---|---|
| initialCapacity | 내부 해시 테이블 크기 |
| maximumSize | 최대 엔트리 수 |
| maximumWeight | 엔트리 원소 최대 크기 |
| expireAfterAccess | 캐시 값에 가장 최근 접근한 후 설정한 시간 후에 해당 값 제거 |
| refreshAfterWrite | 캐시 값 갱신 후 설정 시간 후에 해당 값 제거 |
| recordStats | 캐시 통계 적용 |
설정 파일로 하는 방법
YAML 이나 properties 파일로 설정하는 방법.
간단하게 설정이 가능하지만, 캐시 별로 개별 설정이 불가하다는 점이 단점이다.
spring:
cache:
caffeine:
spec: maximumSize=1000,expireAfterWrite=1000s
type: caffeine
cache-names:
- users
- books설정 클래스로 하는 방법
캐시 스프링 빈을 만들고, 해당 빈을 통해 스프링 캐시 매니저를 등록한 코드다.
캐시 생성은 세 가지로 생성 가능하다.
- Cache : 엔티리 자동 로드 캐시
- LoadingCache : 동기 방식 캐시
- AsyncLoadingCache : 비동기 방식 캐시
@EnableCaching
@Configuration
public class CacheConfig {
@Bean
public Caffeine caffeineConfig() {
return Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.DAYS);
.maximumSize(10_000)
}
// 캐시 추상화가 필요없다면 이 Bean 은 필요 없다.
// 위에 있는 Caffeine 빈을 그대로 사용하면 된다.
@Bean
public CacheManager cacheManager(Caffeine caffeine) {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(caffeine);
return cacheManager;
}
}여러 캐시 사용할 때 설정 클래스
이렇게 하면 캐시마다 설정을 달리해서 적용할 수 있다.
Enum 클래스를 사용한 이유
빈 등록은 프로그램 시작 시 정적으로 로드되므로 캐시 타입 또한 스프링 빈이거나 static 이어야 한다.
각자 정보를 가지고 있으면서 static 한 클래스로 딱 Enum이 생각났다.
또, 캐시 매니저에 캐시를 등록할 때 등록할 모든 캐시 컬렉션 혹은 배열을 쉽게 사용할 수 있는 것이 Enum 클래스이기 때문에 채용했다. (Enum.values() 사용할 예정이란 소리)
스프링 캐시 AOP 를 사용할 때 cacheNames 속성에 문자열 말고 Enum 을 사용할 수 있다는 것도 아주 큰 장점이다.
@Getter
public enum CaffeineCacheType {
REFRESH_TOKEN("refreshTokenCache", 30),
LOGOUT_TOKEN("logoutTokenCache", 1);
private static final int MAXIMUM_CACHE_SIZE = 10000;
private final String cacheName;
private final int expireAfterWrite;
private final int maximumSize;
CaffeineCacheType(String cacheName, int expireAfterWrite) {
this.cacheName = cacheName;
this.expireAfterWrite = expireAfterWrite;
this.maximumSize = MAXIMUM_CACHE_SIZE;
}
}SimpleCacheManager 를 사용했다.
앞서 스프링 캐시에서 제공하는 여러 캐시 매니저 중 하나다.
사용자가 캐시 설정을 하고 사용할 수 있도록 지원하는 역할을 한다.
@EnableCaching
@Configuration
public class CaffeineCacheConfig {
@Bean
public CacheManager cacheManager() {
SimpleCacheManager cacheManager = new SimpleCacheManager();
List<CaffeineCache> caches = Arrays.stream(CaffeineCacheType.values())
.map(caffeineCacheType -> new CaffeineCache(
caffeineCacheType.getCacheName(),
Caffeine.newBuilder()
.expireAfterWrite(caffeineCacheType.getExpireAfterWrite(), TimeUnit.DAYS)
.maximumSize(caffeineCacheType.getMaximumSize())
.build()
))
.toList();
cacheManager.setCaches(caches);
return cacheManager;
}
}🔑 결론
REDIS 써보고 싶은 마음에 써보다가 실효성을 근거로 로컬 캐시를 적용해봤다.
현재 필요한 것이 무엇인지, 왜 필요한지, 어떻게 적용할지를 알아보면서 앞으로 캐시를 유용하게 쓸 수 있을 것 같다는 생각이 들었다.
다음 리팩토링 때는 캐시를 이용해서 성능 개선을 시도해볼 생각이다.
[[JWT 토큰 관리]]에 대해서 좀 더 고찰한 내용이 있으니 참고
🔗 참조
Spring Caching Guide
Baeldung - Spring Cache
Caffeine Cache
TStory - Spring Cache
