🎯 사건의 발단
지난번엔 서버에서 발생할 동시성 문제를 해결해봤다.
정합성 때문에 깎아먹은 서버 성능을 높이고자 방법을 찾아봤다.
그리고 두 가지를 찾아내었다.
- ETag 적용해서 응답 패킷 줄여보기
- Cache 적용해서 응답 시간 줄여보기
후술 하겠지만 두 방법의 목적과 방식이 다르다.
하지만 두 방식 모두 아래와 같은 조건에서 빛을 발한다.
- 같은 응답이 자주 발생할 것으로 보이는 요청
- 매우 큰 응답이 자주 발생할 것으로 보이는 요청
- 쉽게 변하지는 않는 요청
따라서 내 프로젝트에서 적용할 대상도 정해두었다.
| ETAG | CACHE | |
|---|---|---|
| 적용대상 | 멤버 프로필 조회 도서 정보 조회 서평 조회 | 추천 멤버 조회 금주도서 조회 서평 피드 조회 (최신순 / 베스트순) 북픽 여부 조회 서평픽 여부 조회 팔로우 여부 조회 |
적용하기 전 둘이 무엇인지 부터 알아보고 가자.
🔍 톺아보기
두 방법의 차이는?
둘의 목적부터가 다르다.
ETag 는 응답의 크기를 줄이는 것이고, Cache 는 응답의 시간을 줄이는거다.
하지만 둘다 결국엔 더 깊은 인프라까지 접근하지 않고, 보다 얕은 깊이에서 응답을 반환하고자 한다는 점에서 공통점이 있다.
그리고 그 결과가 응답시간을 줄여주어 서버 성능 개선에 효과가 있다는 거다.
그리고 필연적으로 최초 요청인 경우인 경우에는 성능 개선 효과가 전혀없다.
무조건 선행 요청이 존재해야만 성능 개선이 가능한 수동적인 개선 방법이다.
능동적인 개선 방법으로 비동기 처리나, 쿼리 성능 개선 혹은 멀티 스레드 개발 등이 있다고 한다.
그런 능동적인 개선은 어디부터 시작할지 아직 정하지 못해서 Etag, Cache 로 먼저 기반을 만들어보고자 한다.
ETag 가 뭐임?
ETag HTTP 응답 헤더는 특정 버전의 리소스를 식별하는 식별자입니다. 웹 서버가 내용을 확인하고 변하지 않았으면, 웹 서버로 full 요청을 보내지 않기 때문에, 캐쉬가 더 효율적이게 되고, 대역폭도 아낄 수 있습니다. 허나, 만약 내용이 변경되었다면, "mid-air collisions" 이라는 리소스 간의 동시 다발적 수정 및 덮어쓰기 현상을 막는데 유용하게 사용됩니다.
만약 특정 URL 의 리소스가 변경된다면, 새로운 ETag 가 생성됩니다. ETag 는 지문과 같은 역할을 하면서 다른 서버들이 추적하는 용도에 이용되기도 합니다. ETag 를 비교하여 리소스가 서로 같은지의 여부를 빠르게 판단할 수 있지만, 서버에서 무기한으로 지속될 수 있도록 설정할 수도 있습니다.
요약하자면,
- HTTP 응답 헤더 중 하나
- 버저닝으로 리소스 식별하는 식별자
- 리소스 변경 시 새로운 ETag 생성
- E(ntity) Tag
작동 방식은 아래 그림과 같다.
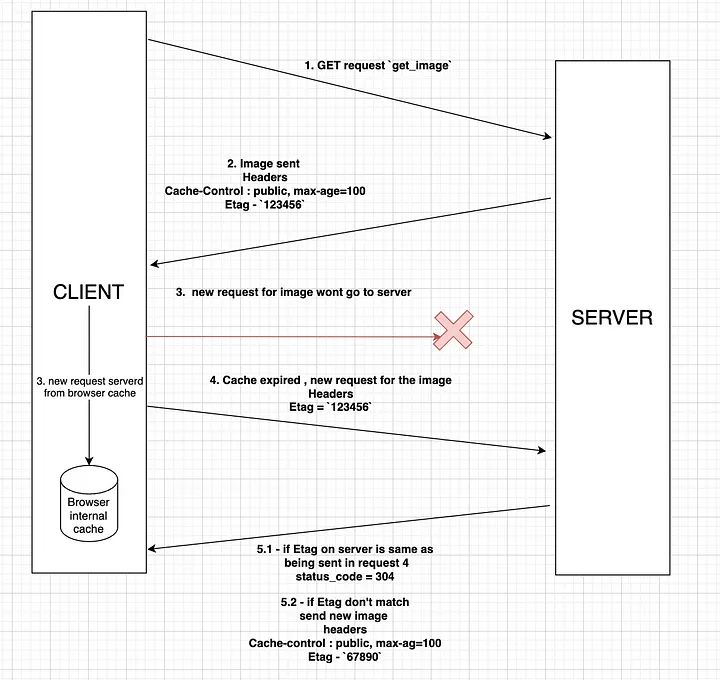
- 평범하게 요청을 보낸다.
- 응답에 ETag 값을 넣어서 보낸다.
- 클라이언트에서는 브라우저 내장 캐시에 해당 자원을 넣어놓는다.
- 캐시가 만료되면 요청 헤더(If-None-Match)에 Etag 값을 넣어서 다시 요청한다.
- Etag 활용
- 해당 태그값이 서버와 일치하면 304(Not Modified) 응답을 보내 자원이 변경되지 않았음을 알린다.
- 해당 태그값이 서버와 불치하면 요청을 수행하고 응답에 새로운 태그값을 넣어서 보낸다.
따라서 클라이언트 쪽에서는 캐시를 보다 적극적으로 활용할 수 있는 여지가 있고,
서버 쪽에서는 이미 클라쪽에서 가지고 있을 큰 용량의 데이터를 보내지 않아도 되는 것이다.
추가적으로 ETag 는 리소스에 대한 해시값이므로 굳이 요청 전부를 처리하지 않고, 응답을 보낼 수 있다는 장점도 있다.
Cache 가 뭐임?
캐시(cache, 문화어: 캐쉬, 고속완충기, 고속완충기억기)는 컴퓨터 과학에서 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 캐시는 캐시의 접근 시간에 비해 미가공 데이터 또는 1차 데이터(raw data or primary data)에 접근하는 시간이 오래 걸리는 경우나 값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용한다. 캐시에 데이터를 미리 복사해 놓으면 계산이나 접근 시간없이 더 빠른 속도로 데이터에 접근할 수 있다.
하위 기억장치 (CPU 입장에서는 메모리 / 메모리 입장에서는 HDD) 에서 데이터를 가져오지 않고, hit 율이 높은 데이터를 최대한 가까이에 두는 것을 말한다.
ETag 에 비해 장단점이 꽤나 명확하다.
| 장점 | 단점 |
|---|---|
| 기억장치 간 병목, 매핑 등에 영향 받지 않음 | |
| hit 율이 높은 경우 처리율이 비약적 | hit 율이 낮은 경우 추가 오버헤드가 발생함 |
- 캐시 메모리에 원하는 정보가 없다면
- 하위 기억장치에서 데이터를 얻어야 함
- 얻은 데이터를 캐시에 저장해야함
- 만약 캐시 데이터가 가득 찼으면 비워줘야함 - 캐시 메모리에 원하는 정보가 있다면
- 나와라 뚝딱
Hit Ratio 와 지역성
앞서 설명에서 알 수 있듯이 캐시에서 가장 중요한 것은 바로 HIT율이다.
찾고자 하는 데이터가 캐시 메모리에 얼마나 있었는가에 대한 지표다.
히트율을 높이기 위한 알고리즘은 지역성이라는 개념을 근본으로 한다.
시간적 지역성
데이터에 1회 접근했을때, 얼마 후 다시 접근할 가능성이 높은 것을 말한다.
캐시 메모리에서 비슷한 주소를 활용할 수 있다면 적은 크기의 캐시로도 충분히 성능 개선이 가능하다.
공간적 지역성
데이터를 접근하는 주소가 서로 가까운지를 나타내는 말이다.
하위 기억장치에서 메모리로 데이터를 로드할 때 블락 단위로 데이터를 가져온다.
뭉텅이로 데이터를 가져온다는 뜻이다. 원하는 데이터는 그 중 하나일 뿐.
따라서 메모리 주소를 정렬해두고 차례대로 조회한다면, 캐시에 저장된 같은 블록 데이터에 접근하게 되므로 효율이 좋아진다.
WTinyLfu 알고리즘
후술할 생각이었는데, 내가 사용한 캐시는 카페인 캐시다.
w-tiny-lfu 알고리즘은 카페인 캐시에서 사용하는 알고리즘이다.
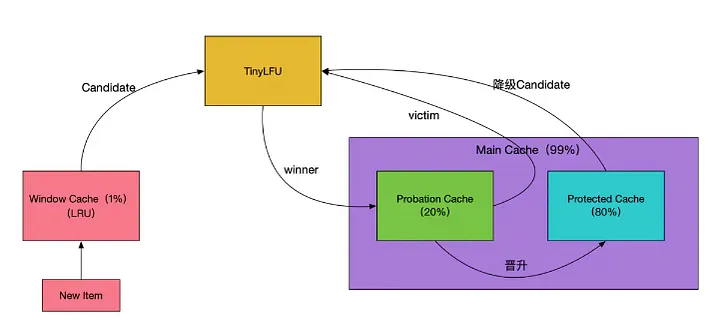
전체 용량의 대부분을 차지하는 Main Cache 영역에서는 SLRU(Segmented Least Recently Used) 알고리즘을 활용해서 eviction을 수행하고,
작은 영역의 Window Cache 에서는 LRU(Least Recently Used) 알고리즘을 사용해서 맨 처음 캐시에 들어오는 데이터를 미리 쳐내는 것을 말한다.
또한 계속해서 자주 사용되는(히트) 데이터의 경우 Protected Cache 에 두게 되므로 LFU (Least Frequently Used) 알고리즘도 사용한다.
정리하자면, LRU + LFU = 행복
이 알고리즘을 기반으로 카페인 캐시는 이외 벤더보다 캐시 READ/WRITE 에서 압도적인 성능을 갖는다고 한다.
📺 진행과정
ETag 적용
아-주 쉽다.
방식은 크게 두가지로 나뉜다.
- 아묻따 ETag 전체 적용
- 원하는 API 에만 소급 적용
코드
설정 클래스를 추가해준다.
- 전체 적용
package com.onetuks.libraryapi.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.filter.ShallowEtagHeaderFilter;
@Configuration
public class EtagConfig {
@Bean
public ShallowEtagHeaderFilter shallowEtagHeaderFilter() {
return new ShallowEtagHeaderFilter();
}
}- 소급 적용
package com.onetuks.libraryapi.config;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.filter.ShallowEtagHeaderFilter;
@Configuration
public class EtagConfig {
@Bean
public FilterRegistrationBean<ShallowEtagHeaderFilter> shallowEtagHeaderFilters() {
FilterRegistrationBean<ShallowEtagHeaderFilter> filterRegistration
= new FilterRegistrationBean<>(new ShallowEtagHeaderFilter());
filterRegistration.addUrlPatterns("/{적용대상URI}");
return filterRegistration;
}
}이름부터 Filter 클래스다.
코드를 디컴파일해보면 상속자가 OncePerRequestFilter로 되어있다.
필터는 스프링 프레임워크가 아니라 톰캣 같은 WAS 의 서블릿 내에 존재한다.
따라서 스프링의 DispatcherServlet 에 통과하기 전에 이미 필터를 통해 ETag를 적용할지를 정하고 들어온다는 것.
실제로 코드를 보면 HTTP 요청에서 Etag 라는 헤더 속성을 파싱하여 검증하는 로직과 새로 갱신해주는 로직이 있다.
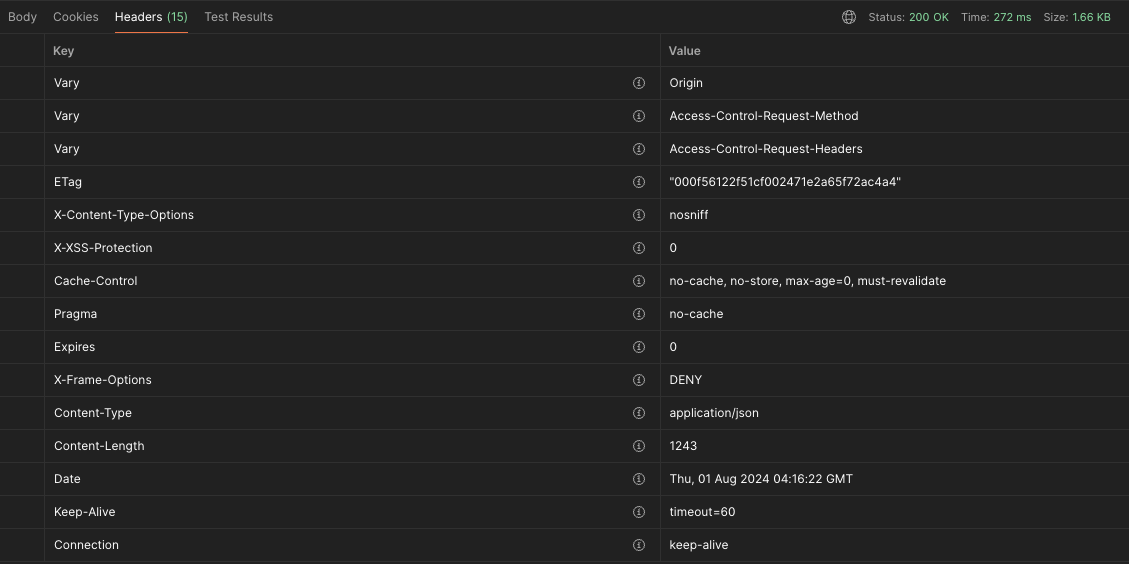
결과 비교
-
최초 요청
- 응답 헤더에 ETag 가 있다.
- 패킷 크기는 1.66KB
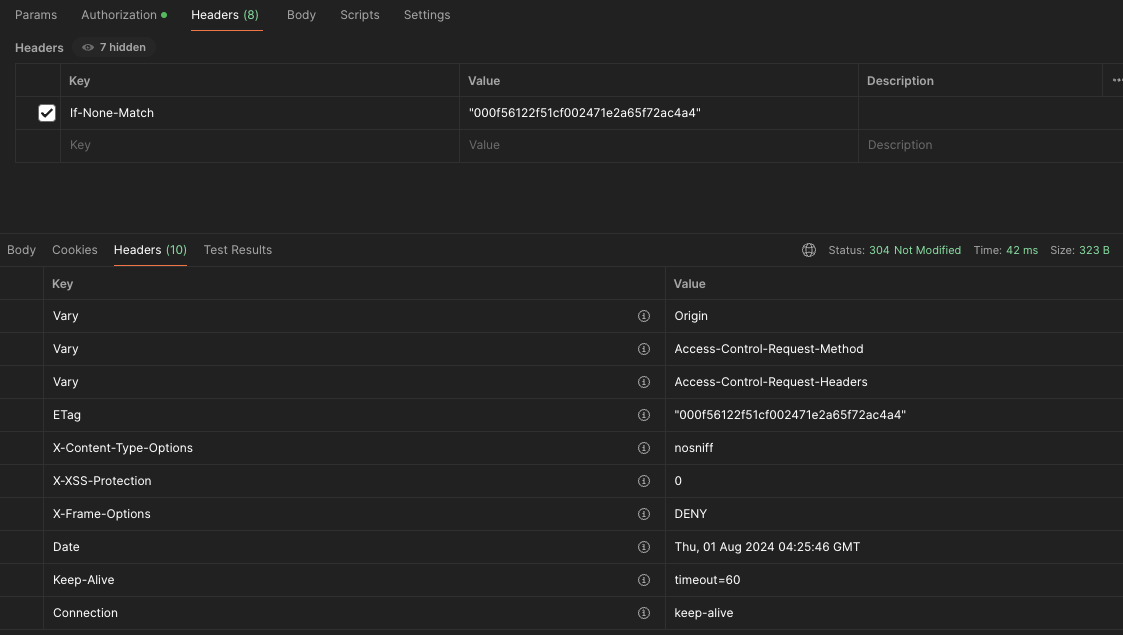
-
ETag 적용 요청
- 요청 헤더에 If-None-Match 속성에 저번 응답의 ETag 값을 넣어주었다.
- 리소스가 변하지 않았으므로 응답의 ETag 값도 변경되지 않았다.
- 응답 상태코드가 304(Not Modified) 로 온다.
- 응답 패킷 크기가 323B 다!
Cache 적용
필요 라이브러리
캐시 벤더의 라이브러리만 임포트해도 되는데, 스프링에서는 캐시 추상화를 위해서 라이브러리를 제공한다.
캐시 추상화가 왜 좋은지에 대해서는 이전 포스팅을 가져왔다. 링크
코드
// Spring Cache
implementation('org.springframework.boot:spring-boot-starter-cache')
// Caffeine Cache
implementation("com.github.ben-manes.caffeine:caffeine:3.1.8")이것저것 적용했는데 가독성을 위해서 예제 하나만 가져왔다.
// 금주도서 선정 메소드
@Caching(
evict = @CacheEvict(value = CacheName.WEEKLY_FEATURED_BOOKS, key = FEATURED_BOOKS_CACHE_KEY),
put = @CachePut(value = CacheName.WEEKLY_FEATURED_BOOKS, key = FEATURED_BOOKS_CACHE_KEY))
@Scheduled(cron = "0 0 0 * * MON")
@Transactional
public void registerAll() {
List<WeeklyFeaturedBook> allWeeklyFeaturedBooks = weeklyFeaturedBookRepository.readAll();
List<Book> featuredBooks =
bookRepository.readAllNotIn(
allWeeklyFeaturedBooks.stream().map(WeeklyFeaturedBook::book).toList());
featuredBooks.forEach(book -> weeklyFeaturedBookRepository.create(WeeklyFeaturedBook.of(book)));
log.info("[도서] 금주도서 선정 - featuredBooks: {}", featuredBooks.toArray());
}
// 금주도서 조회 메소드
@Cacheable(value = CacheName.WEEKLY_FEATURED_BOOKS, key = FEATURED_BOOKS_CACHE_KEY)
@Transactional(readOnly = true)
public Page<Book> searchAllForThisWeek() {
return weeklyFeaturedBookRepository.readAllForThisWeek().map(WeeklyFeaturedBook::book);
} - 매주 월요일 자정 금주도서 선정
- 동시에 기존 캐시 evict
- evict 후, 새로 만들어진 금주도서로 캐시 Put
- 금주도서 조회 시 캐시에 해당 key 에 대한 값이 있으면 Cache Hit
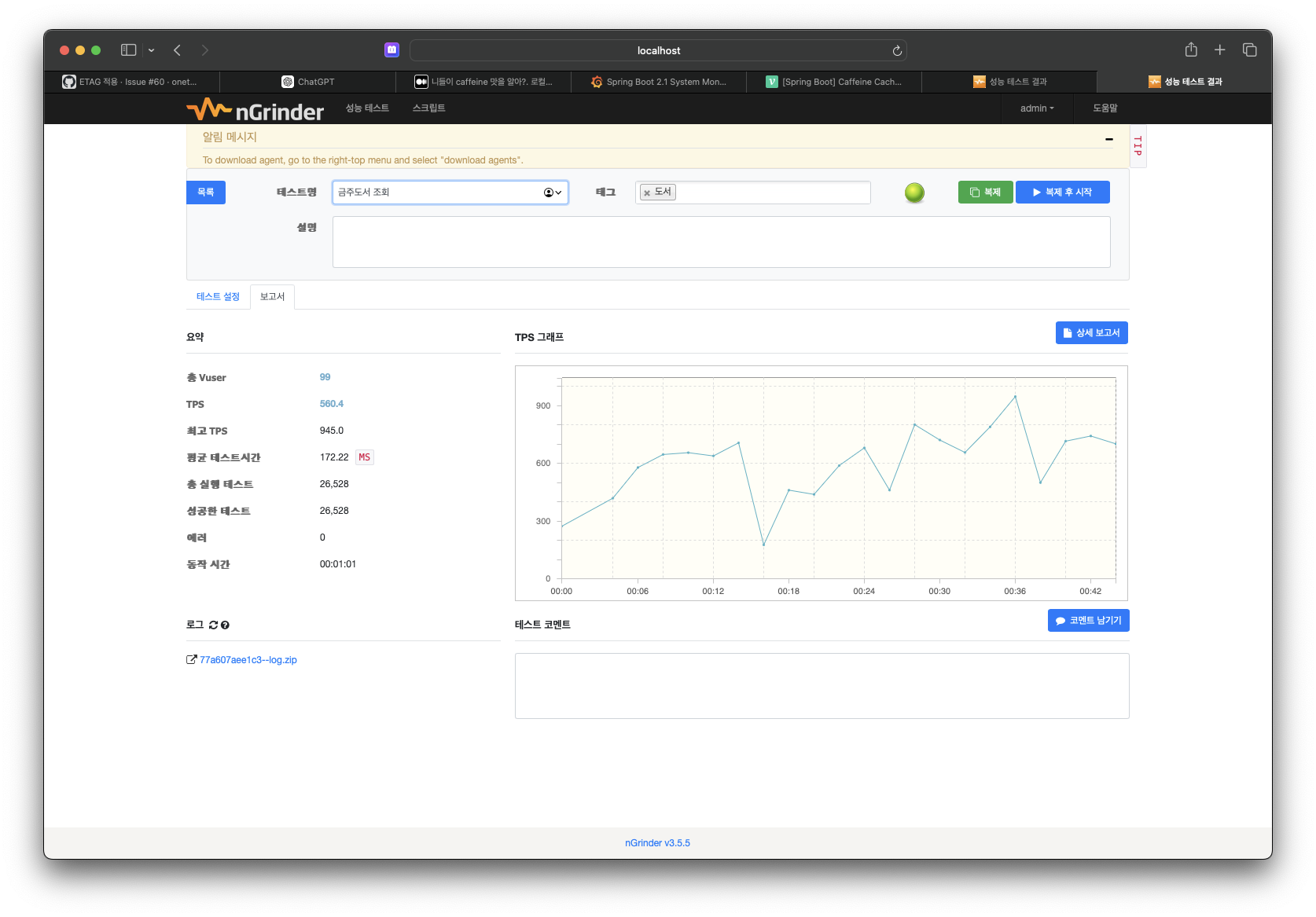
결과 비교
- 캐시 적용 전
- 캐시 적용 후
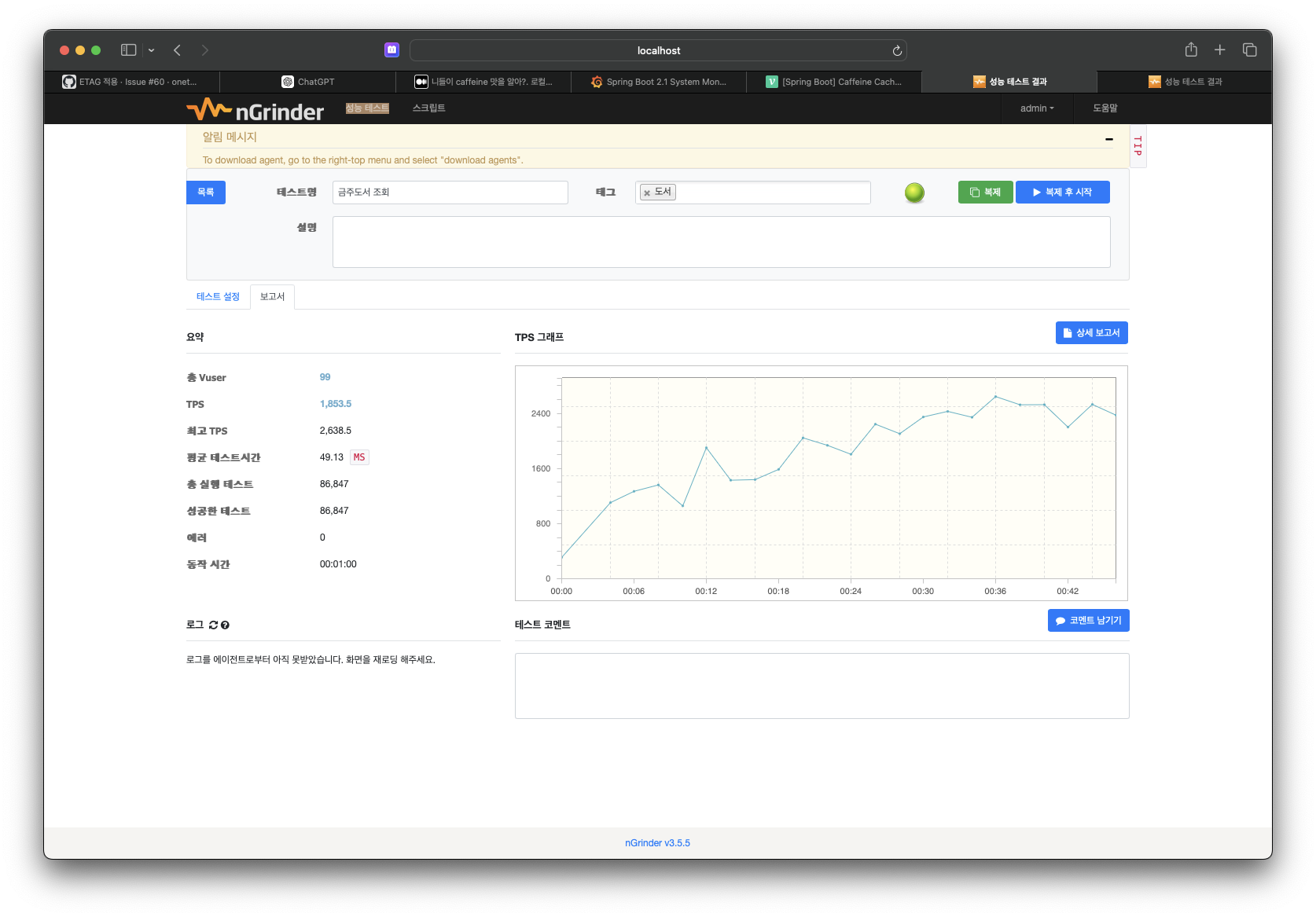
다른 API 는?
위에서 말한 적용대상에 대해서 모두 nGrinder 로 확인을 해봤다.
Postman 은 자체적으로 캐시를 활용하고 있는것인지, 캐시 적용을 하지 않아도 응답 속도가 빨라져서 테스트 자료로는 활용하지 못했다.
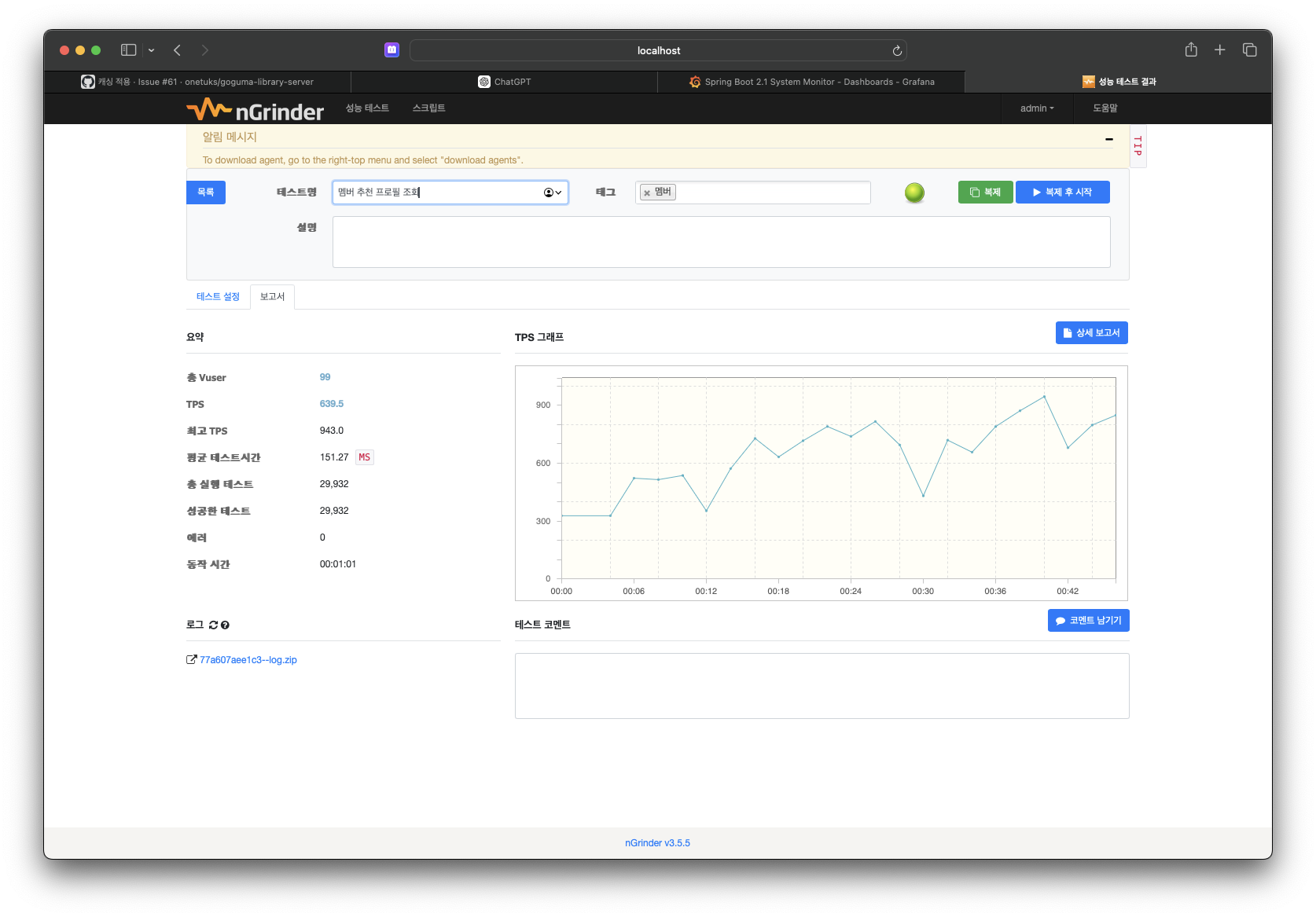
적용한 API 중 추천 멤버 프로필 조회 기능에서 위와 마찬가지로 성능 개선이 잘 된 것을 확인했다.
- 캐시 적용 전
- 캐시 적용 후
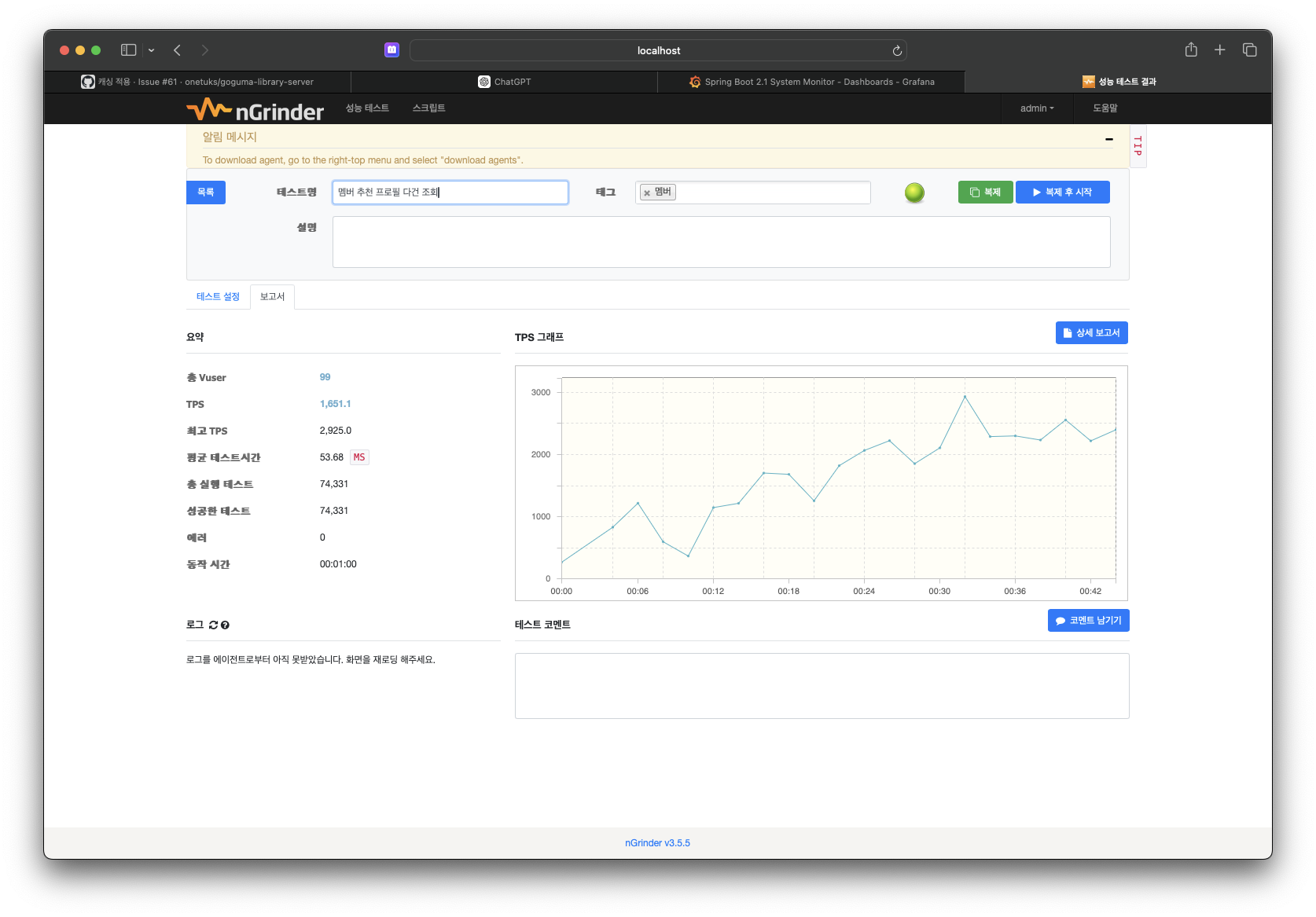
🔑 결론
성능 개선을 위해서 이것저것 활용해보았다.
nGrinder 로 테스트하면서 성능 개선 대상을 정했는데,
실제로 사용하는 데이터도 아니고 트래픽이 있는 것도 아니라서, 목표 설정이 어려웠다.
'그래도 한 번 해보자' 라는 생각으로 ETag 와 Cache 부터 적용해봤는데 효과가 있던 것 같아서 다행이다.
결과 화면으로 보여준 금주도서 조회, 추천 멤버 프로필 조회, 서평 피드 조회 기능의 경우
모든 멤버가 하나의 결과를 보는 것이기 때문에 캐시 적용과 ETag 적용에 고민이 없었다.
다만, 북픽/서평픽/팔로우의 경우 자주 엑세스 되는 정보라고 생각해 캐싱했으나 실제로 효과가 있으지는 모르겠다.
테스트 결과로는 성능개선이 이뤄졌는데, 실제로 유저들이 그 기능을 잘 안 쓴다면 그냥 오버헤드만 늘어나는 거니까..
출시 이후에 실제로 QA 해보면서 뺄지 유지할지 정해야 할 것 같다.
