이미지를 보고 특징적인 edge등을 찾아서 라이브러리화하는 등의 노력을 통해 다른 이미지가 들어왔을 때 전반적인 상태를 비교하여 classifier하려고 함.
Data-driven approach
- 이미지와 레이블을 가진 데이터셋을 모은다.
- 머신러닝을 통해 image classifier을 학습한다.
- test 이미지셋을 통해 classifier를 평가한다.
1. Nearest Neighbor Classifier
모든 training 데이터의 이미지와 레이블을 메모리에 저장한다.
예측 시 저장된 모든 데이터와 하나하나 비교하여 가장 근접한 것으로 예측한다.
L1 distance:
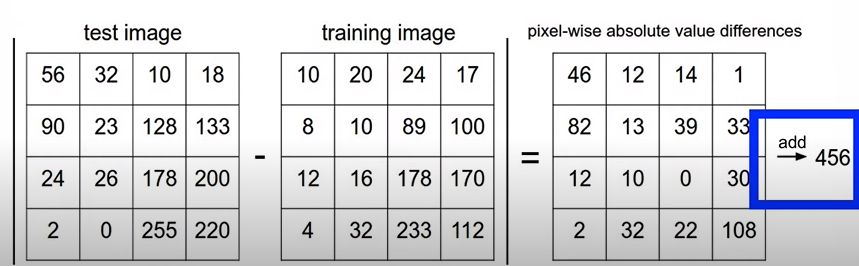
L1 distance를 계산하여 가장 작은 training image를 찾아 test image의 레이블을 예측한다.
- training image가 증가할수록 linear하게 시간도 증가한다.
보통 test time이 practice보다 중요하지만 CNN에서는 training시에는 매우 오래걸리지만 test시에는 매어 적은 (일정한) 시간이 소요된다.
distance를 계산하는 식은 hyper-param
K-nearest neighbor을 통해 더 부드럽고 성능이 좋게할 수 있다.
어떤 distance, k값 등 hyperparameter을 어떻게 설정하는가?
주어진 환경에서 각가의 params를 시험해보고 성능이 잘나오는 것을 선택한다.
이를 위해 validation data를 마련.
Training data가 적은경우 Cross-validation을 사용.
k-NN on images never used.
- test시 terrible performance
- distance metrics on level of whole images can be very unintuitive
Linear Classification
Parametric approach
f: 10x1
W: 10x3072
x: 3072x1
로 가중치의 행렬을 정의할 수 있다.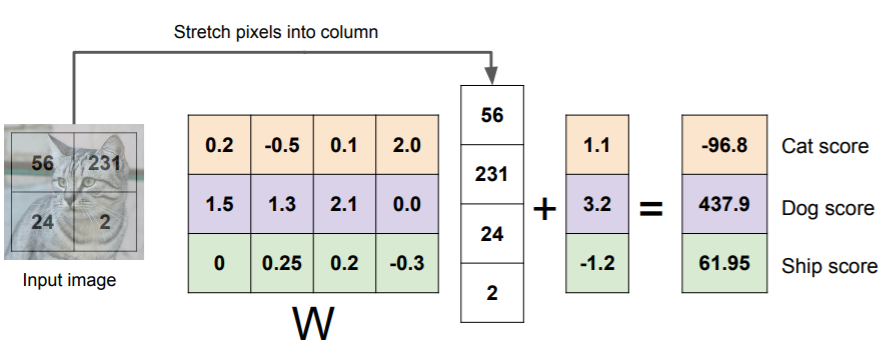
Linear classifier은 가중치들의 행렬곱의 합, 그리고 색상이 중요한 역할을 한다.
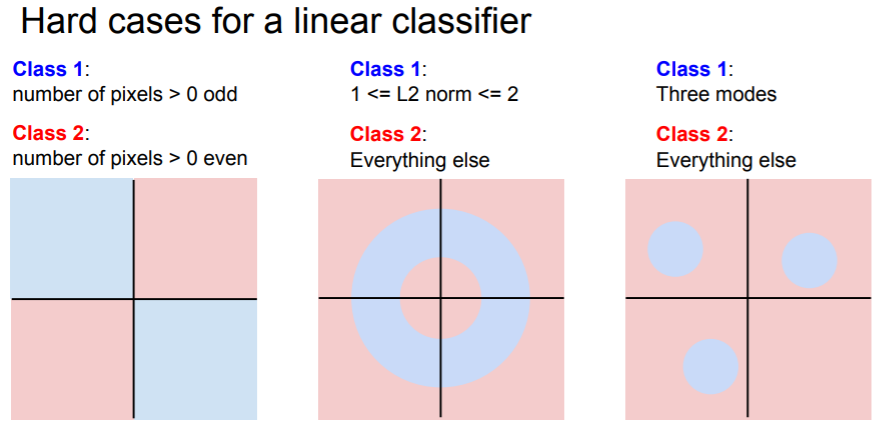
Linear classifier가 분간하기 힘든 클래스는 어떤 것일까?